







IDEA Flink
一、IDEA 创建项目
1、导入pom 依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>flink</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.13.0</flink.version>
<target.java.version>1.8</target.java.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<dependencies>
<!-- 引入 Flink 相关依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.13.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.13.0</version>
</dependency>
</dependencies>
</project>
2、wordcount 批处理案例
思路:
首先要创建一个批处理的执行环境,需要 ExecutionEnvironment 这个类,然后调用他下面的 getExecutionEnvironment 方法。然后使用 readTextFile 方法读取数据,里面的参数是数据的路径。然后 进行扁平化处理,flatMap方法,然后map进行转换成二元组,groupby(0) 进行分组,以第一个元素作为key进行分区,最后是聚合,使用sum(1) 对第二个元素进行求和,最后打印输出使用 print() 方法,最后执行任务 execute() 方法
package com.aex.flink
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._ //要引入这个包,不然会报错
import java.util.concurrent.ExecutionException
class flink01_Wordcount {
}
//批处理的wordcount
object flink01_Wordcount{
def main(args: Array[String]): Unit = {
//创建一个批处理执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//从文件中读取数据
val inputPath = "E:\\study\\BigDatas\\Flinks\\flink\\src\\main\\resources\\hello.txt" //这是数据的路径
val inputDataSet:DataSet[String] = env.readTextFile(inputPath) //把路径传入进去
//对数据进行转换处理统计,先分词,再按照word进行分组最后进行聚合统计
val resultDataSet:DataSet[(String,Int)] = inputDataSet
.flatMap(_.split(" "))
.map(word => (word,1)) //转换一下,转换成二元组
.groupBy(0) //以第一个元素作为key,进行分组
.sum(1) //对所有数据的第二个元素求和
//打印输出
resultDataSet.print()
//执行任务
env.execute()
}
}
3、wordcount 流处理案例
思路:
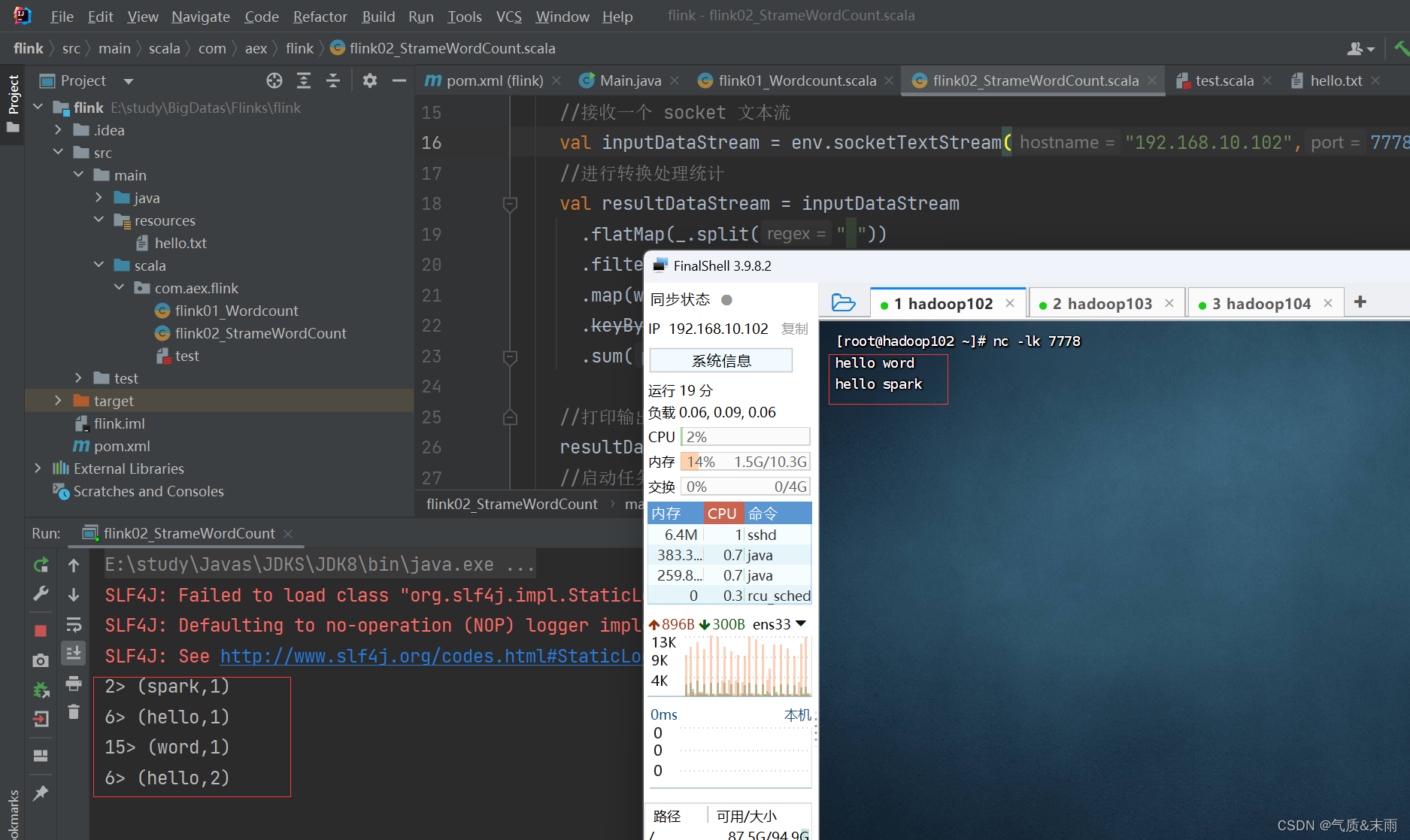
第一步当然还是创建环境,不过这个环境是流处理的环境和批处理的有一些不一样,使用 StreamExecutionEnvironment 类,调用他下面的 getExecutionEnvironment 方法,然后接下来是读取数据了,这个读取数据也和批处理的有点不一样,批处理是 readTextFile 方法,流处理是socketTextStream 方法,里面两个参数,第一个参数是主机号,第二个参数是端口号,然后接下来的步骤和批处理基本一致,使用 flatMap 方法,进行扁平化处理,使用 map 方法转换为一个二元组,接下里的分组有点不一样了,DataStream 没有groupBy 方法,但是有一个 keyBy(0) 方法,和groupBy 是一样的用法,将二元组里的第一个元素作为key进行分组,然后接下里的聚合也是一样的 sum(1) 第二个元素用来当做值进行聚合,然后print 方法进行输出,最后 env.execute() 方法执行任务
package com.aex.flink
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.streaming.api.scala._ //导入flink流处理的隐式转换
class flink02_StrameWordCount {
}
//流处理的wordcount
//流处理是DataStream API
object flink02_StrameWordCount{
def main(args: Array[String]): Unit = {
//创建流处理的执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//接收一个 socket 文本流
val inputDataStream = env.socketTextStream("192.168.10.102",7778) //里面的参数是主机名和端口号
//进行转换处理统计
val resultDataStream = inputDataStream
.flatMap(_.split(" "))
.filter(_.nonEmpty)
.map(word => (word,1))
.keyBy(0) //DataStream 里面没有groupBy 方法,但是有keyBy 方法,也是一样的,以第一个元素作为key
.sum(1) //最后聚合就是一样的了,以第二个元素作为值聚合
//打印输出
resultDataStream.print()
//启动任务执行
env.execute("stream word count")
}
}
流处理要不停的发送数据,来一个处理一个,这样才能体现出流处理的效果,我们在linux
输入命令:nc -lk 7778 监听7778端口发送的数据,linux 发送一个数据,IDEA程序就会接收到














 7237
7237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









