






1.首先导入各种包
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB
from sklearn.metrics import accuracy_score
from sklearn.model_selection import learning_curve
import matplotlib.pyplot as plt2.读取数据集
data = pd.read_csv('agaricus-lepiota.data',header=None)3.将数据集分为特征和标签
X = data.iloc[:, 1:]
y = data.iloc[:, 0]4.将特征转换为欸数值型
X = pd.get_dummies(X)5.将标签转换为数值型
y = pd.factorize(y)[0]6.展示数据(可选,主要是为了更好的理解数据)
data 7.将数据集分为训练集和测试集
7.将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y
,test_size=0.3
,random_state=42)8.创建GaussianNB分类器并训练模型
gnb = GaussianNB()
gnb.fit(X_train, y_train)
9.创建MultinomialNB分类器并训练模型
mnb = MultinomialNB()
mnb.fit(X_train, y_train)
10.创建BernoulliNB分类器并训练模型
bnb = BernoulliNB()
bnb.fit(X_train, y_train)
11.使用测试集进行预测并计算准确率
gnb_pred = gnb.predict(X_test)
gnb_acc = accuracy_score(y_test, gnb_pred)
mnb_pred = mnb.predict(X_test)
mnb_acc = accuracy_score(y_test, mnb_pred)
bnb_pred = bnb.predict(X_test)
bnb_acc = accuracy_score(y_test, bnb_pred)
print('GaussianNB准确率:', gnb_acc)
print('MultinomialNB准确率:', mnb_acc)
print('BernoulliNB准确率:', bnb_acc)12.绘制关键参数最大方差对模型影响的学习率曲线
train_sizes, train_scores, test_scores = learning_curve(GaussianNB(var_smoothing=1e-9),X,y
,cv=10
,scoring='accuracy'
,train_sizes=[0.1, 0.3, 0.5, 0.7, 0.9, 1])
train_scores_mean = np.mean(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
plt.plot(train_sizes, train_scores_mean, 'o-', color='r', label='Training score')
plt.plot(train_sizes, test_scores_mean, 'o-', color='g', label='Cross-validation score')
plt.xlabel('Training examples')
plt.ylabel('Score')
plt.legend(loc='best')
plt.show()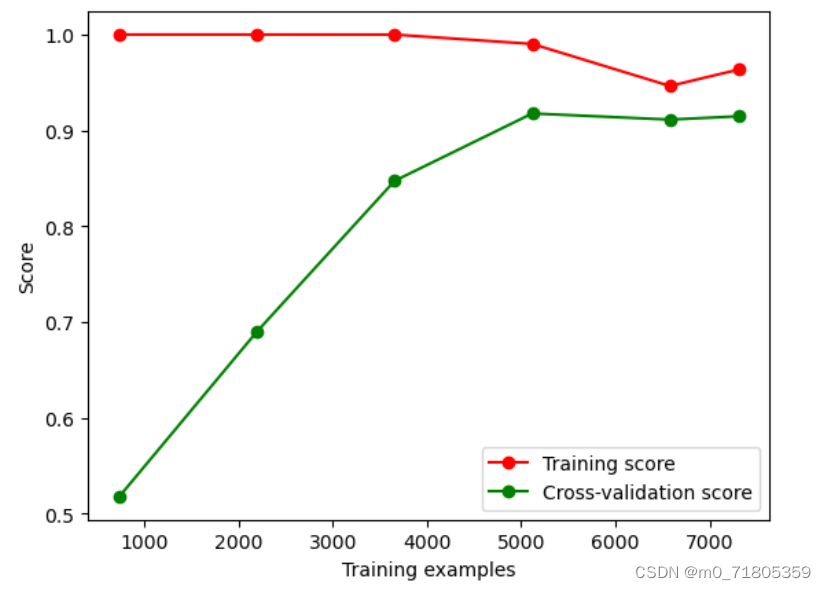















 6394
6394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









