






技术应用领域:
图像去模糊技术不仅在数字图像处理领域有着巨大的潜力,还在许多实际应用中发挥着关键作用。以下是一些应用领域以及一些具体实例:
1.医学成像:在医学成像中,清晰的图像对于准确的诊断和手术至关重要。图像去模糊可用于提高MRI、CT扫描和超声图像的质量,使医生能够更好地识别异常或病变。
2.摄影:摄影师和摄影爱好者可以受益于图像去模糊技术,尤其是在拍摄运动中的快速场景或低光条件下。这有助于提高照片的清晰度和质量,减少模糊和震动。
3.安全监控:在监控系统中,清晰的图像可以提供更好的监视和识别能力。例如,对于安全摄像头,去模糊技术可以帮助识别入侵者或犯罪嫌疑人的面部特征。
4.卫星图像分析:卫星图像在地球科学、农业、城市规划和气象学等领域中广泛使用。图像去模糊技术可以帮助提高卫星图像的分辨率,使研究人员更容易分析和提取信息。
5.计算机视觉:图像去模糊在计算机视觉中扮演着关键角色。例如,在自动驾驶中,清晰的图像对于道路和障碍物的检测至关重要。人脸识别系统也可以受益于清晰的图像,提高了身份识别的准确性。
6.博物馆和文化遗产保护:博物馆和文化遗产机构使用图像去模糊来恢复老旧或损坏的艺术品和文物的图像。这有助于保护和传承文化遗产。
图像模糊分类:
大气模糊(Atmospheric Blur)
是模糊图像复原技术研究领域提到的相对较少的一种模糊形式。他源于光学湍流和气溶胶造成的小角散射。光学端流是由于大气中的某些属性因随机的时空变化引起的,如温度和密度的光折射的变化 同时,不同大小的化学物质也对不同类型的、不同波长的光波具有不同的散射性。再大气科学中,这种现象通常被称作为气溶胶散射。光学端流和气溶胶散射这两个主要原因导致了图像信号在空间传递中的混合,造成了图像模糊。大气模糊目前在大气科学、 卫星成像和遥感成像等领域主要的研究主题。
散焦模糊(Out-of-Focus Blur)
也通常被称为光学模糊,光圈是产生散焦模糊的主要原因,小孔成像是不存在散焦模糊的问题,由于大光圈的使用,不在焦平面上的物体,会产生散焦模糊,并且越远离焦平面,被拍摄的物体在图像中就会成像越模糊。
运动模糊(motion blur)
的产生是因为在一次曝光时间内,由于运动使得整个场景 或者拍摄目标产生了拖影。运动的产生主要是因为两个因素, 一是拍摄目标的快速移动, 二是拍摄过程中照相机本身的晃动。尤其在低照度环境下,这个问题会变得更加突出,因为光线较暗的时候,需要通过较长的曝光时间来获得高信噪比、亮度适中的图像,这就需要增加曝光的时间。然而,在长曝光情况下很难保持手持照相机的稳定 。一旦照相机因为某种原因发生抖动,被拍摄的目标本身的像素会在运动的反方向出现多个像素的拖影,去除运动模糊的目标就是要将这些拖影去除。
卷积和图像之间的关联:
卷积和图像之间存在着紧密的关联性。卷积是一种数学运算,它在图像处理中被广泛应用。在图像处理中,卷积可以用来模糊图像、增强图像细节、边缘检测等。
卷积的基本思想是通过将一个滤波器(也称为卷积核)应用于图像的每个像素,通过计算像素周围的邻域像素的加权平均值来改变图像的特征。这个滤波器可以根据需要进行设计,以实现不同的图像处理效果。
在计算机视觉中,卷积神经网络(CNN)是一种深度学习模型,它的核心操作就是卷积。CNN广泛应用于图像识别、目标检测和图像生成等任务中。通过卷积操作,CNN可以从图像中提取特征,并通过这些特征进行后续的分类、检测或生成等任务。
因此,卷积和图像之间的关联性体现在卷积在图像处理和计算机视觉中的广泛应用,以及卷积操作对图像特征的提取和处理能力。
去模糊技术的处理:
首先,镜头的缺陷有两类:
像差,包括色差和球差:
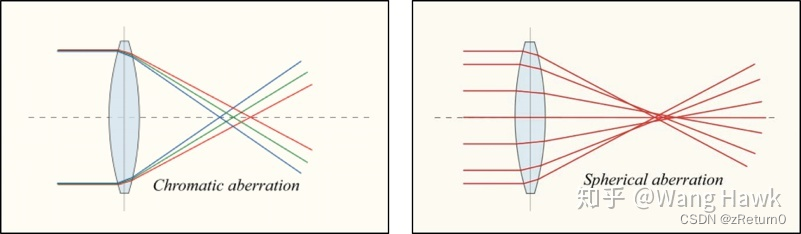
衍射:

我们可以认为这种效应是空间不变的,即空间中任何一点在任意一个像平面上都会呈现同样的缺陷——即你用相机拍出的照片永远是不够清晰的。在这篇文章中,我们先忽略掉像差,只考虑衍射。那么一个理想的小点通过圆形光圈后的PSF会呈现出一种特别的形态,这是一种叫做Airy Pattern的图像,这种因为衍射形成的PSF我们称之为衍射极限PSF(Diffraction Limit PSF)

而如果对此PSF做傅里叶变换,就可以得到这个镜头的光学传递函数OTF(Optical Transfer Function),它长这个样子:

那么镜头的PSF或OTF,对于成像的具体影响是什么呢?
假设有一个理想镜头,不受衍射的影响,用它所成的像为x, 而实际镜头的PSF为c, 实际镜头的成像是b,那么这三者之间的关系是一种典型的卷积关系:

这里就是大家熟知的去卷积技术,但是需要提前知道PSF,这可就难了。确实,很多情况下提前测定PSF是根本不可能的,有可能你手上只拿到了一张很模糊的照片b,不知道c,想要恢复出x,这时候应该怎么办呢?

这就是本次实验所要提及的技术:
盲去卷积技术(Blind Deconvolution)
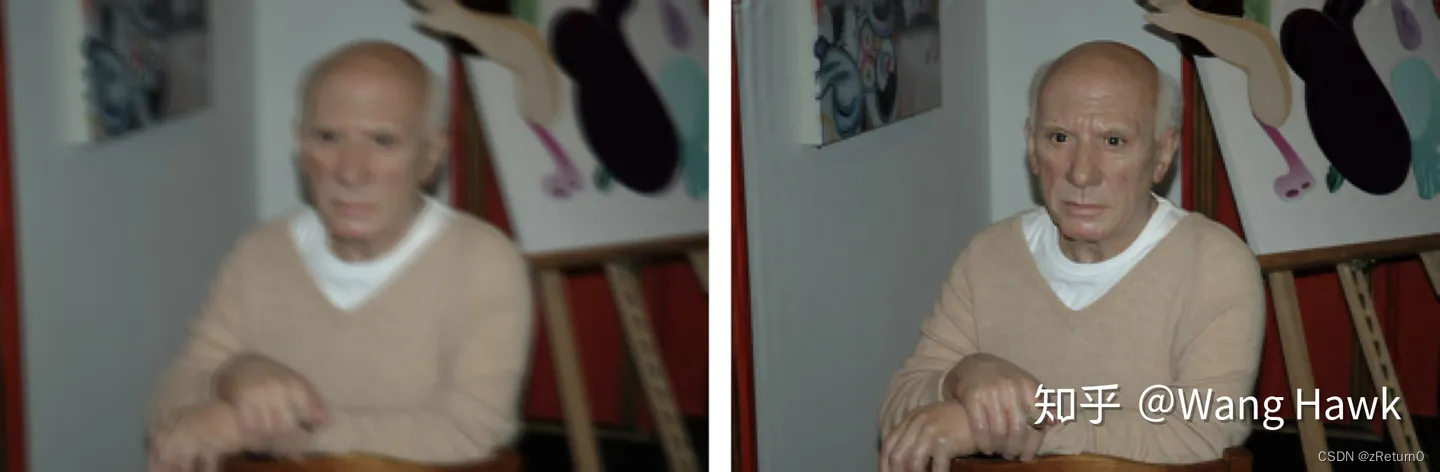
盲去卷积技术的理论介绍:
已知模糊图像P,未知图像为L,未知的卷积核为K。一个基本的想法是把问题看做是求最大后验概率的问题:(MAP算法)
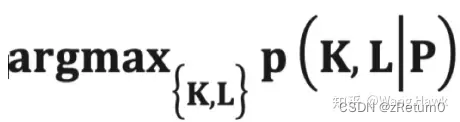
但是实际处理中,MAP的处理效果并不好,而在2009年的下面这篇著名论文中,作者Levin教授则提出了更深入的见解。
Levin et al., “Understanding and evaluating blind deconvolution algorithms,” CVPR 2009 and PAMI 2011
Levin教授认为用MAP目标函数同时求解K和L肯定不好,有如下的原因:
1.错误的单位卷积核比起正确的稀疏卷积核的可能性更高(Levin的论文中有证明)
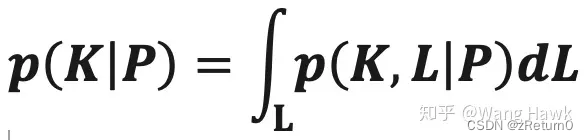
2.上述MAP目标函数的变量个数具有高度的非对称性,比如对于这幅毕加索照片:

可见已知量的个数总是小于未知量的个数 #P < #L + #K
以上两个原因就会导致用这种同时估计K和L的目标函数来做MAP总是无法得到好的结果。那有没有更好的方法呢?

Levin认为,更好的办法是只单独估计K,即把下面左边的问题转换为右边的问题
这样,已知量的个数就远远大于未知量的个数 #P >> #K
这里的p(K|P)是相对于L的边际概率,即:
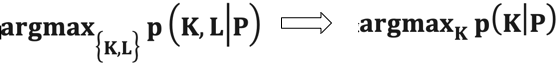
简单来说,就是对每一个可能的K,我们都要在所有可能的L上求取其后验概率,并把这些后验概率值加起来,得到p(K|P)。你应该可以感觉到求这样的边际概率也是很不容易的事情,计算量非常复杂。于是很多学者采用了近似的方式来进行求解。
盲去卷积技术在python的实际复现:
前言:
采用的算法是:Richardson-Lucy算法
盲反卷积算法可以同时恢复图像合点扩散函数(PSF)
LR算法是时域的迭代非线性复原算法,基于贝叶斯理论,泊松分布和最大似然估计算法对图像进行修复。
当下面这个迭代收敛时,模型的最大似然函数就可以得到一个令人满意的方程:
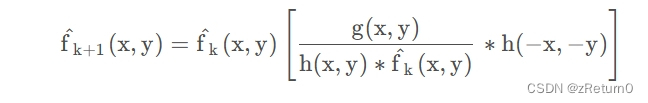
其中:* 代表卷积,f^代表未退化的图像估计,h(x,y)为退化矩阵,
该函数求解过程用到了极大似然法和EM算法:
[J,PSF] = deconvblind(I,INITPSF)使用最大似然算法对图像I解卷积,返回去模糊图像J和恢复的点扩散函数PSF。 生成的PSF是与INITPSF相同大小的正数组,归一化,所以它的总和增加到1。PSF的恢复受其初始猜测大小INITPSF的影响较大,而其值较小(一个数组是一个更安全的猜测)。
库的导入:
cv2: OpenCV库,用于图像处理。教程详见:Python用pip 安装cv2模块(使用镜像)
numpy: 用于进行数值计算。教程详见:Python的Numpy库下载及安装
预处理图像:
卷积核生成函数:
fspecial_Gaussian(KernelWH, sigma):
这个函数创建一个高斯模糊核。
输入:KernelWH 是核的大小(宽度和高度),sigma 是高斯核的标准差。
输出:高斯模糊核
def fspecial_Gaussian(KernelWH,sigma):
r, c = KernelWH
return np.multiply(cv2.getGaussianKernel(r, sigma), (cv2.getGaussianKernel(c, sigma)).T)卷积函数:
bluredImg(src):
这个函数对输入图像进行高斯模糊处理。
输入:src 是待模糊处理的图像。
输出:高斯模糊后的图像。
def bluredImg(src):
GausBlurImg = cv2.GaussianBlur(src,(7 ,7), 3)
return GausBlurImg估计卷积核K和盲去卷积:
盲去卷积函数:
RL_deconvblind(img, PSF, iterations):
这是一个盲去卷积算法,使用Richardson-Lucy算法进行图像去卷积。盲去卷积是指在不了解模糊核的情况下,尝试恢复原始图像。
输入:img 是待去卷积的图像,PSF 是点扩散函数(模糊核),iterations 是迭代次数。
输出:恢复后的图像。
def RL_deconvblind(img,PSF,iterations):
img = img.astype(np.float64)
PSF = PSF.astype(np.float64)
init_img = img
PSF_hat = flip180(PSF)
for i in range(iterations):
est_conv = conv2(init_img,PSF,'same')
relative_blur = img / est_conv
error_est = conv2(relative_blur,PSF_hat, 'same')
init_img = init_img* error_est
return np.uint8(normal(init_img))其他:
flip180(arr):
这个函数将二维数组翻转180度。它首先将数组展平为一维,然后翻转这个一维数组,最后再将其重新塑造为原始的二维形状。
def flip180(arr):
new_arr = arr.reshape(arr.size)
new_arr = new_arr[::-1]
new_arr = new_arr.reshape(arr.shape)
return new_arrnormal(array):
这个函数将数组中的值归一化到0-255的范围内,以适应8位无符号整数范围。对于小于0的值设为0,对于大于255的值设为255。
def normal(array):
array = np.where(array < 0, 0, array)
array = np.where(array > 255, 255, array)
array = array.astype(np.int16)
return array主程序部分:
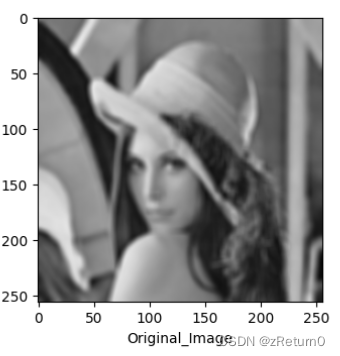
首先,读取一张图片并对其进行高斯模糊处理。
然后,对图像的每个颜色通道(蓝色、绿色和红色)进行盲去卷积处理。
最后,将三个通道的去卷积结果合并为一个完整的图像,并使用matplotlib显示原始图像和去卷积后的图像。
if __name__ == '__main__':
path = r"C:\Users\Administrator\Desktop\photos\1.jpg"
image1 = cv2.imread(path)
image = bluredImg(image1)
b_gray, g_gray, r_gray = cv2.split(image.copy())
Result1 = []
iterations = 20 #迭代次数
PSF = fspecial_Gaussian((5, 5), 1)
for gray in [b_gray, g_gray, r_gray]:
channel1 = RL_deconvblind(gray, PSF, iterations)
Result1.append(channel1)
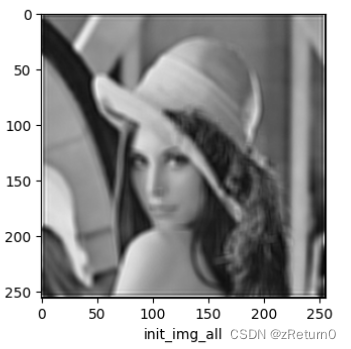
init_img_all = cv2.merge([Result1[0], Result1[1], Result1[2]])
plt.figure(figsize=(8, 5))
plt.gray()
imgNames = {"Original_Image": image,
"init_img_all": init_img_all,
}
for i, (key, imgName) in enumerate(imgNames.items()):
plt.subplot(121 + i)
plt.xlabel(key)
plt.imshow(np.flip(imgName, axis=2))
plt.show()
结果展示:
输出截图:

原图:

进行高斯模糊处理后的图片:
进行盲区卷积去模糊处理后的图片:















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









