







 该博客介绍了基于深度学习的车牌识别项目,包括深度神经网络(DNN)的基础概念,深度学习在图像识别中的作用,尤其是卷积神经网络(如LeNet)如何提取特征。数据集包含65个文件夹,对应0-9、A-Z和各省简称的车牌字符,项目将数据分为训练集和测试集。博客详细讲解了数据准备、模型定义、训练、评估和实际使用的过程。
该博客介绍了基于深度学习的车牌识别项目,包括深度神经网络(DNN)的基础概念,深度学习在图像识别中的作用,尤其是卷积神经网络(如LeNet)如何提取特征。数据集包含65个文件夹,对应0-9、A-Z和各省简称的车牌字符,项目将数据分为训练集和测试集。博客详细讲解了数据准备、模型定义、训练、评估和实际使用的过程。
一、项目介绍
1.1我们的项目是一个多分类的任务,需要将照片中的每个字符分别进行识别,完成车牌的识别。

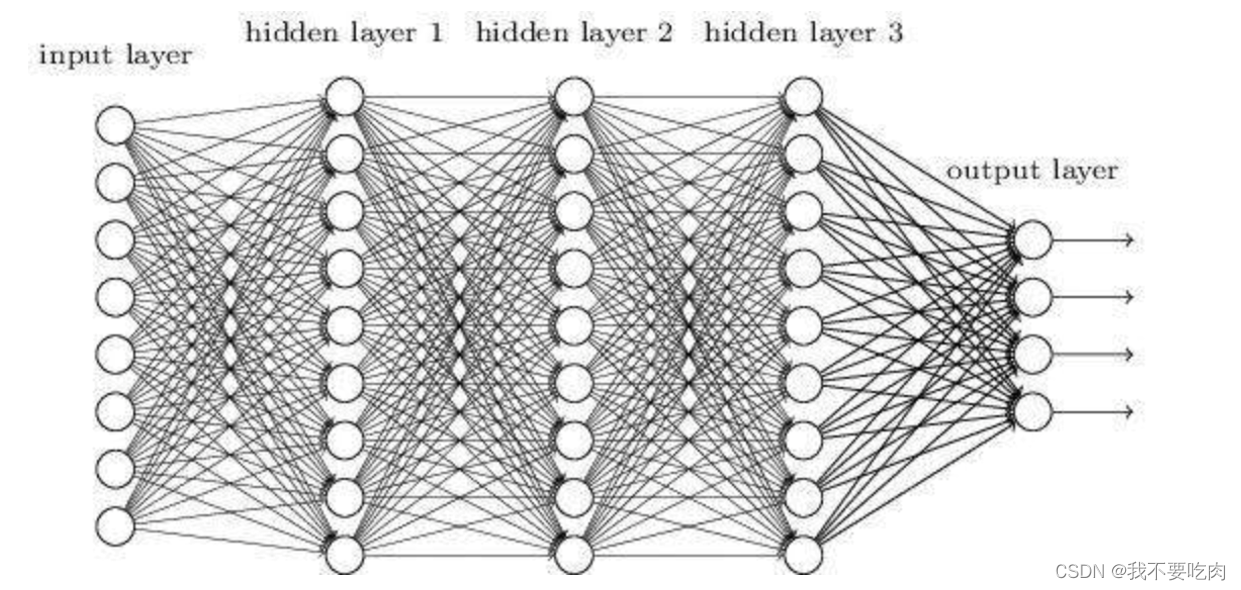
1.2深度神经网络(DNN)
深度神经网络(Deep Neural Networks,简称DNN)是深度学习的基础,其结构为input、hidden(可有多层)、output,每层均为全连接。
1.3基本概念
图像识别算法是计算机视觉中非常重要且基础的分支,类似于人类对图像内容的识别其主要任务是通过对图像中像素分布及颜色、纹理等特征的统计,将图像内容所属类别进行正确的分类。在深度学习中,图像识别模型在完成本职任务的同时还充当计算机视觉其他任务的特征提取网络(Backbone)。本文将从传统算法到深度学习算法,系统的对图像识别算法进行介绍。
1.4深度学习算法思路
深度学习提出之初主要起到特征提取的作用,2014年左右还经常能看到深度学习+SVM等分类器的两阶段训练模式。这种方式非常直观职责分明,但通过没有额外指导(特定任务的loss)学习到的特征并一定适用于某一具体任务,随着算法的演进,人们逐渐发现利用深度学习端到端的模型能够达到更好的效果。
我们探讨一下为什么深度学习可以提取特征。图像特征的本质是可以高度概括图像内容的抽象画信息,凭借人工经验提取的特征是从人的角度将纹理、颜色、形状等信息从原始像素中提取出来。这些特征都来源于图像的原始像素,虽然是一种高效的信息抽象方式,但同时会损失掉很多信息。既然人工提取的特征来源且基于原始图像计算获取的,为何不利用模型直接在原始数据上学习,这样不就没有信息损失了。然而图像中包含的有用信息是非常稀疏的,模型过多关注无用信息会导致无法收敛。卷积神经网络的提出很好的解决了这一问题。
1.5经典卷积神经网络
LeNet是由卷积层、池化层、全连接层组成的网络模型。卷积层主要作用是提取图像特征、池化层作用是尽可能保存关键信息的前提下减少计算量、全连接层起到分类器的作用,配合起到非线性变换的激活函数一个CNN的最小系统就组成了。后续研究中虽然有很多CNN的演进和变种,但核心思路和组件都是由上述几部分组成的。
如果将LeNet的中间层结果可视化,可以神奇的发现网络的浅层特征提取的是边缘等low-level特征,深层特征更加抽象,由此佐证了卷积可以提取图像特征、图像识别high-level特征解释性差(人工很难设计)的猜想。
- 几种常见的卷积
常规卷积:对图像特征进行提取,可通过padding方式补充图像边框,使输出与输入保持一致;
反卷积:可用于分割模型的decoder阶段,将提取的特征恢复原图像大小;
膨胀卷积:是扩大卷积感受野的一种方法。
二、数据集介绍
2.1数据集文件名为characterData.zip,其中有65个文件夹
2.2包含0-9,A-Z,以及各省简称
2.3图片为12020的灰度图像
2.4本次项目中,取其中的10%作为测试集,90%作为训练集

# 查看当前挂载的数据集目录, 该目录下的变更重启环境后会自动还原
# View dataset directory. This directory will be recovered automatically after resetting environment.
!ls /home/aistudio/data
#导入需要的包
import os
import zipfile
import random
import json
import cv2
import numpy as np
from PIL import Image
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph import Linear,Conv2D,Pool2D
import matplotlib.pyplot as plt三、数据准备
'''
参数配置
'''
train_parameters = {
"input_size": [1, 20, 20], #输入图片的shape
"class_dim": -1, #分类数
"src_path":"data/data23617/characterData.zip", #原始数据集路径
"target_path":"/home/aistudio/data/dataset", #要解压的路径
"train_list_path": "./train_data.txt", #train_data.txt路径
"eval_list_path": "./val_data.txt", #eval_data.txt路径
"label_dict":{}, #标签字典
"readme_path": "/home/aistudio/data/readme.json", #readme.json路径
"num_epochs": 1, #训练轮数
"train_batch_size": 32, #批次的大小
"learning_strategy": { #优化函数相关的配置
"lr": 0.001 #超参数学习率
}
}def unzip_data(src_path,target_path):
'''
解压原始数据集,将src_path路径下的zip包解压至data/dataset目录下
'''
if(not os.p 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8503
8503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









