






一、logistic回归的概念
1.线性模型与回归
线性模型一般模式:
回归:
现有一些数据点,我们用 一条直线对这些点进行拟合,该线称为最佳拟合直线,这个拟合过程就称作回归。

使得
2.Logistic回归:
Logistic回归(logistic regression)是统计学习中的经典分类方法,属于对数线性模型,所以也被称为对数几率回归。这里要注意,虽然带有回归的字眼,但是该模型是一种分类算法,Logistic回归是一种线性分类器,针对的是线性可分问题。利用logistic回归进行分类的主要思想是:根据现有的数据对分类边界线建立回归公式,以此进行分类。
利用Logistic 回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。这里的 “回归”一词源于最佳拟合,表示要找到最佳拟合参数集。 训练分类器时的做法就是寻找最佳拟合参数,使用的是最优化算法。
Logistic回归来做分类问题,我们想要的函数应该是,能接受所有的输入然后预测出类别。例如,在两个类的情况下,上述函数输出0或1。例如海维塞德阶跃函数 (Heaviside step function),也称为单位阶跃函数。
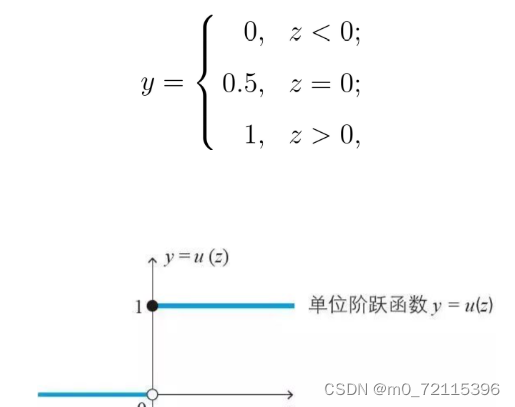
单位跃函数的问题在于: 该函数在跳跃点上从0瞬间跳跃到1(不连续、不可微),这个瞬间跳跃过程有时很难处理。
3.Sigmoid函数
但是在数学上,Sigmoid函数可以可以解决这个问题。Sigmoid函数具体的计算公式如下:
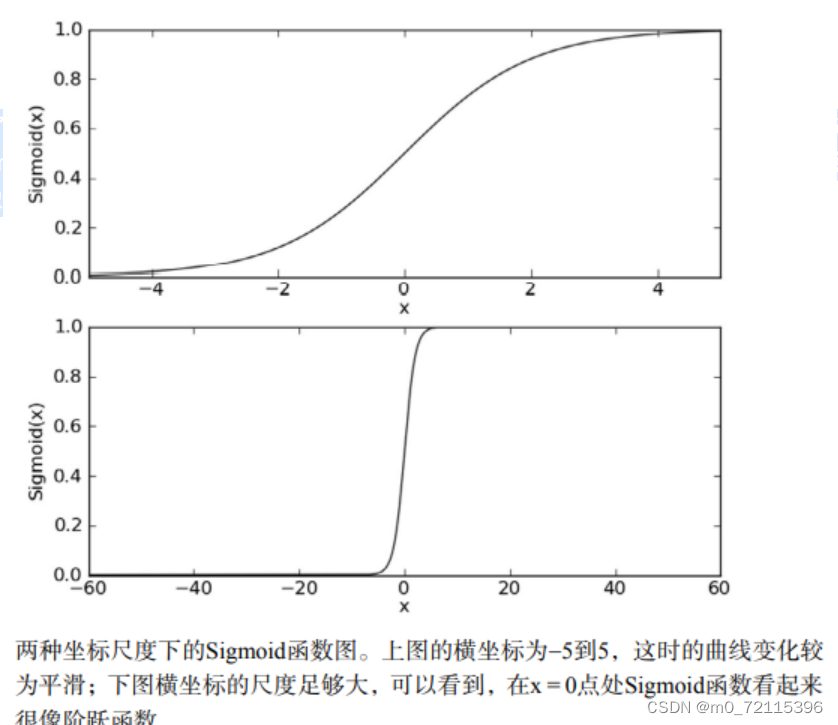
下图给出了Sigmoid函数在不同坐标尺度下的两条曲线图。当x为0时,Sigmoid函数值为0.5。 随着x的增大,对应的Sigmoid值将逼近于1;而随着x的减小,Sigmoid值将逼近于0。如果横坐标 刻度足够大,Sigmoid函数看起来很像一个阶跃函数。
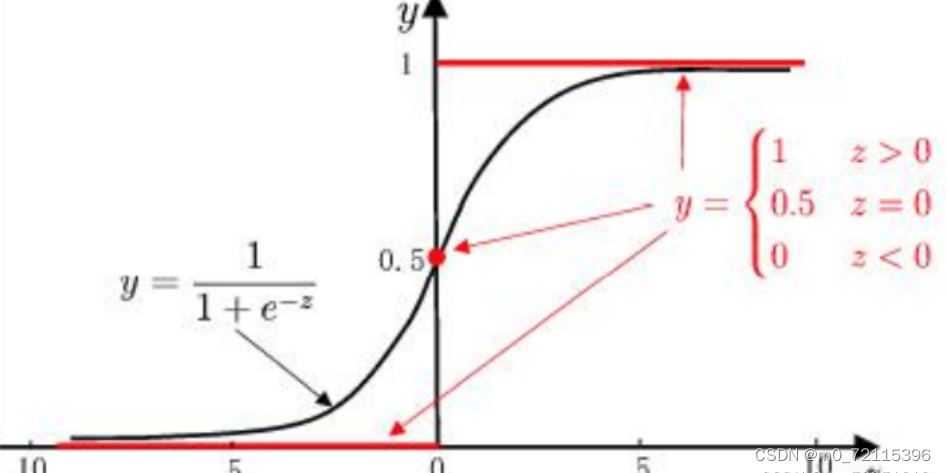
所以,为了实现Logistic回归分类,我们可以在每个特征上都乘以一个回归系数,然后把 所有的结果值相加,将这个总和代入Sigmoid函数中,进而得到一个范围在0~1之间的数值。任何大于0.5的数据被分入1类,小于0.5即被归入0类。所以,Logistic回归也可以被看成是一种概率估计。
4.logistic的优缺点:
优点:计算代价不高,易于理解和实现。
缺点:容易欠拟合,分类精度可能不高。
使用数据类型:数值型和标称型数据。
二、Logistic实现
1.logistic实现一般过程:
收集数据:任何方式
准备数据:由于要计算距离,因此要求数据都是数值型的,另外结构化数据格式最佳。
分析数据:采用任一方是对数据进行分析
训练算法:大部分时间将用于训练,训练的目的为了找到最佳的分类回归系数
测试算法:一旦训练步骤完成,分类将会很快
使用算法:首先,我们需要输入一些数据,并将其转化成对应的结构化数值;接着基于训练好的回归系数就可以对这些数值进行简单的回归计算,判定它们属于哪一类别;在这之后,我们就可以在输出的类别上做一些其他的分析工作。
2.代码实现:
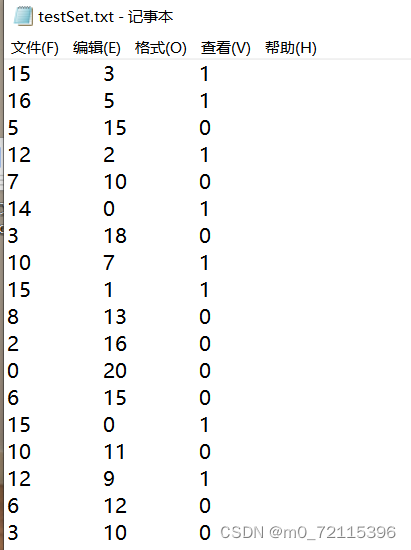
1.数据集准备:
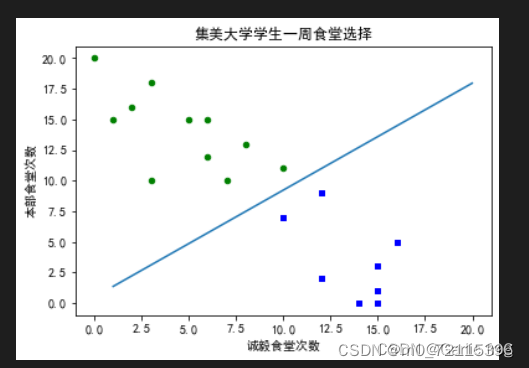
新建一个名叫testSet.txt的记事本存放数据集,第一列表示本部食堂堂食次数,第二列表示诚毅食堂堂食次数,第三列1表示学生宿舍在本部,0表示学生宿舍在诚毅。
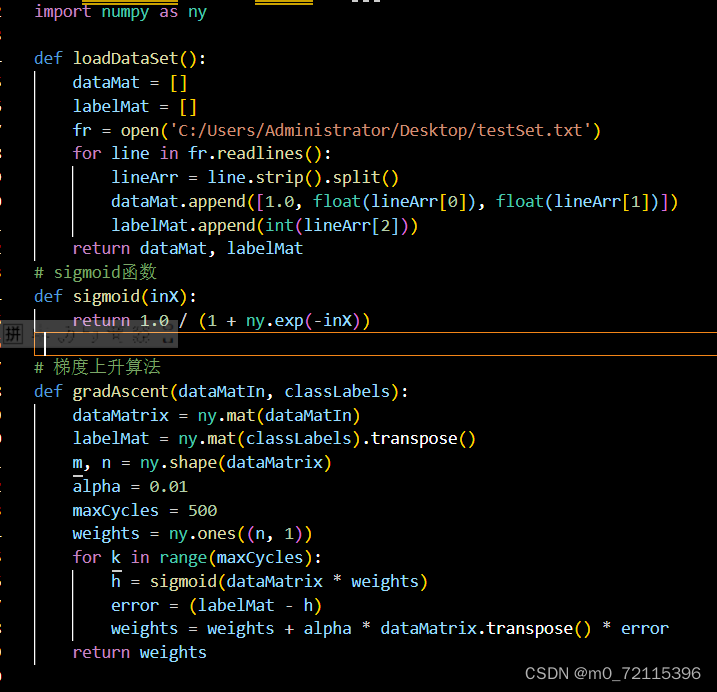
2.训练算法:
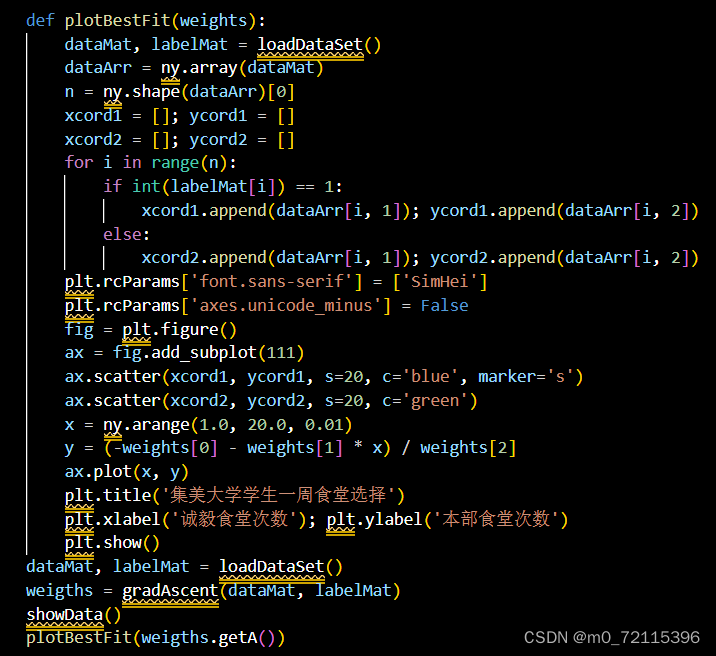
3.分析数据:画出决策边界
4.运行结果:















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









