






diffusers库是用stable diffusion一定要用的库之一。
安装方法为:
pip install diffusers但是其实安装了该库,很多时候我也不知道该怎么用,在别人的GitHub的issue里问了很多傻傻的问题,最终思来想去,还是决定从0看一下其中的代码。
代码仓库为:https://github.com/huggingface/diffusers
那么下载好源码之后我们就可以看其中封装的各个类和各个函数了。
1、UNet2DConditionModel
这是diffusion model的最核心组件了,所以从该文件开始看起,文件路径为./src/diffusers/models/unet_2d_condition.py,该文件里就封装了我们的这个类。
1.1 对init函数的解读
初始化函数第一句为:
if num_attention_heads is not None:
raise ValueError(
"At the moment it is not possible to define the number of attention heads via `num_attention_heads` because of a naming issue as described in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131. Passing `num_attention_heads` will only be supported in diffusers v0.19."
)
num_attention_heads = num_attention_heads or attention_head_dim这告诉我们,不能将num_attention_heads这个参数传入init中,否则就会报错,这个参数只在diffusers 0.19版本可以用,而我更新这篇博客时版本已经在0.28了,所以小伙伴们使用时要注意版本问题。如果你想定义该参数,你只需要把想要的参数传入attention_head_dim里即可,默认为8.
接下来对参数进行检查。
self._check_config(
down_block_types=down_block_types,
up_block_types=up_block_types,
only_cross_attention=only_cross_attention,
block_out_channels=block_out_channels,
layers_per_block=layers_per_block,
cross_attention_dim=cross_attention_dim,
transformer_layers_per_block=transformer_layers_per_block,
reverse_transformer_layers_per_block=reverse_transformer_layers_per_block,
attention_head_dim=attention_head_dim,
num_attention_heads=num_attention_heads,
)确保down_block的层数和up_block的层数相同。确保每个down_block都有输出通道的说明。确保每个down_block里都有指示是否要使用self-attention。确保每个down_block都有注意力头的说明。确保每个down_block都有维度的说明。确保每个down_block都有层数的说明。因此这一步就是为了检查输入的合理性。
随后定义了一个单层卷积层,不改变图像尺寸,只改变图像通道。
conv_in_padding = (conv_in_kernel - 1) // 2
self.conv_in = nn.Conv2d(in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding)接下来定义了时间编码投影层以及维度。这里实例化了一个self.time_proj类,可以对后续时间步进行处理。后续还实例化了一个self.time_embedding类,输入维度为self.time_proj的输出维度。
def _set_time_proj(
self,
time_embedding_type: str,
block_out_channels: int,
flip_sin_to_cos: bool,
freq_shift: float,
time_embedding_dim: int,
) -> Tuple[int, int]:
if time_embedding_type == "fourier":
time_embed_dim = time_embedding_dim or block_out_channels[0] * 2
if time_embed_dim % 2 != 0:
raise ValueError(f"`time_embed_dim` should be divisible by 2, but is {time_embed_dim}.")
self.time_proj = GaussianFourierProjection(
time_embed_dim // 2, set_W_to_weight=False, log=False, flip_sin_to_cos=flip_sin_to_cos
)
timestep_input_dim = time_embed_dim
elif time_embedding_type == "positional":
time_embed_dim = time_embedding_dim or block_out_channels[0] * 4
self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
timestep_input_dim = block_out_channels[0]
else:
raise ValueError(
f"{time_embedding_type} does not exist. Please make sure to use one of `fourier` or `positional`."
)
return time_embed_dim, timestep_input_dim
time_embed_dim, timestep_input_dim = self._set_time_proj(
time_embedding_type,
block_out_channels=block_out_channels,
flip_sin_to_cos=flip_sin_to_cos,
freq_shift=freq_shift,
time_embedding_dim=time_embedding_dim,
)
self.time_embedding = TimestepEmbedding(
timestep_input_dim,
time_embed_dim,
act_fn=act_fn,
post_act_fn=timestep_post_act,
cond_proj_dim=time_cond_proj_dim,
)随后对编码器隐藏状态做了一个投影,定义了一个投影层self.encoder_hid_proj,如果编码隐藏状态类型是“text proj”,那么该投影层是单层全连接层,如果类型是“text_image_proj”,那么该投影层是TextImagePeojection类,如果类型是“image_proj”,那么该投影层是ImageProjection类。不管该投影层是什么属性,反正最后的输出维度都是cross_attention_dim。
self._set_encoder_hid_proj(
encoder_hid_dim_type,
cross_attention_dim=cross_attention_dim,
encoder_hid_dim=encoder_hid_dim,)接下来定义了一个类别编码层,self.class_embedding,和上面的encoder隐藏状态一样,根据不同的输入类型有不同的结构,但总归输出的维度都是time_embed_dim。
self._set_class_embedding(
class_embed_type,
act_fn=act_fn,
num_class_embeds=num_class_embeds,
projection_class_embeddings_input_dim=projection_class_embeddings_input_dim,
time_embed_dim=time_embed_dim,
timestep_input_dim=timestep_input_dim,
)随后定义了一个self.add_embedding层,仍然是根据不同的输入类型有不同的结构,但最终还是输出的维度是一样的,都是time_embed_dim。
self._set_add_embedding(
addition_embed_type,
addition_embed_type_num_heads=addition_embed_type_num_heads,
addition_time_embed_dim=addition_time_embed_dim,
cross_attention_dim=cross_attention_dim,
encoder_hid_dim=encoder_hid_dim,
flip_sin_to_cos=flip_sin_to_cos,
freq_shift=freq_shift,
projection_class_embeddings_input_dim=projection_class_embeddings_input_dim,
time_embed_dim=time_embed_dim,
)然后定义了一个激活函数层self.time_embed_act.
if time_embedding_act_fn is None:
self.time_embed_act = None
else:
self.time_embed_act = get_activation(time_embedding_act_fn)随后还是对输入参数的合理性做了一些处理,比如说有些参数在encoder或decoder的每个块都要用到,如果这个参数是列表,那就是合理的,如果这些参数是数字的话,也就说明每个块用到的参数是相同的,要把它们转换为列表形式。
if isinstance(only_cross_attention, bool):
if mid_block_only_cross_attention is None:
mid_block_only_cross_attention = only_cross_attention
only_cross_attention = [only_cross_attention] * len(down_block_types)
if mid_block_only_cross_attention is None:
mid_block_only_cross_attention = False
if isinstance(num_attention_heads, int):
num_attention_heads = (num_attention_heads,) * len(down_block_types)
if isinstance(attention_head_dim, int):
attention_head_dim = (attention_head_dim,) * len(down_block_types)
if isinstance(cross_attention_dim, int):
cross_attention_dim = (cross_attention_dim,) * len(down_block_types)
if isinstance(layers_per_block, int):
layers_per_block = [layers_per_block] * len(down_block_types)
if isinstance(transformer_layers_per_block, int):
transformer_layers_per_block = [transformer_layers_per_block] * len(down_block_types)接下来定义了一个时间编码特征的维度,我猜测这里的维度应该就是输入到UNet每层里的时间编码的结构,如果类别特征与时间特征串联的话,那么维度拼接变为原来的2倍,如果不串联,那就是按位相加,维度还是保持不变。
if class_embeddings_concat:
# The time embeddings are concatenated with the class embeddings. The dimension of the
# time embeddings passed to the down, middle, and up blocks is twice the dimension of the
# regular time embeddings
blocks_time_embed_dim = time_embed_dim * 2
else:
blocks_time_embed_dim = time_embed_dim接下来开始定义UNet的框架了,首先从论文中可以看出,UNet包括下采样层,中层以及上采样层,因此这些网络结构都需要分别定义。
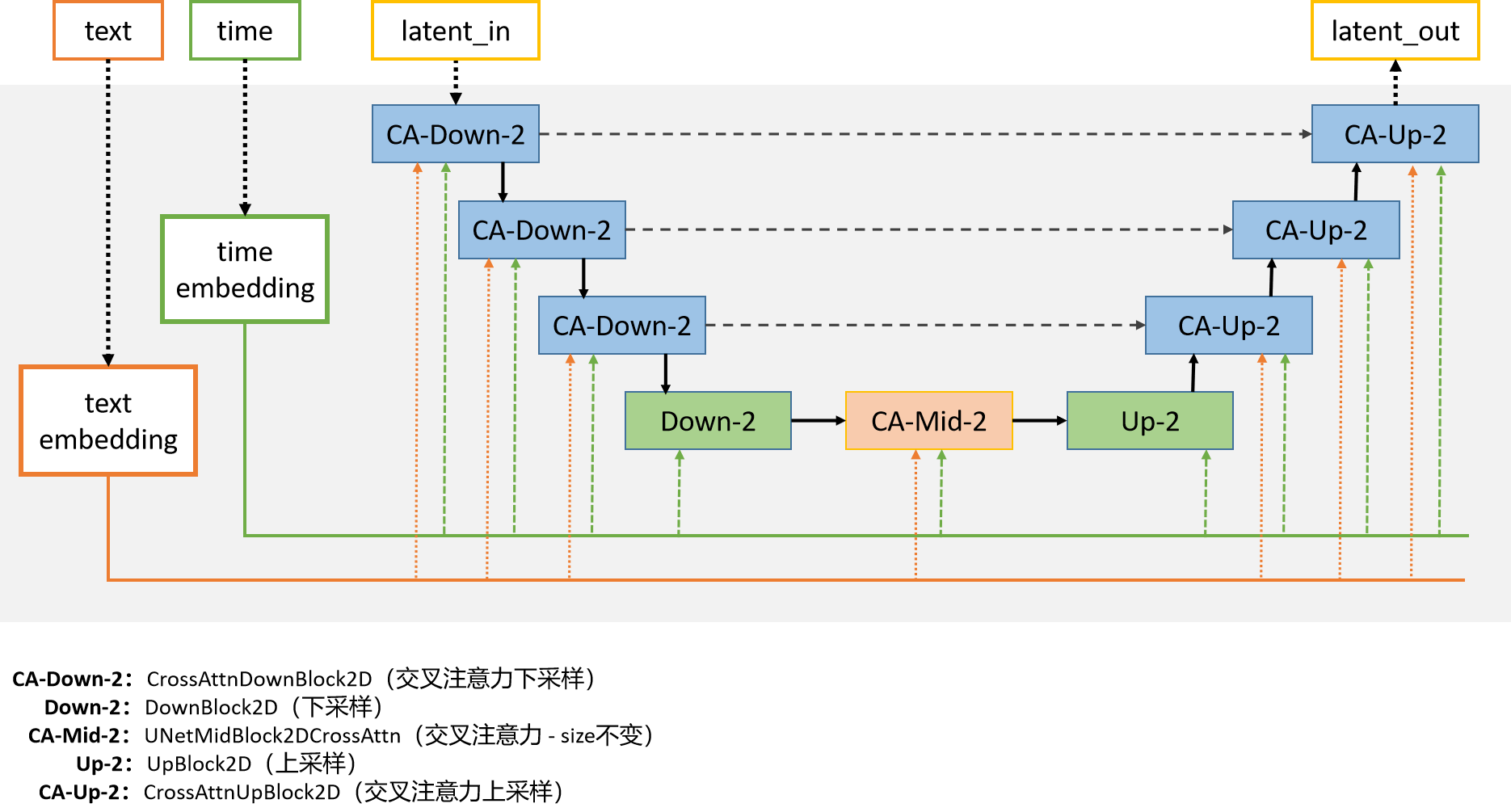
首先来看下采样层,是由一个函数决定的,就是这个get_down_block.
output_channel = block_out_channels[0]
for i, down_block_type in enumerate(down_block_types):
input_channel = output_channel
output_channel = block_out_channels[i]
is_final_block = i == len(block_out_channels) - 1
down_block = get_down_block(
down_block_type,
num_layers=layers_per_block[i],
transformer_layers_per_block=transformer_layers_per_block[i],
in_channels=input_channel,
out_channels=output_channel,
temb_channels=blocks_time_embed_dim,
add_downsample=not is_final_block,
resnet_eps=norm_eps,
resnet_act_fn=act_fn,
resnet_groups=norm_num_groups,
cross_attention_dim=cross_attention_dim[i],
num_attention_heads=num_attention_heads[i],
downsample_padding=downsample_padding,
dual_cross_attention=dual_cross_attention,
use_linear_projection=use_linear_projection,
only_cross_attention=only_cross_attention[i],
upcast_attention=upcast_attention,
resnet_time_scale_shift=resnet_time_scale_shift,
attention_type=attention_type,
resnet_skip_time_act=resnet_skip_time_act,
resnet_out_scale_factor=resnet_out_scale_factor,
cross_attention_norm=cross_attention_norm,
attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
dropout=dropout,
)
self.down_blocks.append(down_block)1.2 对get_down_block函数的解读
get_down_block函数位于unet_2d_blocks.py文件中
首先要对block类型名进行修正,也就是说之前版本的block名字前面加“UNetRes”,如果还有人使用过去的名字,就需要把UNetRes这个前缀给去掉。
down_block_type = down_block_type[7:] if down_block_type.startswith("UNetRes") else down_block_type随后根据block的类型名选择相应的网络结构,block可供选择的类型有很多,一般在stable diffusion里选择的是:
"CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D"那么分别来看这两种结构的类型
1.2.1 crossattendownblock2d
crossattendownblock2d的实现为:首先每个网络层都包含一个resnetblock2d以及一个attention层,那么这个过程循环n次,值得注意的是,这些网络层都不改变特征尺寸,随后经过的downsample层来决定要不要下采样。
for i in range(num_layers):
in_channels = in_channels if i == 0 else out_channels
resnets.append(
ResnetBlock2D(
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
if not dual_cross_attention:
attentions.append(
Transformer2DModel(
num_attention_heads,
out_channels // num_attention_heads,
in_channels=out_channels,
num_layers=transformer_layers_per_block[i],
cross_attention_dim=cross_attention_dim,
norm_num_groups=resnet_groups,
use_linear_projection=use_linear_projection,
only_cross_attention=only_cross_attention,
upcast_attention=upcast_attention,
attention_type=attention_type,
)
)
else:
attentions.append(
DualTransformer2DModel(
num_attention_heads,
out_channels // num_attention_heads,
in_channels=out_channels,
num_layers=1,
cross_attention_dim=cross_attention_dim,
norm_num_groups=resnet_groups,
)
)
self.attentions = nn.ModuleList(attentions)
self.resnets = nn.ModuleList(resnets)
if add_downsample:
self.downsamplers = nn.ModuleList(
[
Downsample2D(
out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
)
]
)
else:
self.downsamplers = None1.2.2 DownBlock2D
接下来来看downblock2d层,每层由resnetblock2d组成,没有attention层了,最后再决定要不要下采样。
for i in range(num_layers):
in_channels = in_channels if i == 0 else out_channels
resnets.append(
ResnetBlock2D(
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
self.resnets = nn.ModuleList(resnets)
if add_downsample:
self.downsamplers = nn.ModuleList(
[
Downsample2D(
out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
)
]
)
else:
self.downsamplers = None1.3 对get_mid_block的解读
上面对encoder解读之后,有个中间层,层结构的类型也可供选择,分别是:UNetMidBlock2DCrossAttn、UNetMidBlock2DSimpleCrossAttn、UNetMidBlock2D,这些结构都不改变图像尺寸。
self.mid_block = get_mid_block(
mid_block_type,
temb_channels=blocks_time_embed_dim,
in_channels=block_out_channels[-1],
resnet_eps=norm_eps,
resnet_act_fn=act_fn,
resnet_groups=norm_num_groups,
output_scale_factor=mid_block_scale_factor,
transformer_layers_per_block=transformer_layers_per_block[-1],
num_attention_heads=num_attention_heads[-1],
cross_attention_dim=cross_attention_dim[-1],
dual_cross_attention=dual_cross_attention,
use_linear_projection=use_linear_projection,
mid_block_only_cross_attention=mid_block_only_cross_attention,
upcast_attention=upcast_attention,
resnet_time_scale_shift=resnet_time_scale_shift,
attention_type=attention_type,
resnet_skip_time_act=resnet_skip_time_act,
cross_attention_norm=cross_attention_norm,
attention_head_dim=attention_head_dim[-1],
dropout=dropout,
)1.4 对get_up_block的解读
encoder和中间层之后,要经过decoder层,decoder和encoder正好对称,因此参数要做一个反转操作。
"UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D"和get_down_block一样,最后决定要不要上采样即可。
定义完encoder、mid和decoder之后,最后再经过一个不改变尺寸的单卷积层映射。
conv_out_padding = (conv_out_kernel - 1) // 2
self.conv_out = nn.Conv2d(
block_out_channels[0], out_channels, kernel_size=conv_out_kernel, padding=conv_out_padding
)1.5 对forward函数的解读
def forward(
self,
sample: torch.Tensor,
timestep: Union[torch.Tensor, float, int],
encoder_hidden_states: torch.Tensor,
class_labels: Optional[torch.Tensor] = None,
timestep_cond: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
mid_block_additional_residual: Optional[torch.Tensor] = None,
down_intrablock_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
return_dict: bool = True,
)sample指的是网络的输入,也就是加噪后的噪声图noise,timestep是模型的加噪步数,encoder_hidden_state是模型的condition的编码,文生图中就指的是文字特征。class_labels可有可无,如果有的话就会和时间编码加在一起,或是concat,上面已经讲过。timestep_cond指的是时间步的条件特征。attention_mask用于掩蔽输入的condition。down_block_additional_residuals是加在unet下采样block的特征,mid_block_additional_residual是加在mid层的特征,down_intrablock_additional_residuals是加在decoder层的特征。
随后来看前向过程,时间和class先经过init中定义的各个类来进行编码,然后拼接或按位相加得到emb,即时间编码。
t_emb = self.get_time_embed(sample=sample, timestep=timestep)
emb = self.time_embedding(t_emb, timestep_cond)
aug_emb = None
class_emb = self.get_class_embed(sample=sample, class_labels=class_labels)
if class_emb is not None:
if self.config.class_embeddings_concat:
emb = torch.cat([emb, class_emb], dim=-1)
else:
emb = emb + class_emb
aug_emb = self.get_aug_embed(
emb=emb, encoder_hidden_states=encoder_hidden_states, added_cond_kwargs=added_cond_kwargs
)
if self.config.addition_embed_type == "image_hint":
aug_emb, hint = aug_emb
sample = torch.cat([sample, hint], dim=1)
emb = emb + aug_emb if aug_emb is not None else emb
if self.time_embed_act is not None:
emb = self.time_embed_act(emb)
encoder_hidden_states = self.process_encoder_hidden_states(
encoder_hidden_states=encoder_hidden_states, added_cond_kwargs=added_cond_kwargs
)随后图像sample经过不改变图像尺寸只改变特征的单层卷积层提取浅层特征。
sample = self.conv_in(sample)随后来对额外输入进行一个规范化。如果mid的额外输入和下采样的额外输入都不为空,那么is_controlnet就是True。如果intrablock额外输入不为空,那么is_adapter为True。
如果intrablock为空,mid额外输入为空,只有下采样的额外输入不为空,那么实际上令intrablock为down_block_additional,而down_block_addition已经被弃用了。
is_controlnet = mid_block_additional_residual is not None and down_block_additional_residuals is not None
# using new arg down_intrablock_additional_residuals for T2I-Adapters, to distinguish from controlnets
is_adapter = down_intrablock_additional_residuals is not None
# maintain backward compatibility for legacy usage, where
# T2I-Adapter and ControlNet both use down_block_additional_residuals arg
# but can only use one or the other
if not is_adapter and mid_block_additional_residual is None and down_block_additional_residuals is not None:
deprecate(
"T2I should not use down_block_additional_residuals",
"1.3.0",
"Passing intrablock residual connections with `down_block_additional_residuals` is deprecated \
and will be removed in diffusers 1.3.0. `down_block_additional_residuals` should only be used \
for ControlNet. Please make sure use `down_intrablock_additional_residuals` instead. ",
standard_warn=False,
)
down_intrablock_additional_residuals = down_block_additional_residuals
is_adapter = True接下来进行encoder操作,由于Unet有skip connection,因此encoder每一层的输出都要保存下来再decoder阶段输入。保存为down_block_res_samples
down_block_res_samples = (sample,)
for downsample_block in self.down_blocks:
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
# For t2i-adapter CrossAttnDownBlock2D
additional_residuals = {}
if is_adapter and len(down_intrablock_additional_residuals) > 0:
additional_residuals["additional_residuals"] = down_intrablock_additional_residuals.pop(0)
sample, res_samples = downsample_block(
hidden_states=sample,
temb=emb,
encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask,
cross_attention_kwargs=cross_attention_kwargs,
encoder_attention_mask=encoder_attention_mask,
**additional_residuals,
)
else:
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
if is_adapter and len(down_intrablock_additional_residuals) > 0:
sample += down_intrablock_additional_residuals.pop(0)
down_block_res_samples += res_samples
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









