







1. Logistic回归
1.1 概念和适用范围
Logistic回归(逻辑回归)是一种统计方法,主要用于预测二分类(多分类不常用,不做介绍,下同)结果,称为因变量,可以是某疾病是否复发、是否死亡、是否再入院等。逻辑回归的基本思想是使用逻辑函数(通常是Sigmoid函数)将线性回归模型的输出转换成概率。这种转换使得逻辑回归模型能够处理分类问题,尤其是二分类问题。
通俗来讲就是根据数据集进行分类,分类的依据标准是概率。找到一个概率阈值,例如50%:样本属于A类的概率大于50%则为A类,反之为B类。
但实际上,不是所有的数据我们都可以一股脑的将他们填充进模型内部进行训练,在统计学中,是有前置条件:这些特征需要相互独立。
1.2 回归模型
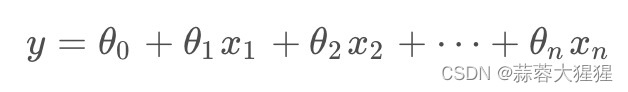
这是一个通用的回归公式,根据不同的自变量x我们得到不同的因变量值,他们之间有着线性关系。因变量是一个连续变量,取值可以任意限度。通过上述模型的定义,我们想把它限制在一个概率中,也就是将因变量的值限制在0到1之间,第一反应就是对数函数。
对数函数将因变量的数值限制在[0,1)之间,我们将函数进行变换:
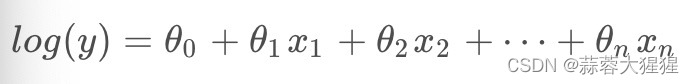
感觉万事俱备了?
但还有一个问题,作为一个二分类问题,发生了一件事那么必然另一件事没有发生。例如我是长头发,那么说明我一定不是短头发(有点废话文学那意思)。简单来说,也就是说这两个分类的概率相加一定为1。
引出几率(odd)就可以很好的将这个问题解决。
几率(odd)是指事件发生的概率与不发生的概率之比,假设事件 A 发生的概率为P,不发生的概率为1-P,那么事件 A 的几率为:

相反B的几率为1 - odd(A)。
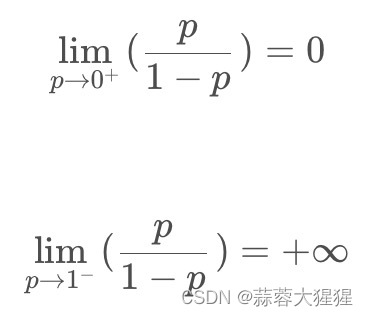
根据上述取极限的情况,这样子有一个很好的相对关系。万事俱备,只欠东风,我们将函数进行汇总一下:
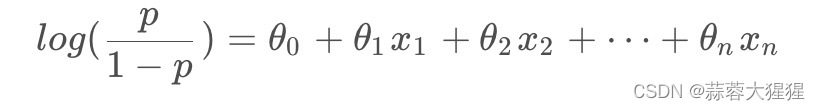
将上述公式进行化简得到我们最后的sigmoid函数:

以下为sigmoid函数图像:
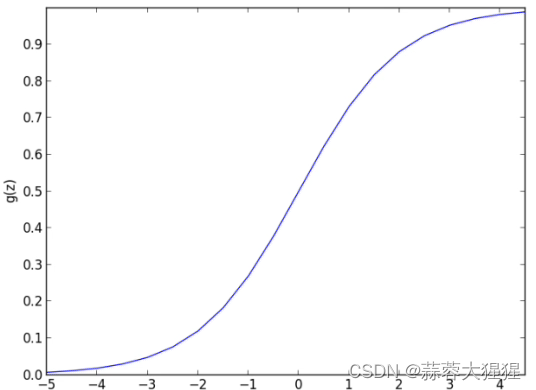
1.3 梯度上升法
所以说,Logistic算法就是找到一个合适的线性系数。
那么问题来了!如何得到合适的参数向量θ?
梯度上升法是一种很好的方式:
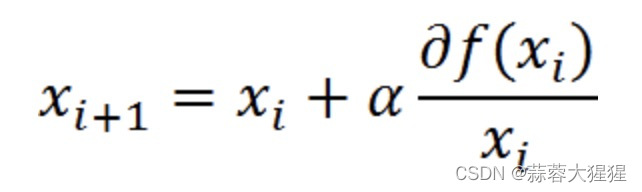
实际上就是一种迭代算法,不断去逼近函数最大值,代表步长,每次迭代向前走多少步。
梯度上升法求解:
推倒方式在这边文章就不多加细说,下面链接将梯度上升法推导讲解的简单易懂,有兴趣的可以看看。
2. 源代码算法实现
def sigmoid(inX):
return 1.0 / (1+np.exp(-inX))首先将我们的sigmoid函数实现。
def gradAscnet(dataMatIn,classLabels):
dataMatrix = np.mat(dataMatIn) #进行矩阵的创建
labelMat = np.mat(classLabels).transpose() #进行矩阵的转置
m,n = np.shape(dataMatrix)
alpha = 0.001 #定义步长
maxCycles = 500 #迭代次数
weights = np.ones((n,1)) #系数
for k in range(maxCycles):
h = sigmoid(dataMatrix*weights)
error = (labelMat - h) #误差
weights = weights + alpha*dataMatrix.transpose() * error #更新系数
return weights
gradAscnet(dataMat,classMat)我们实现梯度上升算法进行迭代系数的值,通过迭代maxCycles次数得到最终回归模型的系数值,计算出误差,再代入公式最后得到回归系数。
梯度上升算法在每次更新回归系数的时候都需要遍历整个数据集,如果有成千上万个特征这个方法的计算复杂度就太高了。随机梯度上升算法就可以很好的去解决这个问题:
def stocGradAscent0(dataMatrix,classLabels):
m,n = np.shape(dataMatrix)
alpha = 0.01
weights = np.ones(n)
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights))
error = (classLabels[i] - h)
weights = weights + alpha*error*dataMatrix[i]
return weights3. sklearn实现
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
dataMat = np.array([[99,98,1],[97,100,1],[1,2,0],[2,4,0]])
classMat = np.array([1,1,0,0])
Model = LogisticRegression()
Model.fit(dataMat,classMat)在sklearn库中配备了LogisticRegression模型,配置模型之后调用即可
可通过predict方法去预测标签种类
predict_proba函数去计算某一样本在模型中所对应的概率
模型也内置了一些属性可以获得我们想要的参数值
model.intercept_[0]:获取截距值
model.coef_[o][x]: X代表我们想要获得的第几个系数值
4. 进一步探究
4.1 决策边界
在日常学习与工作中,常常需要我们绘图画出二分类中各点的分布,以及决策边界的图像
使用x轴与y轴分别表示样本的两个属性,代表在平面的分布,决策边界即是两个属性间的函数
以概率0.5作为分解标准:
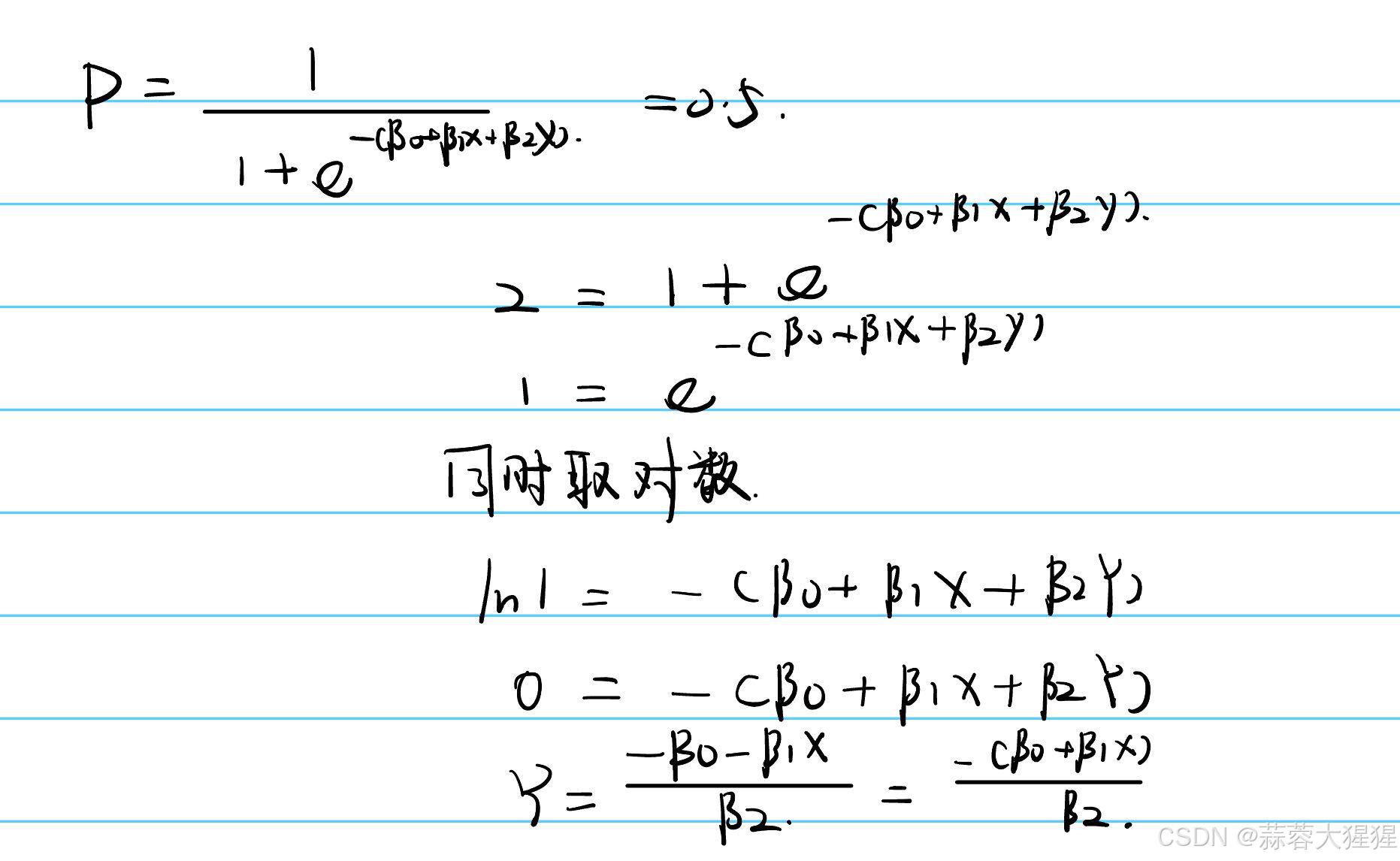
代码实现:
简单版本:
fig,axes = plt.subplots(2,figsize=(5,10))
axes[0].scatter(X_test.iloc[:,0],X_test.iloc[:,1],c=y_pred_log_reg)
xplot = np.linspace(20,100,100)
yplot = -(log_reg.intercept_[0] + log_reg.coef_[0][0]*xplot)/log_reg.coef_[0][1]
axes[0].plot(xplot, yplot, lw = 2)
axes[0].set(title="Logistic Regression's Performance on test set")
y_pred_log_train = log_reg.predict(X_train)
axes[1].scatter(X_train.iloc[:,0],X_train.iloc[:,1],c=y_pred_log_train)
xplot = np.linspace(20,100,100)
yplot = -(log_reg.intercept_[0] + log_reg.coef_[0][0]*xplot)/log_reg.coef_[0][1]
axes[1].plot(xplot, yplot, lw = 2)
axes[1].set(title="Logistic Regression's Performance on train set")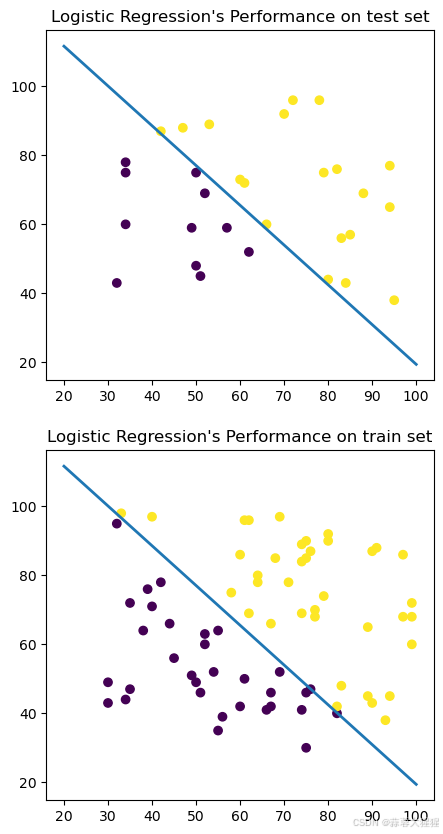
contourf版本:
#Logistic classifier
x_min, x_max = X['exam1'].min() - 1, X['exam1'].max() + 1
y_min, y_max = X['exam2'].min() - 1, X['exam2'].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
np.arange(y_min, y_max, 0.01))
Z = log_reg.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.8, cmap=plt.cm.RdYlBu)
plt.scatter(X_train['exam1'], X_train['exam2'], c=y_train, edgecolors='k', marker='o', cmap=plt.cm.RdYlBu)
plt.title("Logistic Regression Decision Boundary")
plt.xlabel('Exam 1')
plt.ylabel('Exam 2')
plt.colorbar()
plt.show()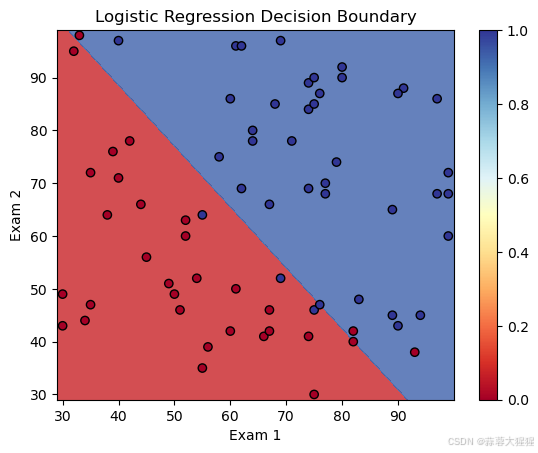
5. Logistic算法的优点与局限性
5.1 优点
1. 简单易于实现:原理很简单,也特别容易上手
2. 适用性广泛: 用于金融,医学,市场营销等领域
3. 结果容易解释:毕竟是计算概率来预测结果,也可以使用特征系数来解释特征对结果的影响
5.2 局限性
1. 多分类问题:简单的logistic回归只能处理二分类问题,不能直接应用多分类问题,需要扩展或者组合其他方式。
2. 需要大量的样本:样本量小会使得模型出现过拟合或者欠拟合的问题。
3. 线性决策边界:这是一个线性分类器,无法捕捉到复杂的非线性关系。
6. 应用场景
只要是需要进行二分类的问题,并且数据符合逻辑回归的假设条件,都可以运用Logistic回归
1. 医学: 用于疾病诊断,药物反应预测
2. 市场营销:客户分类,市场预测等
3. 生物学: 基因表达分析,蛋白质结构检测
7. 参考资料
《机器学习实战》


















 1216
1216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









