







学习的过程短期目标是丰富己身,长远来看有的人为了就业财富自由;有的则为了创造一些有意义的事物,更多的是为了前者。
此文章用于记录和总结深度学习相关算法岗的各种面试问题,搜集答案并加入博主一些浅显的理解,欢迎评论区纠正、补充。
一、经典网络架构篇
1.介绍Transformer
2.什么是Self-attention
注意力是很稀缺的,万物将注意力聚集在所获得信息的一部分上(通过感官获得的信息很多,将有限的注意力集中在少部分有用的信息上有利于资源分配而进行各种生命活动)。
注意力提示有自主性和非自住性提示。非自主性提示是基于环境中物体的突出性和易见性:如黑白色物体中一个鲜艳颜色的物体;在喝完咖啡后注意力在意志的推动下注意力聚集在黑白色书本上,这就是属于自主性提示的辅助。
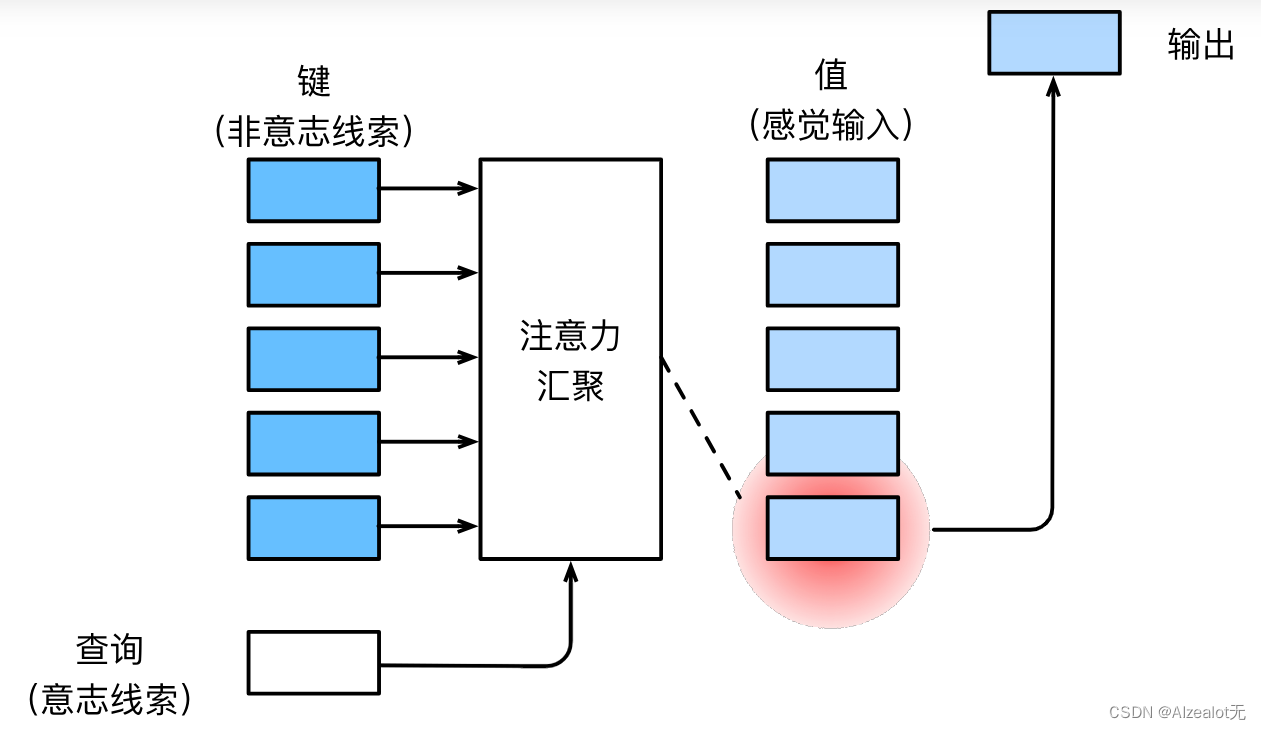
在注意力机制的背景下,自主性提示被称为查询(query)。 给定任何查询,注意力机制通过注意力汇聚(attention pooling) 将选择引导至感官输入(sensory inputs,例如中间特征表示)。 在注意力机制中,这些感官输入被称为值(value)。 更通俗的解释,每个值都与一个键(key)配对, 这可以想象为感官输入的非自主提示。 如 :numref:fig_qkv所示,可以通过设计注意力汇聚的方式, 便于给定的查询(自主性提示)与键(非自主性提示)进行匹配, 这将引导得出最匹配的值(感官输入)
查询(自主提示)和键(非自主提示)之间的交互形成了注意力汇聚; 注意力汇聚有选择地聚合了值(感官输入)以生成最终的输出
可以理解为注意力层的输出是感官输入对于自主性提示和非自主性提示的一个加权求和(映射,权重等价于query和key的相似度)成输出的过程,输出的维度和V的维度是一致的。
3.介绍Bert
4.为什么要有位置编码,你知道哪些种类的位置编码
二、通用的深度学习网络层
1.BatchNormlization和LayerNormlization的区别
二者的相同处是都是根据特征的分布对样本特征进行标准正态化(均值变成0,方差变成1)的一个过程减掉均值后除以方差,在训练的时候是对于小批量的样本进行计算,而预测的时候是在全局即所有待预测的数据上计算。
但是不同的是标准正态化过程中的均值和方差两个参数的计算目标不同:
BN的均值和方差是对于处于一个批次的所有样本的每一个特征(同一列)里面计算,同时会学习两个可调节的参数;二维情况: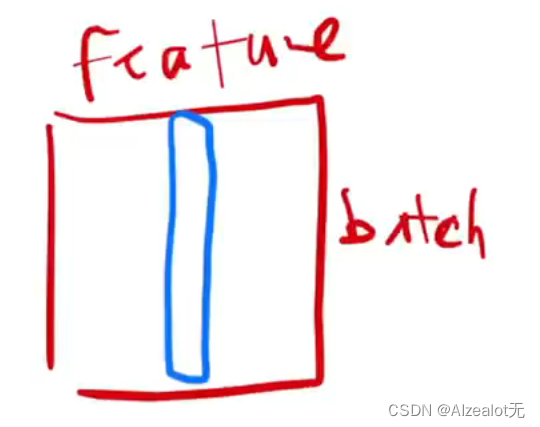
三维情况:
LN则是对于同一个样本特征的所有标量进行计算,输入为二维(特征仅是一维的情况)
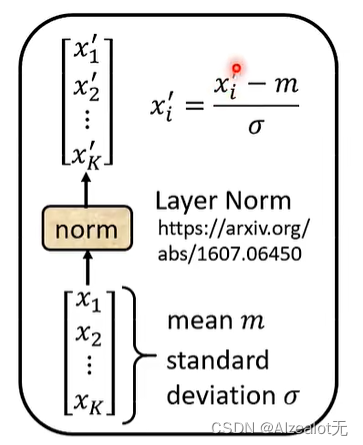
二者在输入为三维时的对比: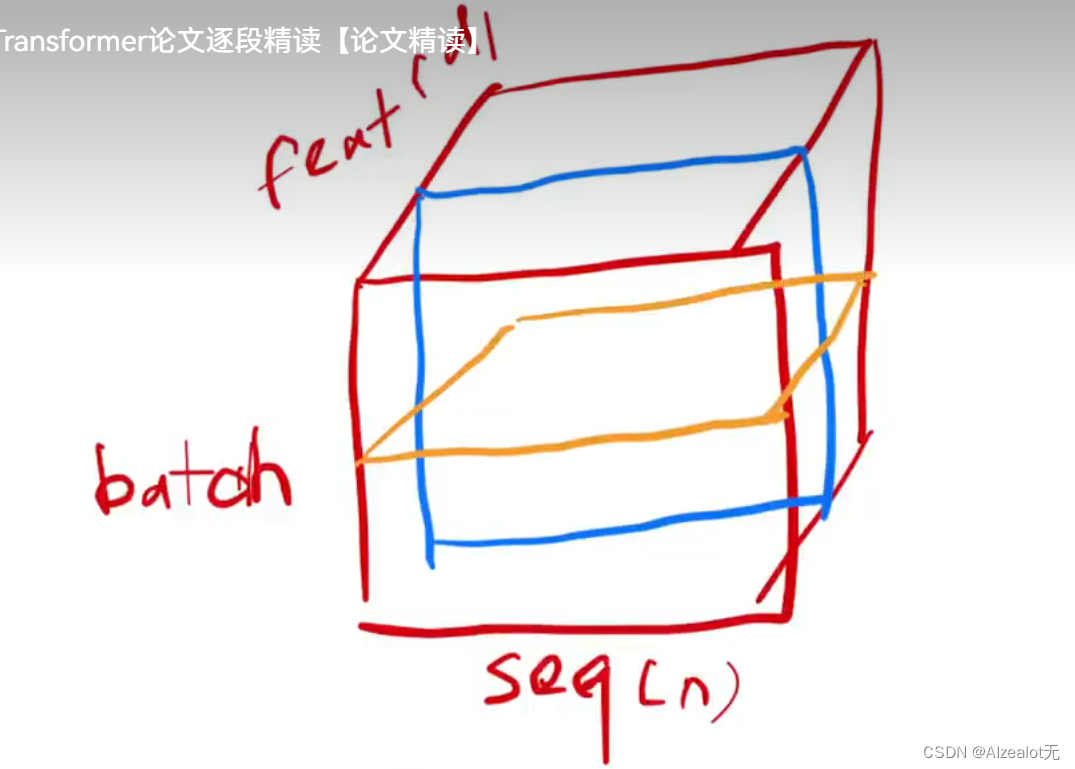
为什么在时序的问题中经常使用LN而不是BN?
如上面的立方体的输入向量示意图,由于时序问题中序列特征的长度有差异,在序列不够长时会用0来填充,而BN在进行标准正态化的过程中会使用全局的输入特征的均值和方差来进行标准正态化,但是LN只要在每个输入特征中进行这个过程,所以前者可能会由于输入特征的长度的大小的差异使得效果不够好,但是后者不存在输入特征长度差异对结果造成的负面影响。
三、优化器
四、损失函数
五、评价指标
六、微调方法
七、激活函数
1.什么是激活函数,为什么使用激活函数
激活函数(activation function)通过计算加权和并加上偏置来确定神经元是否应该被激活, 它们将输入信号转换为输出的可微运算。 大多数激活函数都是非线性的。
单纯在多层感知机模型中添加隐藏层(若不加入非线性的激活函数)没有任何好处,原因很简单:上面的隐藏单元由输入的仿射函数给出, 而输出(softmax操作前)只是隐藏单元的仿射函数。 仿射函数的仿射函数本身就是仿射函数, 但是我们之前的线性模型已经能够表示任何仿射函数,可证如下:


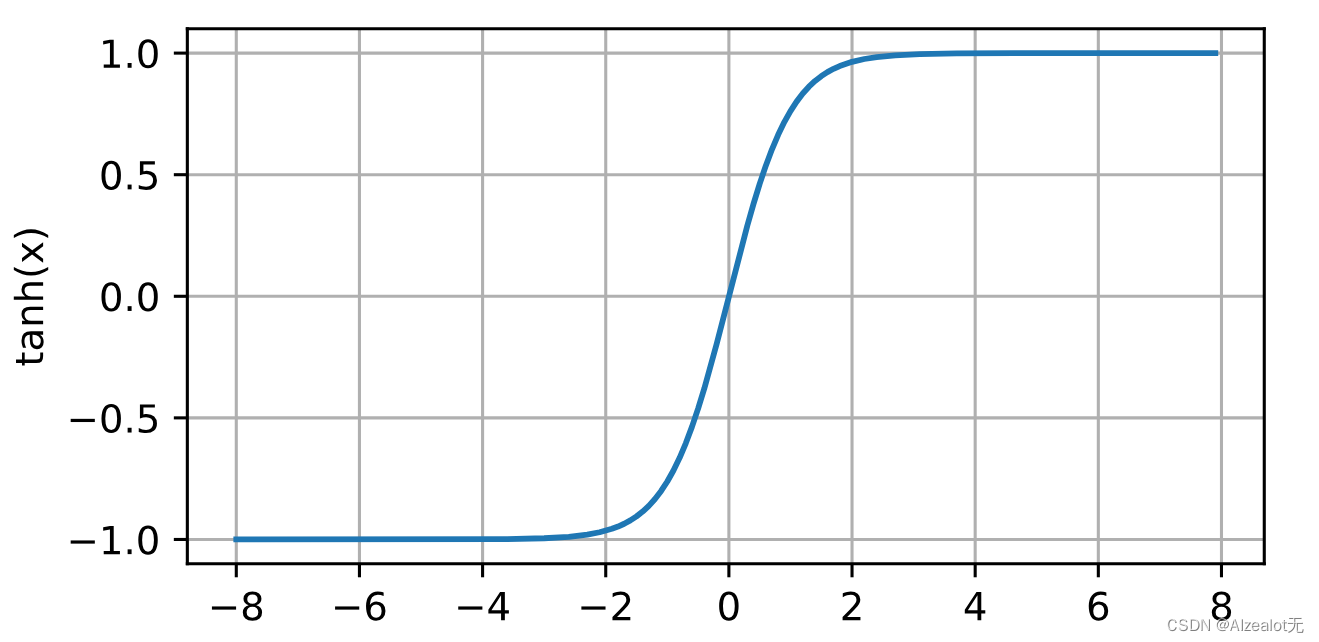
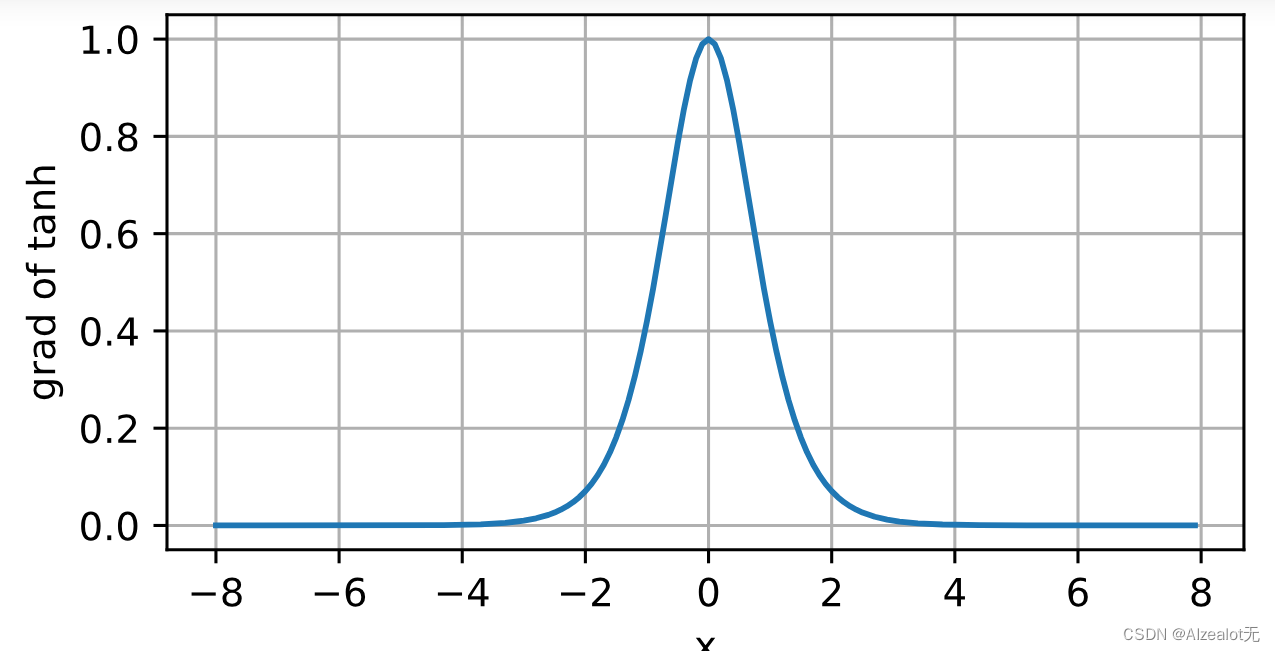
2.知道哪些激活函数,介绍一下

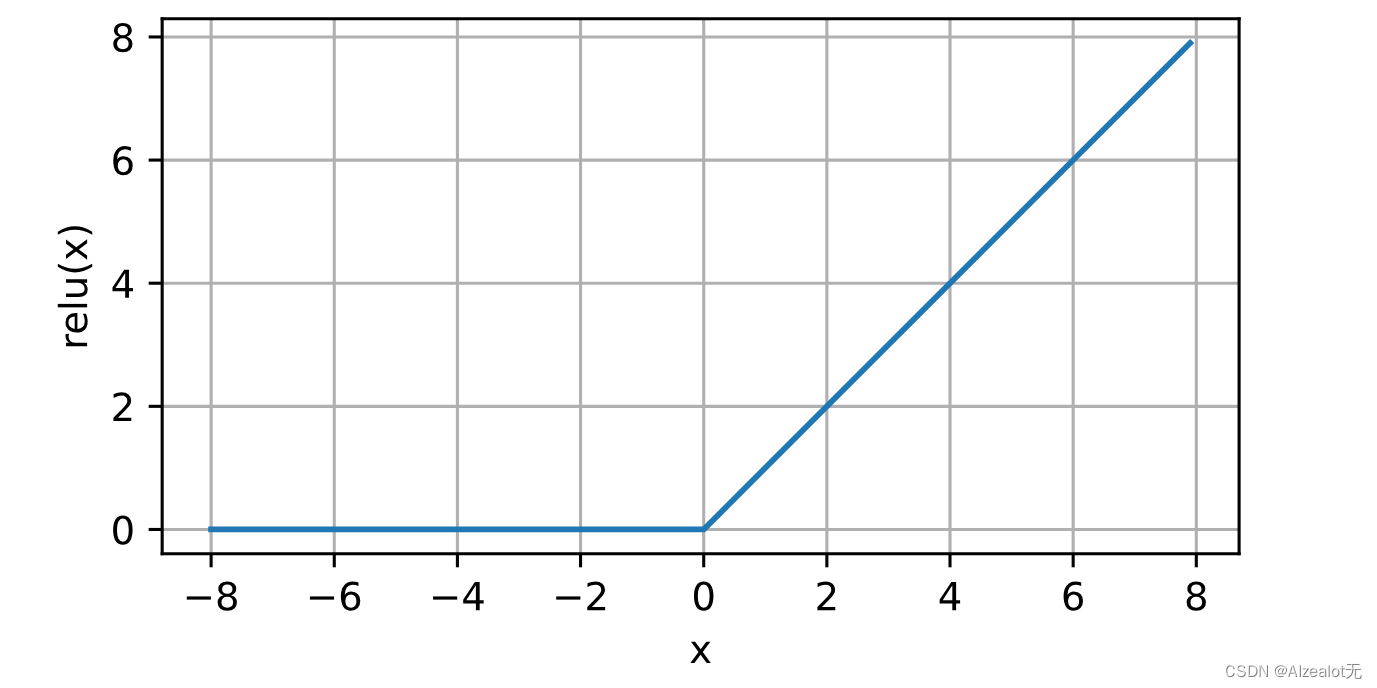
当输入为负时,ReLU函数的导数为0,而当输入为正时,ReLU函数的导数为1。 注意,当输入值精确等于0时,ReLU函数不可导。 在此时,我们默认使用左侧的导数,即当输入为0时导数为0。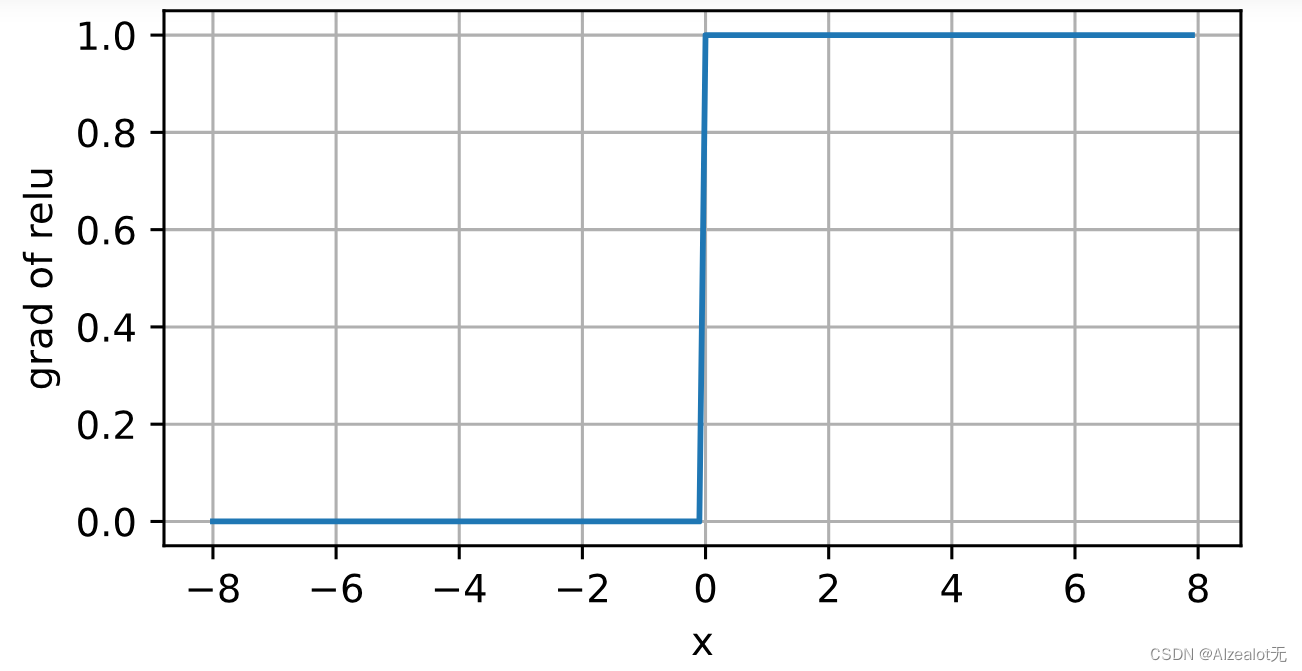
使用ReLU的原因是,它求导表现得特别好:要么让参数消失,要么让参数通过。 这使得优化表现得更好,并且ReLU减轻了困扰以往神经网络的梯度消失问题。


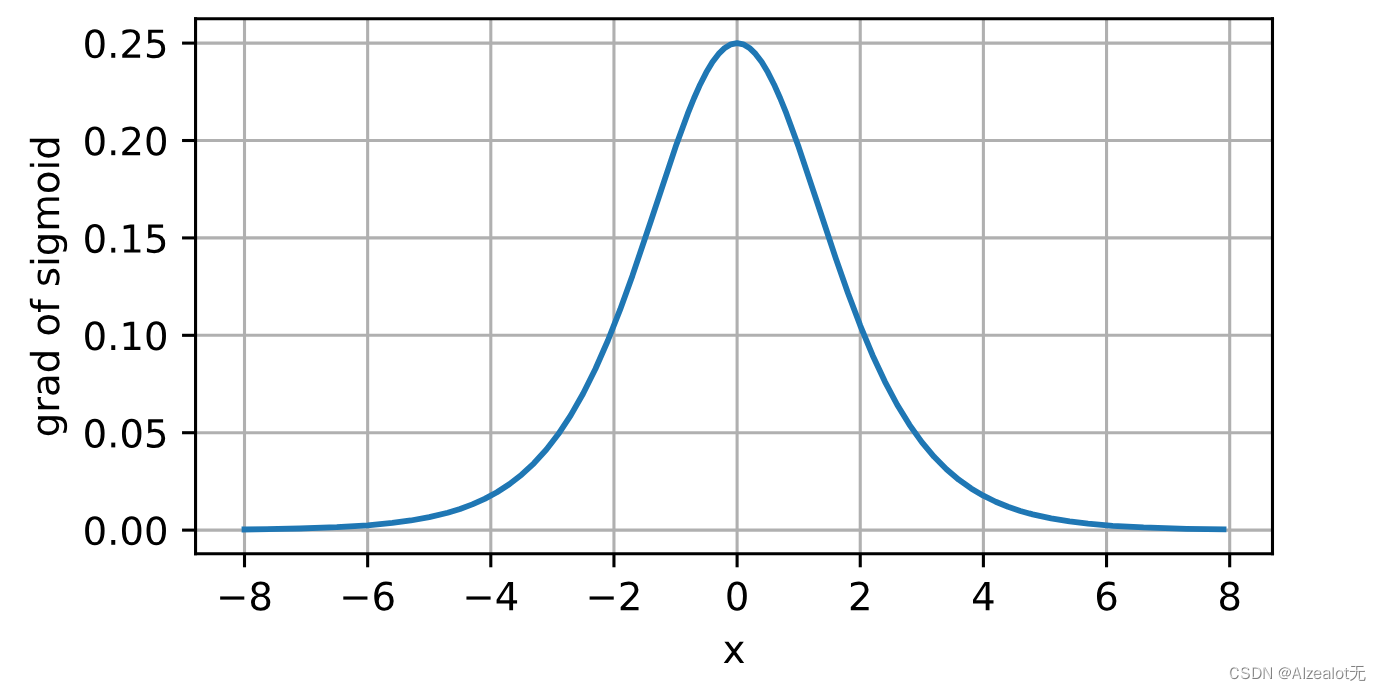
它是一个平滑的、可微的阈值单元近似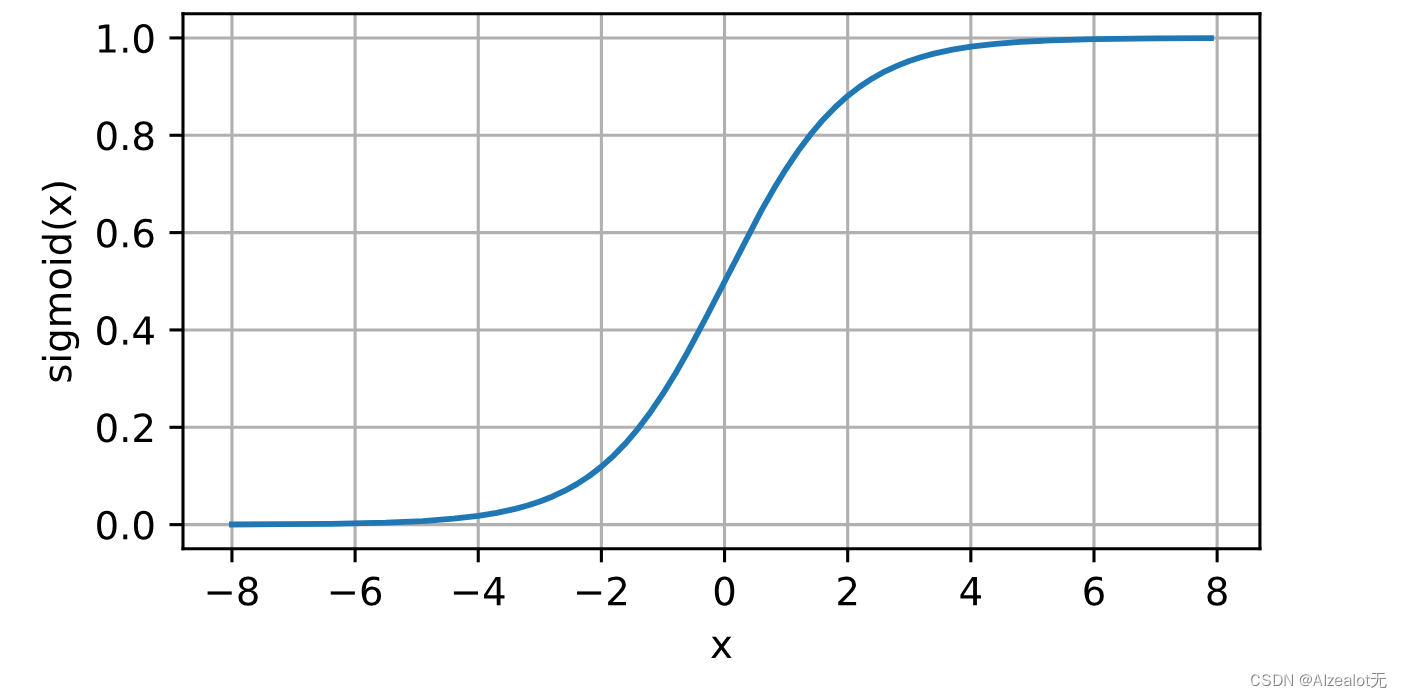
sigmoid在隐藏层中已经较少使用, 它在大部分时候被更简单、更容易训练的ReLU所取代



















 1894
1894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









