







本文主要介绍sd发展的第一阶段版本的模型架构和一些微调训练方法,后续版本SDXL,LCM 版本再写文章继续介绍
SD 1.x 版本模型结构
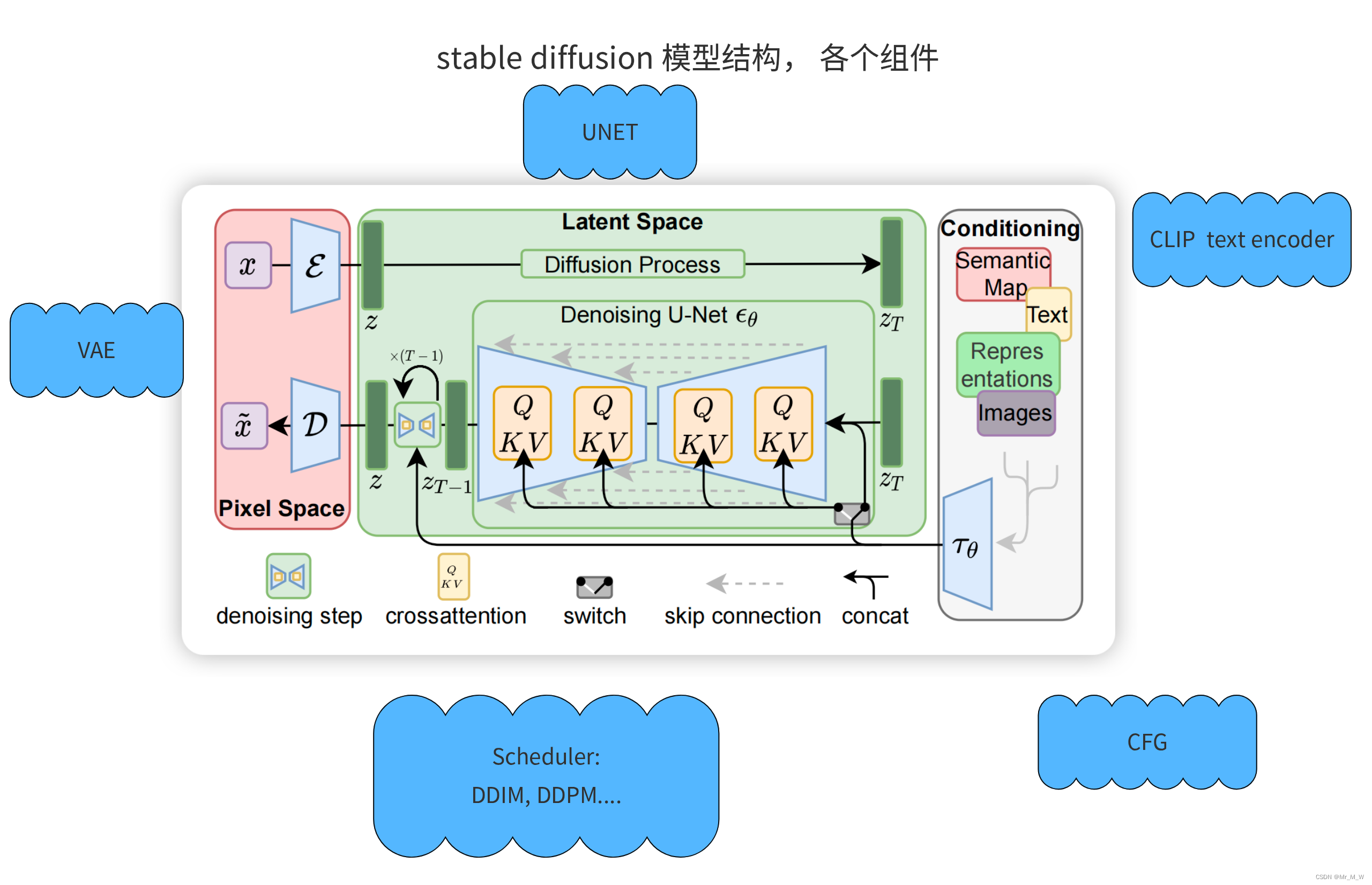 autoencoder(VAE):encoder将图像压缩到latent空间,而decoder将latent解码为图像;
autoencoder(VAE):encoder将图像压缩到latent空间,而decoder将latent解码为图像;
CLIP text encoder:提取输入text的text embeddings,通过cross attention方式送入扩散模型的UNet中作为condition;
UNet:扩散模型的主体,用来实现文本引导下的latent生成。
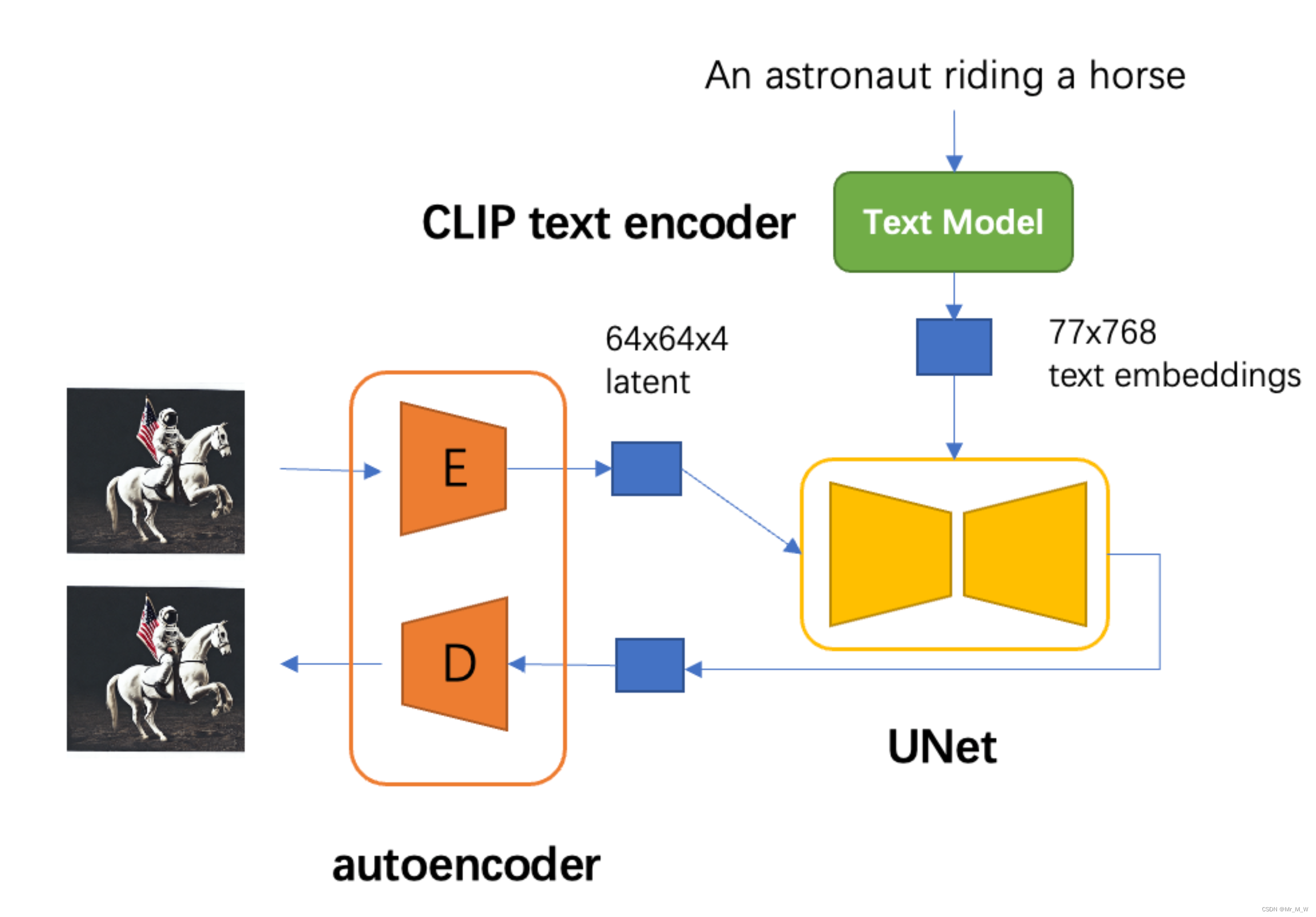
VAE
autoencoder是一个基于encoder-decoder架构的图像压缩模型,对于一个大小为H×W×3的输入图像,encoder模块将其编码为一个大小为h× w × c的latent,其中f = H/h = W/h为下采样
率(downsampling factor)。
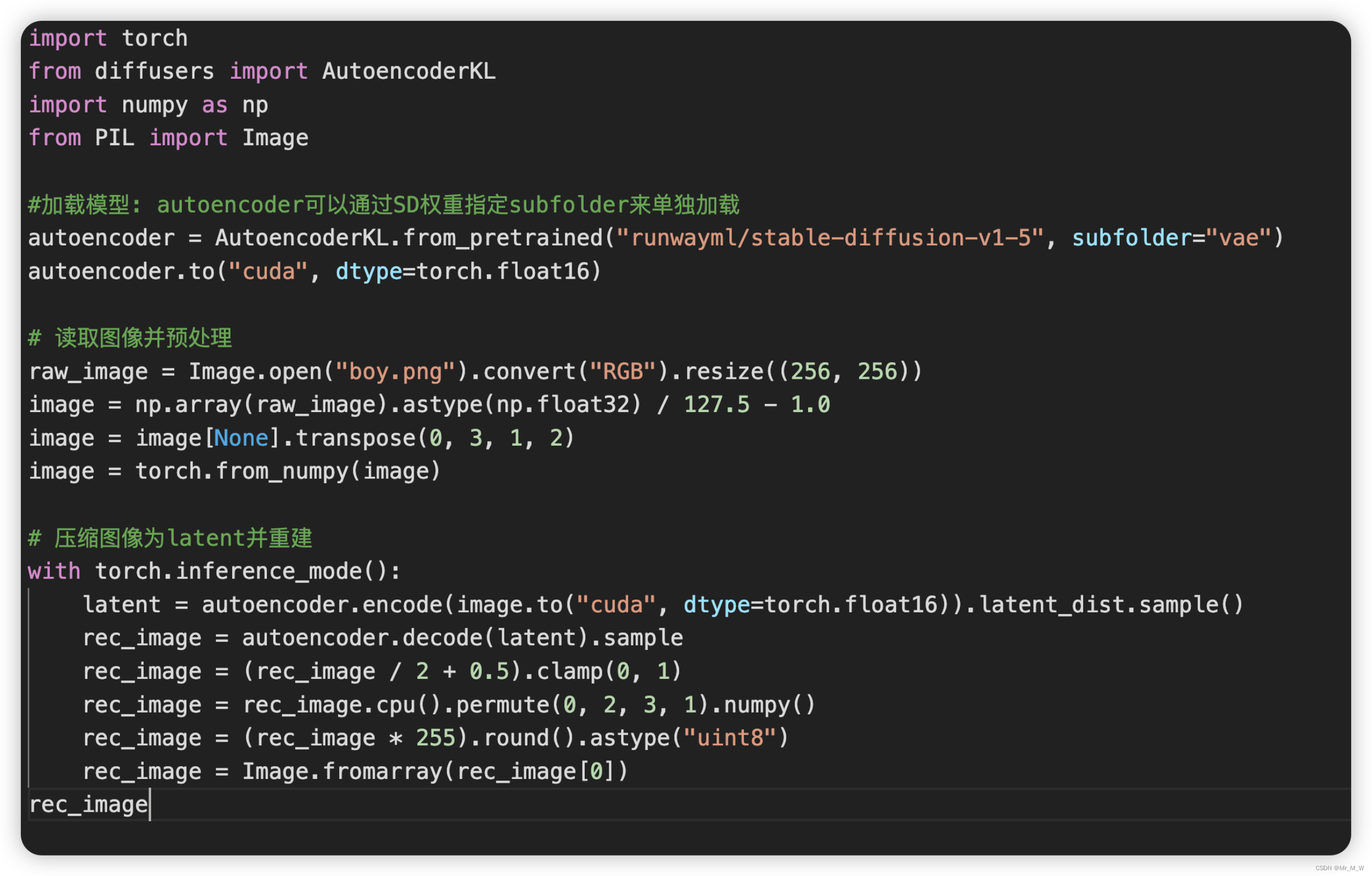
使用diffusers库来加载autoencoder模型,并使用autoencoder来实现图像的压缩和重建,代码如下所示:
使用两张图片在256x256和512x512下的重建效果对比
如下所示,第一列为原始图片,第二列为512x512尺寸下的重建图,第三列为256x256尺寸下的重建图。对比可以看出,autoencoder将图片压缩到latent后再重建其实是有损的,比如会出现文字和人脸的畸变,在256x256分辨率下是比较明显的,512x512下效果会好很多。


CLIP
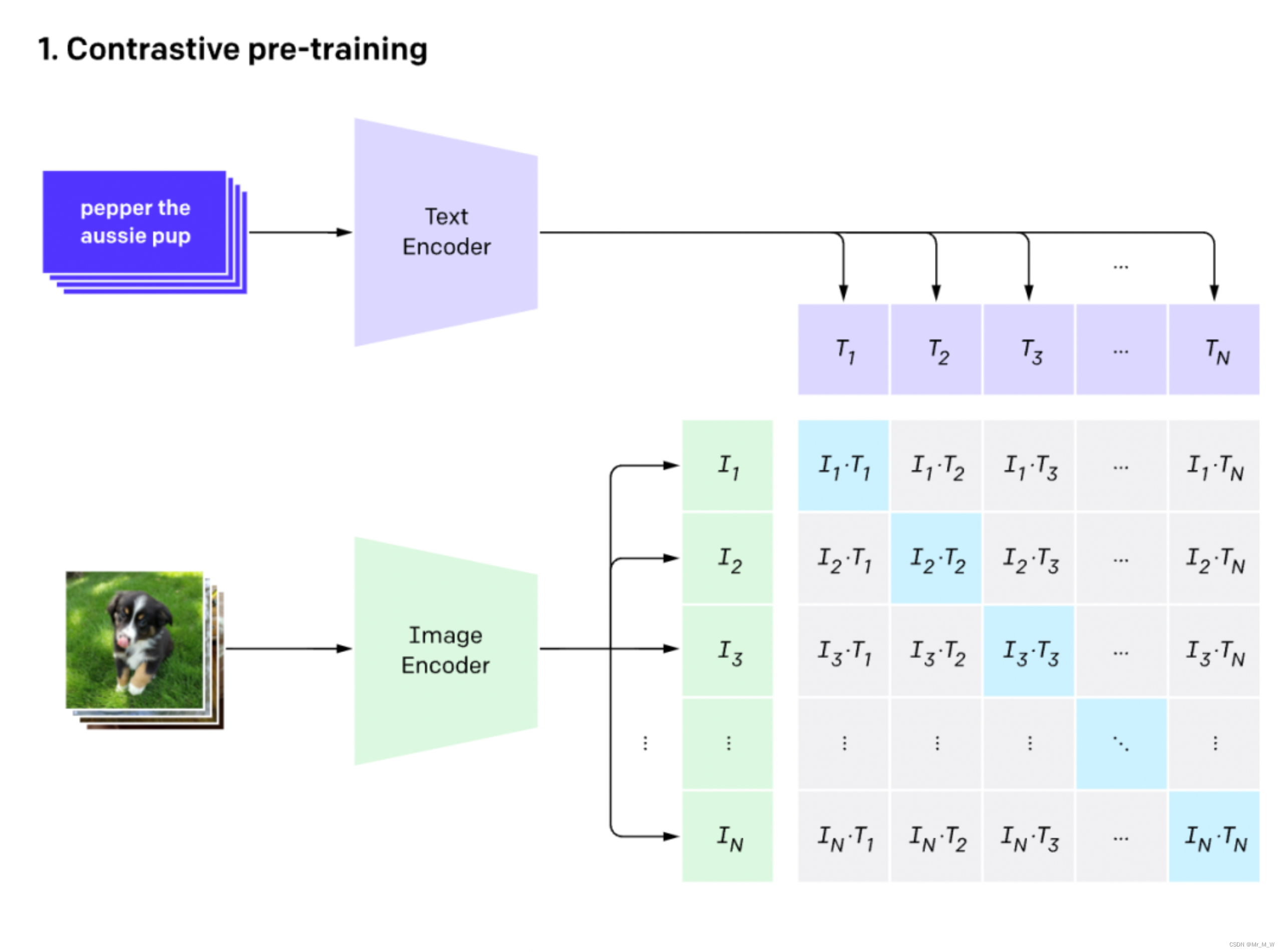
CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练方法或者模型。CLIP是一种基于对比学习的多模态模型
与CV中的一些对比学习方法如moco和simclr不同的是,CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。
如下图所示,CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。
CLIP text encoder
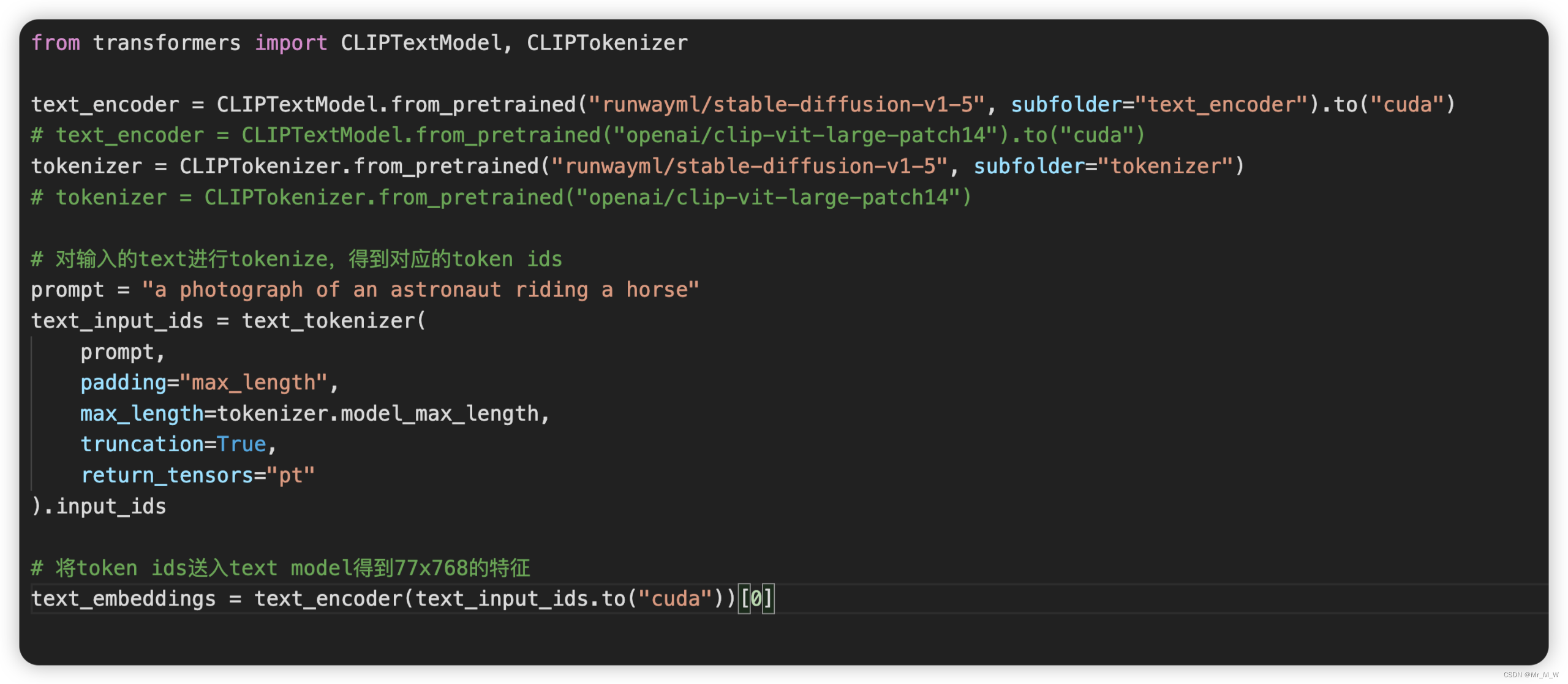
SD采用CLIP text encoder来对输入text提取text embeddings,具体的是SD 1.X 采用目前OpenAI所开源的最大CLIP模型:clip-vit-large-patch14,这个CLIP的text encoder是一个transformer模型(只有encoder模块):层数为12,特征维度为768,模型参数大小是123M。
对于输入text,送入CLIP text encoder后得到最后的hidden states(即最后一个transformer block得到的特征),其特征维度大小为77x768(77是token的数量),这个细粒度的text embeddings将以cross attention的方式送入UNet中。在transofmers库中,可以如下使用CLIP text encoder:
Unet
SD的扩散模型是一个860M的UNet,其主要结构如下图所示(这里以输入的latent为64x64x4维度为例),其中encoder部分包括3个CrossAttnDownBlock2D模块和1个DownBlock2D模块,而decoder部分包括1个UpBlock2D模块和3个CrossAttnUpBlock2D模块,中间还有一个UNetMidBlock2DCrossAttn模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1585
1585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









