



 本文详细介绍了KNN算法的基本原理、距离计算、K值选择、非参数性和惰性特性,以及MATLAB实现示例。探讨了KNN在不同场景下的适用性和局限性,包括数据特征、样本数量、分布和决策边界复杂性等因素。
本文详细介绍了KNN算法的基本原理、距离计算、K值选择、非参数性和惰性特性,以及MATLAB实现示例。探讨了KNN在不同场景下的适用性和局限性,包括数据特征、样本数量、分布和决策边界复杂性等因素。
一、KNN简介
KNN算法,即K-Nearest Neighbors,是一种常用的监督学习算法,可以用于分类问题,并且在实际应用中取得了广泛的成功。
二、KNN算法的基本原理
对于给定的测试样本,KNN算法首先计算它与训练集中所有样本的距离。然后,根据这些距离,选择最近的K个邻居进行投票。对于分类任务,通常取前K个样本中类别最多的作为预测结果。
2.1、距离的定义

2.2、K的取值
K的取值比较重要,那么该如何确定K取多少值好呢?答案是通过交叉验证(将样本数据按照一定比例,拆分出训练用的数据和验证用的数据,比如8:2拆分出部分训练数据和验证数据),从选取一个较小的K值开始,不断增加K的值,然后计算验证集合的准确率,最终找到一个比较合适的K值。 和K-means不一样,当K值更大的时候,错误率会更高。这也很好理解,比如说你一共就35个样本,当你K增大到30的时候,KNN基本上就没意义了。且K值一般取奇数,这样可以保证能够取到标签的众数。在下图中K值很明显取K = 3。
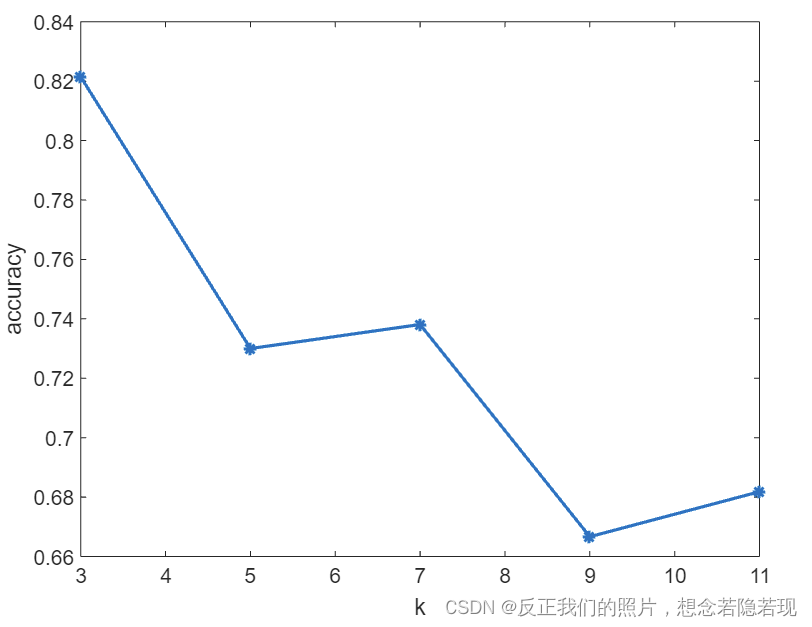
三、KNN是一种非参的,惰性的算法模型
非参的意思并不是说这个算法不需要参数,而是意味着这个模型不会对数据做出任何的假设,与之相对的是线性回归(我们总会假设线性回归是一条直线)。也就是说KNN建立的模型结构是根据数据来决定的,这也比较符合现实的情况,毕竟在现实中的情况往往与理论上的假设是不相符的。惰性又是什么意思呢?想想看,同样是分类算法,逻辑回归需要先对数据进行大量训(tranning),最后才会得到一个算法模型。而KNN算法却不需要,它没有明确的训练数据的过程,或者说这个过程很快。
四、KNN算法的优缺点
不对数据分布做出假设,完全基于距离度量对样本特征进行提取;不需要提前进行训练,直接可以进行分类;思想简单,应用广泛。然而,它也有一些缺点,如过度依赖距离度量函数和K值的选择、计算量大、所需内存大、可解释性差、预测速度慢等。
五、自己编写KNN算法的MATLAB实现并可视化
clear;clc;clf;
% 假设我们有一些训练数据和测试数据
train_data = [1.0,1.2;
1.2,1.2;
1.35,1.8;
1.3,1.6;
1.33,1.5;
1.7,2.0;
2.2,2.0;
2.1,2.5;
2.3,4.3;
2.5,4.1;
2.7,3.0;
3.2,4.4;
3.5,4.1;
4.1,5.0;
3.9,4.2;
3.7,4.4;
3.5,4.0;
4.2,1.2;
4.3,1.3;
5.0,2.6;
5.6,3.6;
5.4,4.0;]; % 训练数据的特征矩阵
train_labels = [0;0;0;0;0;0;0;0;0;0;0;1;1;1;1;1;1;2;2;2;2;2]; % 训练数据的标签向量
test_data = [ 5.8,3.6;
3.0,3.0;
1.1,2.3;
1.0,1.0;
1.2,4.0;
5.2,2.0;
3.7,4.0;]; % 测试数据的特征矩阵
K = [3,5,7,9,11];
accuracy_value = zeros(1,5);
rng(111) %固定随机数种子
for j = 1:5
% 假设 X 是你的特征矩阵,大小为 [NxD],其中 N 是样本数,D 是特征数
% 假设 Y 是你的标签向量,大小为 [Nx1]
% 设定k折交叉验证的k值
k = K(j);
% 创建k折交叉验证的分区
cvp = cvpartition(size(train_data, 1), 'KFold', k);
% 初始化用于存储结果的变量
accuracy = zeros(1, k); % 用于存储每次迭代的准确率
% 循环进行k次训练和测试
for i = 1:cvp.NumTestSets
% 训练集和测试集的索引
trainingIdx = training(cvp, i);
testIdx = test(cvp, i);
% 从原始数据中分离训练和测试数据
XTrain = train_data(trainingIdx, :);
YTrain = train_labels(trainingIdx);
XTest = train_data(testIdx, :);
YTest = train_labels(testIdx);
% 假设你已经有了预测标签,存储在变量 predictedLabels 中
predictedLabels = knn_classifier(XTrain,YTrain,XTest,k);
% 计算准确率
correct = sum(predictedLabels == YTest);
accuracy(i) = correct / length(YTest);
end
% 计算平均准确率
meanAccuracy = mean(accuracy);
accuracy_value(j) = meanAccuracy;
end
figure(1)
plot(K,accuracy_value,'LineWidth',1.5,'Marker','*')
xlabel('k')
ylabel('accuracy')
[L,I] = max(accuracy_value);
K = K(I);
% 调用KNN分类器函数
predicted_labels = knn_classifier(train_data, train_labels, test_data, K);
% 显示预测结果
disp(predicted_labels);
figure(2)
indices1 = find(train_labels==0);
indices2 = find(train_labels==1);
indices3 = find(train_labels==2);
h1 = scatter(train_data(indices1,1),train_data(indices1,2),25,"red","filled");
hold on
h2 = scatter(train_data(indices2,1),train_data(indices2,2),25,"blue","filled");
h3 = scatter(train_data(indices3,1),train_data(indices3,2),25,"green","filled");
indices11 = find(predicted_labels==0);
indices22 = find(predicted_labels==1);
indices33 = find(predicted_labels==2);
h11 = scatter(test_data(indices11,1),test_data(indices11,2),"red","o",'LineWidth',1.5);
h22 = scatter(test_data(indices22,1),test_data(indices22,2),"blue","o",'LineWidth',1.5);
h33 = scatter(test_data(indices33,1),test_data(indices33,2),"green","o",'LineWidth',1.5);
% % 创建网格以可视化决策边界
xMin = min(train_data(:,1));
xMax = max(test_data(:,1));
yMin = min(test_data(:,2));
yMax = max(train_data(:,2));
h = 0.02;
[xx, yy] = meshgrid(xMin:h:xMax, yMin:h:yMax);
% 预测网格点的标签
labels = knn_classifier(train_data, train_labels,[xx(:), yy(:)],K);
labels = reshape(labels, size(xx));
alpha = 0.2;
contourf(xx, yy, labels, 'LineWidth',1.5,'FaceAlpha',alpha); % 绘制决策边界
title(['KNN Decision Boundary (K = ' num2str(K) ')']);
xlabel('Feature 1');
ylabel('Feature 2');
box on
function label = knn_classifier(train_data, train_labels, test_data, K)
% train_data: 训练数据的特征矩阵,大小为 [NxD],其中N是样本数,D是特征维度
% train_labels: 训练数据的标签向量,大小为 [Nx1]
% test_data: 测试数据的特征矩阵,大小为 [MxD]
% K: 最近邻居的数量
% label: 测试数据的预测标签向量,大小为 [Mx1]
%——————————————————————————————————————————————————————————————
% 初始化预测标签向量
label = zeros(size(test_data, 1), 1);
% 遍历测试数据集中的每个样本
for i = 1:size(test_data, 1)
% 计算测试样本到所有训练样本的距离
% 距离函数d(x,y)需要满足三个条件:
% ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
% d(x,y)>=0,d(x,y)==0<=>x==y(正定性)
% d(x,y)==d(y,x)(对称性)
% d(x,y)<=d(x,z)+d(z,y)(三角不等式)
%~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
distances = sum((train_data - test_data(i, :)).^2, 2); %欧氏距离
% distances = sum(abs(train_data - test_data(i, :)),2); %曼哈顿距离
% 获取距离排序后的索引
[~,sortedDistIndices] = sort(distances); %默认升序排列
% 找出最近的K个邻居的索引
neighbors_indices = sortedDistIndices(1:K);
% 提取这K个邻居的标签
neighbors_labels = train_labels(neighbors_indices);
% 统计并找出最常见的标签
[most_common_label, ~] = mode(neighbors_labels); %众数
% 将最常见的标签赋给测试样本
label(i) = most_common_label;
end
end分别运用欧氏距离和曼哈顿距离的运行结果如下图:
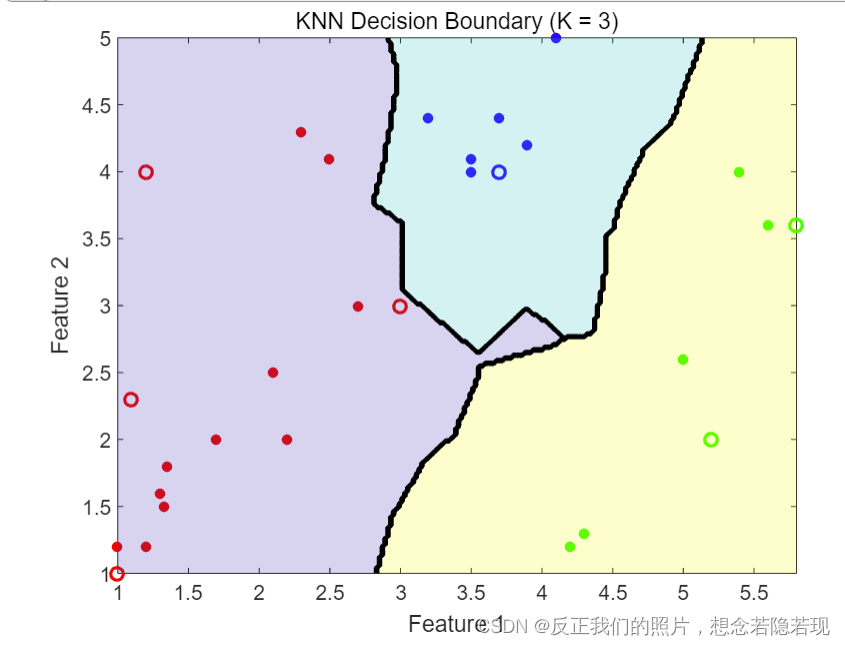
 六、KNN算法的适用范围:
六、KNN算法的适用范围:
-
数据特征明确且重要:当数据的特征空间具有清晰的边界,且特征对分类结果有显著影响时,KNN算法通常能表现出色。这是因为KNN直接基于特征空间中的距离来进行分类,所以特征的选择和表示对于算法性能至关重要。
-
样本数量适中:对于中等大小的数据集,KNN算法通常是一个有效的选择。然而,当数据集非常大时,KNN的计算成本可能会显著增加,因为需要计算每个查询点与所有训练点之间的距离。在这种情况下,可能需要考虑使用更高效的算法或数据结构来加速距离计算。
-
数据分布不均匀:KNN算法对数据的分布没有严格的假设,因此它适用于那些不符合正态分布或其他特定分布的数据集。特别是在数据分布不均匀或存在多个类别的情况下,KNN算法能够很好地处理这些复杂情况。
-
类别决策边界复杂:当类别的决策边界非常复杂或不规则时,KNN算法可能是一个好选择。由于KNN算法是基于实例的,它可以很好地捕捉数据中的局部结构和模式,从而在处理复杂决策边界时表现出色。
-
实时更新:KNN算法在需要实时更新分类模型的情况下非常有用。由于它不需要显式的训练阶段,只需存储训练数据即可,因此当新的数据点出现时,可以很容易地将其纳入分类过程中。
需要注意的是,虽然KNN算法在某些情况下表现良好,但它也有一些局限性。例如,它对特征的缩放和噪声敏感,可能需要进行特征预处理和参数调优以获得最佳性能。此外,KNN算法的计算成本随着数据集的增长而增加,因此在处理大型数据集时可能不够高效。在选择是否使用KNN算法进行分类时,需要综合考虑这些因素。

















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









