









今天解读qwen初代版本,关注其模型架构和训练流程
一、简介
初代QWEN的几个模型的版本
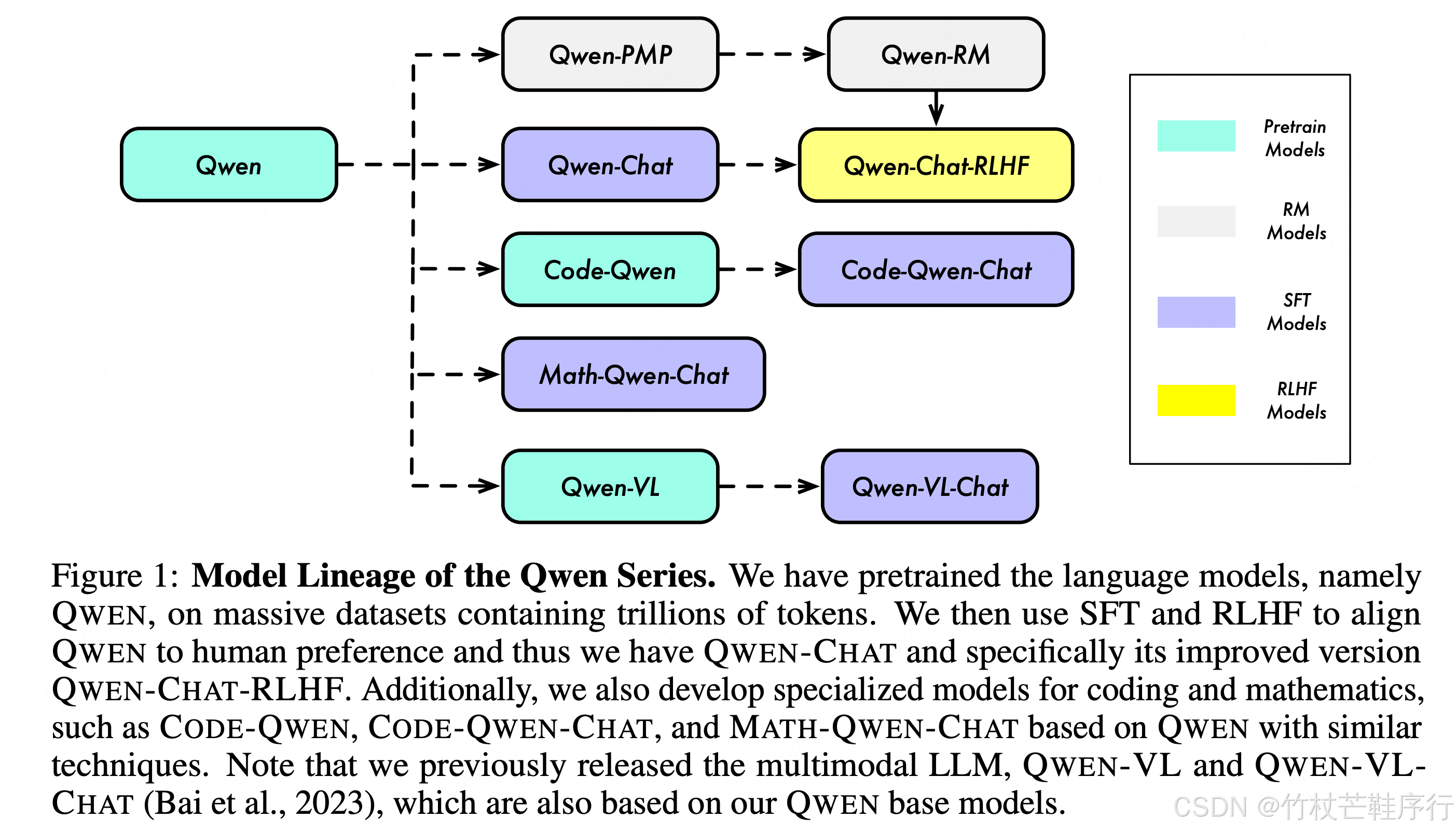
二、预训练
2.1 数据
包括网页文档、百科、书、代码
对于网页数据,从HTML提取文本,使用语言识别工具表明语言
去重:归一化后使用完全匹配、MinHash和LSH算法模糊去重
过滤:使用一些基于规则和机器学习的方法。具体来说,使用多个模型对内容进行打分,包括语言模型、文本质量打分模型、识别潜在的进攻性和不适合的内容;手动采样文本并检查
在预训练的数据中融入多任务指令以提升其表现
严格去除测试数据中的重复数据防止数据泄露
最终得到3万亿tokens
2.2 Tokenizer
采用字节对编码方法作为标记化的方法,跟随GPT,以开源的标记器——tiktoken出发,挑选词表cl100k,增加常用的中文和其他语言符号和词扩充词表,最终大小为152K左右,我记得qwen2.5的词表也差不多这么大。
2.3 模型架构
改进的Transformer,跟随LLaMA。
改进点包括:
1.输入嵌入和输出投影不共用权重矩阵,增强模型表达能力
2.位置编码采用旋转位置编码,精度提高
3.去除了除了QKV层的绝大多数的偏置,在这一层保留了一定的外推能力
4.将Pre-Norm换成了RMSNorm(即正则化操作中去除了减去均值的操作),在保证表现能力大体不变的同时提升了效率
5.将激活函数换成有Swish和GLU(门控线性单元)的SwiGLU
6.减少了前馈神经网络的隐藏层的大小(4倍——8/3倍)
三、对齐
流程为微调+人类反馈强化学习
3.1 有监督微调
对话形式的数据:多个对话prompt模板、少量人工标注的对话数据、去除不适宜的数据保证模型安全
使用ChatML-style format风格的制作。即:
这也是后续在微调Qwen时要制作的格式,后续的系列的Qwen-Instruct也是这种格式的对话数据
加入模版中的特殊token是为了让模型更好地向对话ai的模型进行转换
训练:下一个token预测的形式微调、AdamW优化器
3.2 人类反馈强化学习
整体流程:训练奖励模型——使用PPO训练策略模型
奖励模型:预训练涉及大量比较数据,比较数据包括样本对,样本对包括对同一query的不同响应以及对这些响应的偏好;微调也是这种比较的数据,由于有高质量标注所以质量更高一些。
在训练时,偏好数据的采样是从qwen模型得到,原因是这种奖励模型面向的即是此类模型风格的输出。收集了不同的尺寸的qwen模型的输出并且采用不同的采样策略以增强奖励模型的鲁棒性。
训练起始阶段,以同样尺寸的预训练QWEN模型加载,加入了一个池化层提取qwen模型对于一个句子的奖励(基于end token划分)
强化学习:包括四个模型——策略模型、价值模型、参考模型、奖励模型
在PPO前,暂停策略模型的参数更新,聚焦于价值模型,对齐进行了50步的更新,以保证价值模型可适配于不同的奖励模型
PPO:采取对每一个query进行采样两个输出的响应的采样策略,比使用固定的离线数据也就是固定的已经制作好的偏好数据集效果好
一些在训练流程中间阶段的模型对比:

原来推理的几个trick哦不,是示例能占技术报告的这么多页?!
在多个数据集上的表现对比:

效果是在偏好的评价数据集上普遍高于当时的开源模型: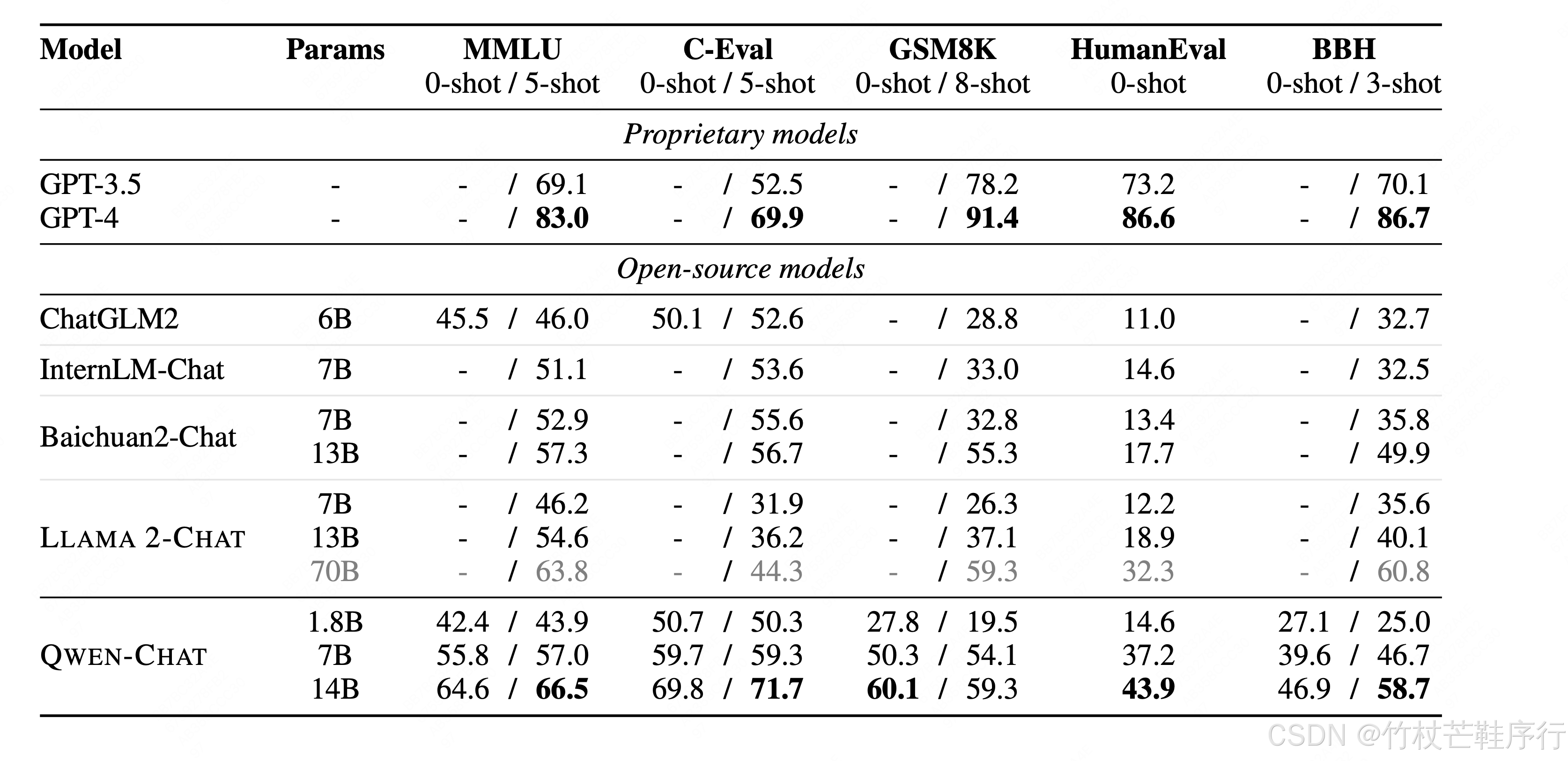
在一个完全人为制作的中文数据集上评估,对GPT3.5的三种比较情况比例: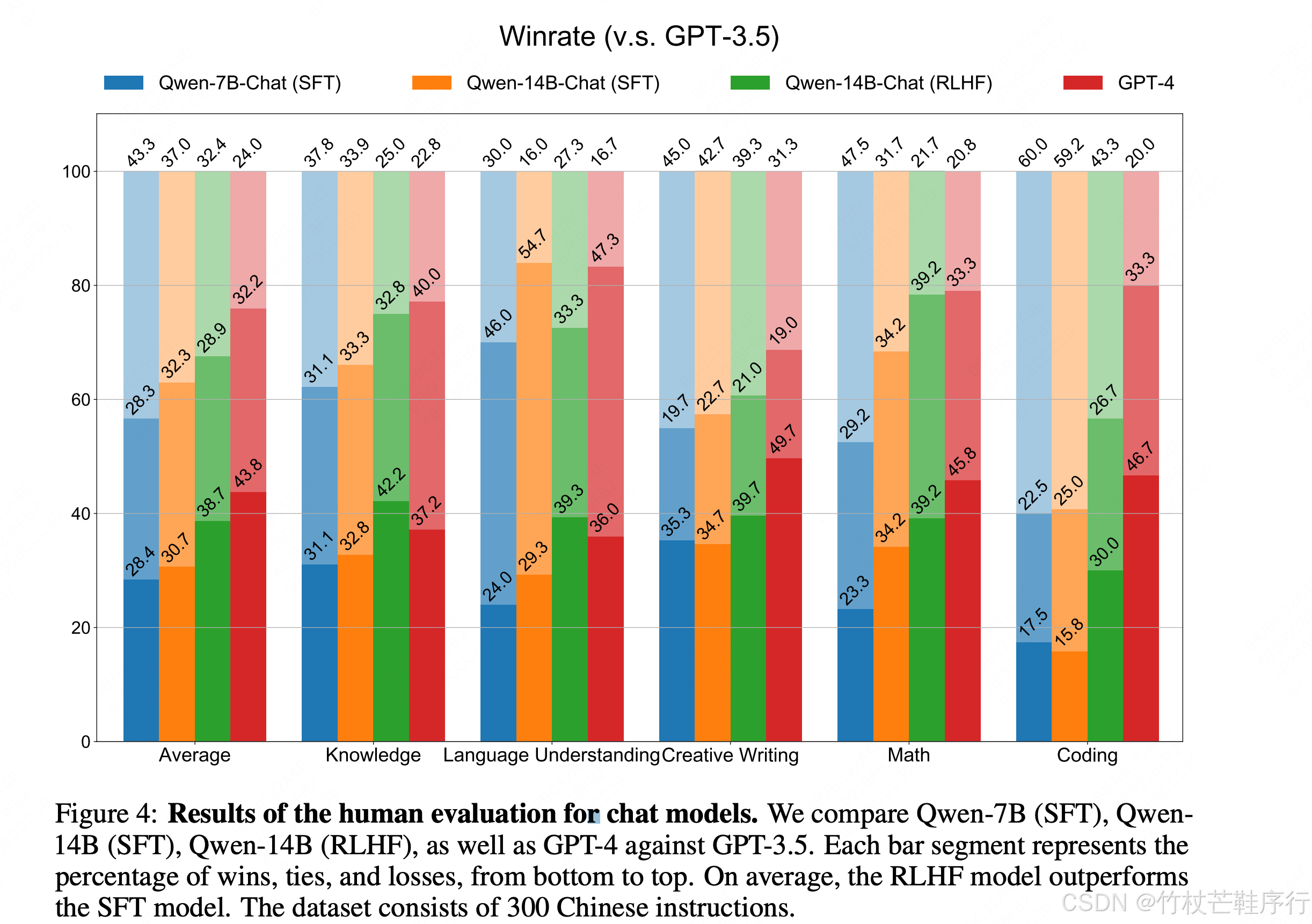


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









