






近日用到了diffusers库,但是本人仅仅对Unet有简单了解,对于diffusers中使用的多种Unet类型初看一头雾水,其中加入了很多结构,所以本文解析一下库中的Unet网络源码
diffusers库:https://github.com/huggingface/diffusers
解析代码位置:src/diffusers/models/unet_2d_condition.py
1. 简述
1.1 类介绍
先看注释对网络的解释:UNet2DConditionModel is a conditional 2D UNet model that takes in a noisy sample, conditional state, and a timestep and returns sample shaped output.(UNet2DConditionModel 是一个条件2D UNet模型,它接受一个有噪声的样本、条件状态和一个时间步长并返回样本形状的输出。)
类的初始化方法内的主要参数有下列几个:
sample_size:输入输出的size
in_channels:输入的通道数
out_channels:输出的通道数
down_block_types:使用的下采样块元组,默认为(“CrossAttnDownBlock2D”, “CrossAttnDownBlock2D”, “CrossAttnDownBlock2D”, “DownBlock2D”)
up_block_types:使用的上采样块元组,默认为(“UpBlock2D”, “CrossAttnUpBlock2D”, “CrossAttnUpBlock2D”, “CrossAttnUpBlock2D”,)
layers_per_block:每个块中包含的层数,默认为2
Unet模型的大致结构如下

Unet总结构
我们主要关注三个点:下采样模块、中间模块、上采样模块
其中 time_embedding 和 text_embedding 都是不变的,在每一个块里边都对模型提供当前Unet所处time信息以及全局text的指导信息(就是prompt),Resnet 中 xx_embeding 的生效方式就是直接加上去(简单粗暴),Transformer 中执行交叉注意力来使用指导信息 xx_embeding,大部分区域中 time_embeding 和 text_embeding 也都是直接加和然后当作一个最终 embeding 来用的。
所有的模块中都包含Resnet层,而这里的Resnet是改进后的,可以使用time_embedding嵌入,而text_embedding则被模块中的Transformer层使用,所以说我们输入的两个嵌入其实是分开使用的,最后在某处合并
1.2 前期准备
我们首先要了解源码中 forward 方法内大致流程,python中深度学习模型一般有一个必不可少的方法就是forward,当使用 f = Unet() 创建一个对象模型 f 的时候,我们可以直接使用 f(input) 来获取模型的输出,这里就是自动调用了 forward 函数,其底层实现是继承了 torch.nn.Module 而 torch.nn.Module 是使用了__call__()方法来使得其可以在使用自身子类创建的对象作为函数使用时可以直接调用子类的 forward 函数
UNet2DConditionModel 中的 forward 函数输入参数如下:
sample: 输入的噪声图像数据
timestep: 时间步,即当前去噪对应的步数
encoder_hidden_states: 编码器输出的隐藏状态,和图像sample的size相同(就是编码器encoder输出)
class_labels: 图像分类标签
return_dict: 是否返回一个包含输出信息的字典信息,True就返回 UNet2DConditionOutput 对象
函数中主要流程如下:
- 通过 timestep 进行编码,并进行 embedding 获取到 t_emb
- 对 class_labels 进行 embedding 获取到 class_emb (class_emb可以为空)
- 通过 emb = t_emb + class_emb 获取到最终嵌入变量 emb 也是后边 temb 输入的参数
- 对 sample 进行一次卷积得到 sample
- 遍历下采样模块,依次执行(每次的输出保存到 res_samples)
- 执行中间层模块
- 遍历上采样模块,依次执行(每次都会从 res_samples 拿到对应层的内容作为额外输入)
- 对上采样后的内容依次进行 GroupNorm、SiLu激活、Conv2d卷积操作 后得到最后的输出
注意上述过程中需要注意力的模块会同时用到 emb 和 encoder_hidden_states ,encoder_hidden_states 相当于 context 的嵌入,emb 是 resnet 中要用到的类和时间的指导信息
这里边除了 下采样、中间层、上采样 这三个模块外其他内容都比较常见,也容易理解,但是对于采样模块以及嵌入对他们的指导(交叉注意力)缺乏深入了解,所以我们下边就着重介绍这几个模块。
2. 模块分析
2.1 下采样模块
下采样模块是为了抽取图像特征的同时,降低图像的尺寸,这样可以抽取到更为抽象和全局的特征,其中两个子块的组成如下图
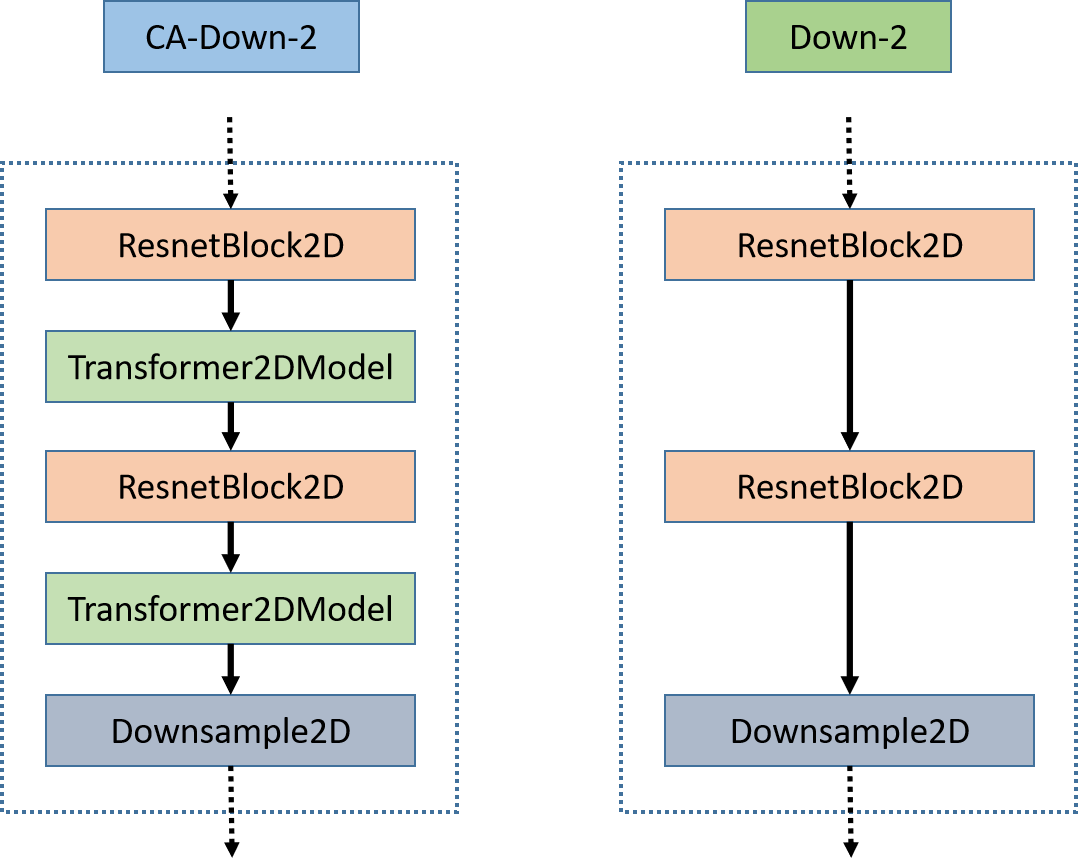
下采样模块详细组成
CA-Down-2 是交叉注意力下采样模块,而 Down-2 是去掉注意力层后的下采样模块,两个子块中所有组成层有 ResnetBlock2D、Transformer2DModel、Downsample2D 三种。其中下采样的操作由两个子块中最后一层的Downsample2D 完成。其他层则进行特征提取,通道数可能会变化,但高和宽并不会变化。接下来我们分别详细介绍他们的结构和作用,根据他们的作用来理解两个子块。
ResnetBlock2D

ResnetBlock2D结构
ResnetBlock2D 是普通的Resnet进行了嵌入改进,而改进的方式就是直接将 forward 中的输入 temb = text_embedding + time_embedding 加到 resnet 中间层的输出中(朴实无华),因为维度要进行变更,所以过了一次线性层,之后得到的内容就直接加到了其上一层 Conv2d 的输出中。
Transformer2DModel

Transformer2DModel结构
而Transformer2DModel也使用了嵌入(包含交叉注意力和自注意力),提供指导信息(context)的时候就执行交叉注意力,否则就执行自注意力,例如我的输入是 X ,context 是 E,如果 E 不为空我们就对 X 和 E 执行自注意力操作(即使用 X 的变换作为 Q 、使用 E 的两个变换分别作为 KV),如果 E 为空我们就对 X 和 X 执行注意力操作(即 KQV 由 X 的三个线性变换得到),前者是交叉注意力,后者是自注意力
Transformer2DModel 中的 Conv2d 并没有进行size放缩,所以输入和输出的size相同
注意力主要由 CrossAttention 实现,其就是经典的 transformer 中的那一套,不懂得可以看看Transformer的文章(就是对输入线性变换得到 KQV 然后 KQV 再一顿加减乘除得到一个输出)
Downsample2D
此处执行了 stride=2 的卷积操作来进行降采样,下采样模块中除了此层外,其他层皆没有改变变量的 **高和宽,**同时并不是四个 下采样子块中 都包含 Downsample2D ,最后一个 Down-2 中是没有 Downsample2D 的,而在上采样模块中,最后一个 CA-Up-2 子块同样不含 Upsample2D(可能是这样效果更稳定?)
2.2 中间模块

中间层组成
中间层即 UNetMidBlock2DCrossAttn,用于衔接下采样和上采样模块,内部的层和在下采样模块中的类型一样,并且中间层的输入和输出的 size 相同
2.3 上采样模块

上采样模块结构
上采样模块和下采样模块中的子块是一一对应的,但是子块构成稍有不同,CA-Down-2 有两层Resnet+Transformer 结构,但是在 CA-Up-2 中有三层,同样在 Up-2 中也有三层。
其次上采样和下采样模块中的 Downsample2D Unsample2D 有一定的区别:
下采样中 含有一个 Downsample2D 层,其进行卷积来下采样,而在上采样中将其替换为了 Upsample2D,使用了卷积来进行上采样
3. 注意力机制
3.1 自注意力机制
自注意力操作即在Transformer中仅仅使用输入的 X 的变换得到 KQV,在Unet中对图像进行自注意力操作可以建立全局联系,处理长距离依赖关系,并且提供更全面的上下文信息
3.2 交叉注意力机制
交叉注意力操作即在Transformer中使用输入的 X 的变换得到 Q,使用文本嵌入 contex 的变换得到 KV,Unet中使用的交叉注意力机制是文本到图像的注意力,即通过文本得到图像中文本对应的内容,并将其给予更高的权重,比如我们给定文字中有猫,那么经过交叉注意力计算后,图像中猫的区域就会被标记出来。
一般的文本(text)和图像(image)之间的交叉注意力是通过以下步骤来实现:
- 文本表示:将文本输入文本编码器进行编码,得到文本的表示向量(通常是固定长度的向量)
- 图像表示:图像经过卷积等处理模块提取特征,并生成图像的表示向量(通常是二维特征图)
- 注意力计算:利用文本表示向量和图像表示向量之间的相似度计算注意力权重(余弦相似度等度量)
- 加权汇总:使用注意力权重对图像特征进行加权汇总,得到文本相关的图像表示(标记相关区域)
如果我们需要的是图像输出,那么交叉注意力模块可以只得到和输入图像大小相同的输出来进行标记;如果我们需要文本输出,那么我们会使用图像来得到文本中的显著性内容,并输出和输入文本大小相同的输出来标记。
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的AIGC全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 3431
3431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









