










HyperLoRA 简介
今天文章将介绍一款由字节跳动最新开源的自适应一致性方案:HyperLoRA ,该框架目标是在通过参数高效的自适应生成方法,解决人物一致性肖像合成中的挑战。
基于模型微调的方法(如 LoRA 和 DreamBooth)可以生成逼真的输出,但需要对个体样本进行训练,耗时且资源密集,还存在不稳定的风险。基于适配器技术(如 IP-Adapter)通过冻结基础模型参数并采用插件架构实现零样本推理,但往往缺乏自然性和真实性。 HyperLoRA则是字节提出来的一种参数高效的自适应生成方法,它使用自适应插件网络生成 LoRA 权重,将 LoRA 的优越性能与适配器方案的零样本能力相结合。通过精心设计的网络结构和训练策略,HyperLoRA实现了零样本个性化肖像生成(支持单张和多张图像输入),具有高逼真度、保真度和可编辑性。
架构方法
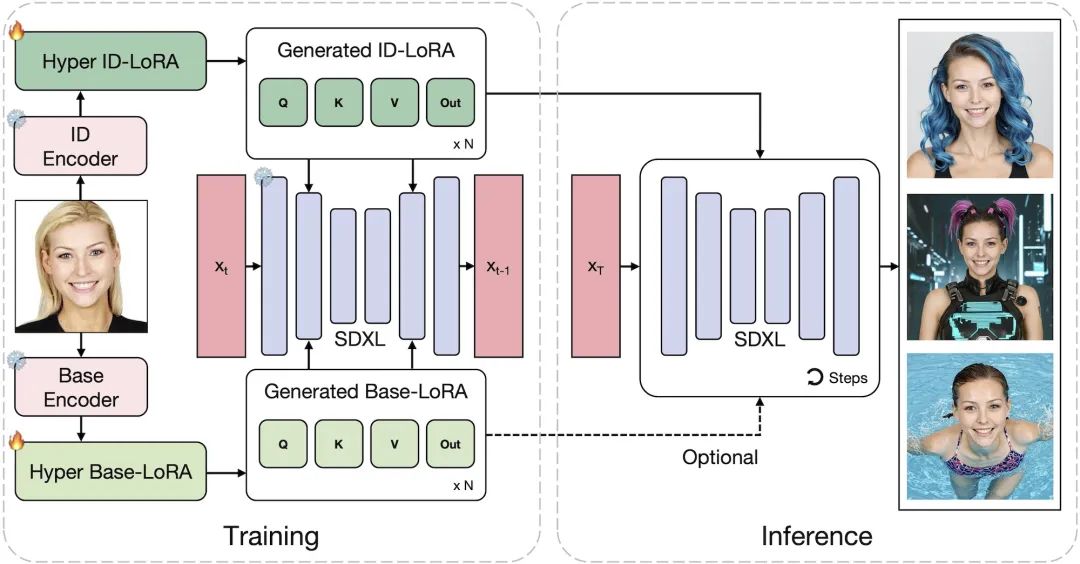
研发团队明确将 HyperLoRA 分解为 Hyper ID-LoRA 和 Hyper Base-LoRA。前者是在学习身份信息,而后者则用于拟合其他内容(如背景和服装)。这种设计有助于防止无关特征泄露到 ID-LoRA。在训练过程中,采用了固定预训练的 SDXL 基础模型和编码器的权重,仅通过反向传播更新 HyperLoRA 模块。在推理阶段,集成到 SDXL 中的 Hyper ID-LoRA 生成个性化图像,而 Hyper Base-LoRA 是可选的。
HyperLoRA一致性ComfyUI体验
本文使用ComfyUI-HyperLoRA插件体验。模型文末网盘获取。
- • ComfyUI-HyperLoRA:https://github.com/bytedance/ComfyUI-HyperLoRA
- • clip_vit_large_14_processor模型下载:下载 CLIP模型到
models/hyper_lora/clip_processor/clip_vit_large_14_processor。下载:https://huggingface.co/openai/clip-vit-large-patch14/ - • clip_vit_large_14模型:下载 CLIP ViT 模型和配置到
models/hyper_lora/clip_vit/clip_vit_large_14。下载:https://huggingface.co/openai/clip-vit-large-patch14 - • antelopev2模型:下载 antelopev2 并解压到
models/insightface/models。下载:https://github.com/deepinsight/insightface/tree/master/python-package#model-zoo - • HyperLoRA模型:下载 HyperLoRA 模型到
models/hyper_lora/hyper_lora。下载:https://huggingface.co/bytedance-research/HyperLoRA - • 模型放置目录结构如下:
models/
├── hyper_lora/
│ ├── clip_processor/ # CLIP 处理器文件目录
│ ├── clip_vit/ # CLIP ViT 模型文件目录
│ └── hyper_lora/ # HyperLoRA 模型文件目录
└── insightface/
└── models/ # InsightFace 模型文件目录
HyperLoRA一致性ComfyUI工作流
HyperLoRA一致性ComfyUI工作流下载地址:
• **RunningHUB体验-**字节HyperLoRA一致性(文生图+面部细化+Pose控制) :https://www.runninghub.cn/ai-detail/1916118882107723778/?inviteCode=kol01-rh059
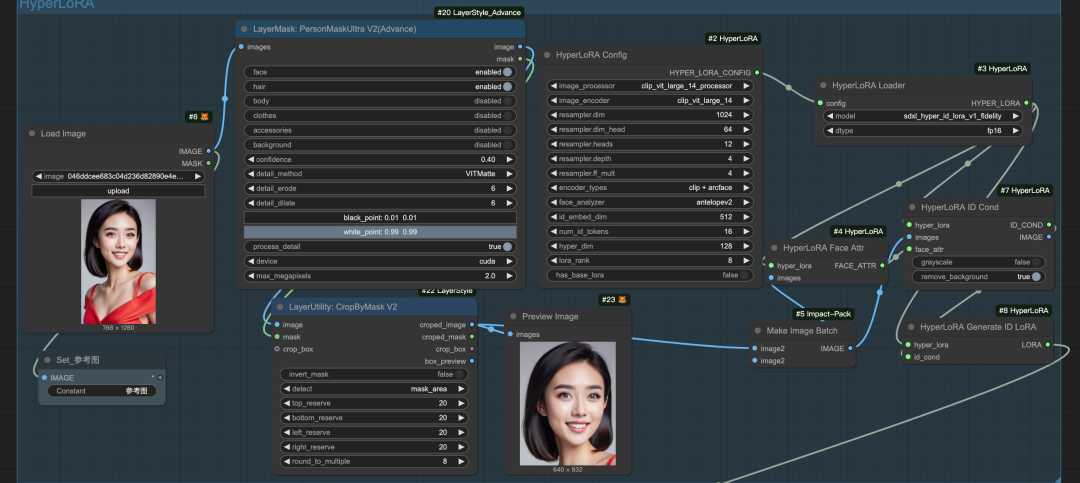
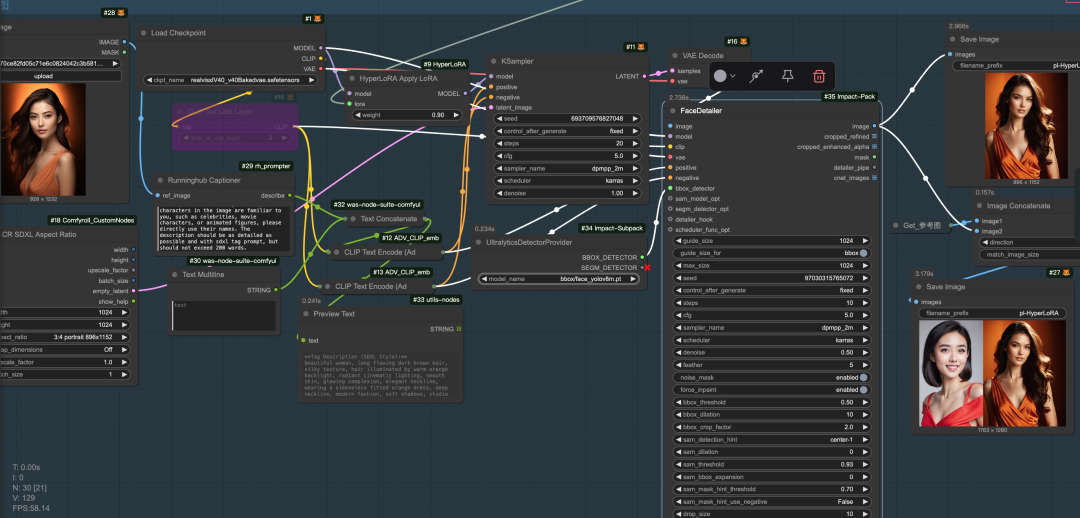
• **RunningHUB体验-字节HyperLoRA+InstantID增强一致性 :https://www.runninghub.cn/ai-detail/1916133083668746242/?inviteCode=kol01-rh059
**
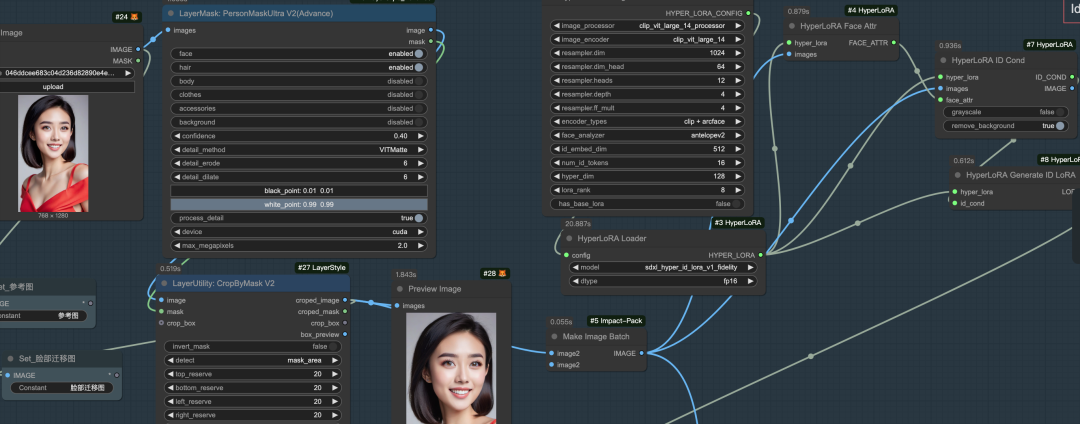
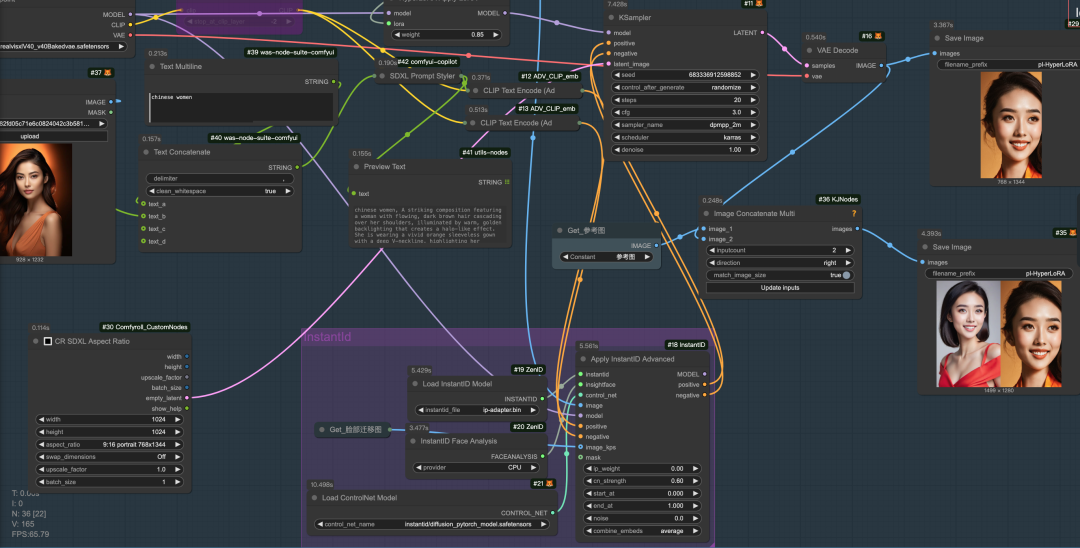
注意:
• HyperLoRA包含两个版本,分别为: sdxl_hyper_id_lora_v1_fidelity:提供更好的保真度。 sdxl_hyper_id_lora_v1_edit:提供更好的可编辑性。
• 研发团队提供了4类工作流(已放置文末网盘),分别为:文生图、文生图+面部细节优化、文生图+CN姿势控制、文生图+InstantID增强相似度。笔者在RunningHUB采用的是合并改进后的工作流。
• 兼容性:HyperLoRA并不兼容所有 SDXL 基础模型。研发团队称与LEOSAM 的 HelloWorld XL 3.0、CyberRealistic XL v1.1 和 RealVisXL v4.0 兼容,但与 ArienMixXL v4.0 不兼容。并且推荐采用RealVisXL v4.0可以获得最佳结果。
• LoRA 权重:通常在 0.75 到 0.85 之间。如果提示非常长,可以适当增加权重(以及触发词的权重)。如果需要更好的可编辑性,可以适当降低权重。
• 分辨率限制:由于训练的面部分辨率有限,建议使用 FaceDetailer 插件修复小面部,或使用 ControlNet 提高稳定性。
• 另外,HyperLoRA还支持与 InstantID结合可以进一步提高面部相似度。
01.未启用面部细化-写真
beautiful woman, long flowing dark brown hair, silky texture, hair illuminated by warm orange backlight, radiant cinematic lighting, smooth skin, glowing complexion, elegant neckline, wearing a sleeveless fitted orange dress, deep neckline, modern fashion, soft shadows, studio photography, dramatic warm atmosphere, high contrast, meticulously styled hair, sophisticated style, high-definition image, fashion portrait, golden hues, artistic photography.

02.启用面部细化-写真
beautiful woman, long flowing dark brown hair, silky texture, hair illuminated by warm orange backlight, radiant cinematic lighting, smooth skin, glowing complexion, elegant neckline, wearing a sleeveless fitted orange dress, deep neckline, modern fashion, soft shadows, studio photography, dramatic warm atmosphere, high contrast, meticulously styled hair, sophisticated style, high-definition image, fashion portrait, golden hues, artistic photography.

03结合InstantID写真
chinese women, 1girl, solo, long_hair, breasts, looking_at_viewer, brown_hair, dress, cleavage, brown_eyes, collarbone, upper_body, small_breasts, sleeveless, lips, realistic, orange_dress

04.结合InstantID写真
chinese women, A striking composition featuring a woman with flowing, dark brown hair cascading over her shoulders, illuminated by warm, golden backlighting that creates a halo-like effect. She is wearing a vivid orange sleeveless gown with a deep V-neckline, highlighting her collarbone and smooth, glowing skin. The overall color palette merges rich amber tones with soft textures, evoking a cinematic, elegant portrait feeling.

为了帮助大家更好地掌握 ComfyUI,我花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取


















 269
269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









