







目录
一.C语言中的数据类型
(1)整型家族(char , short ,int , long)
(2)浮点型家族(double , float)

图来自菜鸟教程网站
(3)构造类型
(4)指针类型(int* , void * , char * , float*)
(5)空类型(void)
1.函数返回为空 (比如一个简单的打印函数,就不需要返回值,不返回值的函数返回类型即为空)
2.函数参数为空,有些函数,不接受参数,则参数类型可以设置为空
3.指针类型为void *,该类型指针无法解引用,无法进行指针运算,但它可以根据我们的需求,转化为任意数据类型.
二.整数的存储方式
1.原码,反码,补码
我们知道减法实际可以看作加上一个负数,乘法可以看作不断相加,除法可以看作不断相减,因此,只要我们正确理解并处理好计算机中数据的加法,一切问题便可迎刃而解!
(1)补码出现的原因:
数字在计算机中是以二进制的方式进行存储,而在我们现实生活中,是有正数和负数的区别的,如何根据二进制来区分它是正数还是负数呢?
人们想到了一个简单的方法来区分正数或者负数,就是看最高位!
最高位为0,则为正数;最高位为1,则为负数
但是这样却会带来一个问题,一个正数与负数相加,并不符合我们的运算法则!
假设我们用int类型(32个bit位)来存储1,-1,假设电脑中只存在原码
1
00000000 00000000 00000000 00000001
-1
10000000 00000000 00000000 00000001
由于CPU中只存在加法器,如果按照原码直接进行相加,得到的二进制,转为数字,得到的是-2,显然1-1 -2,得到的答案是错误的.
不仅仅如此,那0又该如何表示呢?我们在数字中可没有+0,-0的区分,这样就是单纯的浪费
于是聪明的科学家想了一种方法,也就是原码.反码.补码的方法
在解释什么是补码之前,我们先思考一个问题,为什么会出现原码相加,答案出错呢?
原因其实就在于我们的符号位代表的是什么?它是一个事物,是我们人为给它赋上相应的含义
而其余位则仅仅是数字
数学运算针对的仅仅是数字,而不是我们的事物!所以你说一个负数加上一个正数一定会是负数吗?肯定不是,但是负数最高位是1,正数最高位是0,两者相加得到的1,就意味着结果必定是负数,这显然是错误的!
所以出现答案出错的原因,本质就在于这是一种混合编码,我们将事物和数字混合在一起进行编码了,而这种编码肯定是不符合我们的运算法则的
那科学家是如何解决这个问题呢?
既然只有数字才能进行数学运算,那我们把最高位看作是数值不就行了?
这其实就是补码进行的操作,补码的最高位实际是带符号的数值!它的权重是最高的

对于1000这个二进制数来说,假如是无符号正整数,它就是8,但它同时也是-8的补码
Pro1.采用补码的形式,数字表示的范围是多少?
不难看出,当最高位取1时,表示的就是最大的负数![]() ,而当最高位取0时,表示的就是最大的正数
,而当最高位取0时,表示的就是最大的正数![]() (等比求和)
(等比求和)
所以采用补码的形式,一个二进制数能表示的范围为![]()
所以为什么有符号char类型,范围在-128到127之间?也很好解释了
Pro2.采用补码的形式后,为什么负数总会比正数多表示一个数呢?
一个二进制数能表示的总数必然是![]()
但是不要忘记还要给我们的0留一个未知,所以正数始终比负数少一个,我们用一半的位置去表示负数
Pro3.具体如何从一个补码写出十进制整数呢?小数呢?
记住一个原则,补码的最高位实际是带符号的数值

小数也是同样的道理,小数也是有它对应的权重的

从这里也其实看出来补码的其中一个缺陷,并不好直接通过补码来对数字进行比较大小
Pro4.给出一个数字,如何迅速写出它的补码呢?
我们举一个小例子吧,比如5和-5这两个数字,采用补码的形式,则表示成这个样子

为什么-5的补码是这样表示?
![]()
我们从上述这个转换过程中能够有什么启发吗?
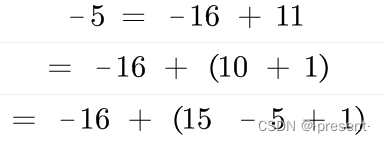
有人会说,为什么要写成这样的表现形式?
其实这一切都是为了凑出一个10来,通过10,将5和-5两个数字建立联系
我们可以发现,对一个正数二进制数字直接每一位取反,得到的其实就是该二进制数所能表示的最大数 - 该数字
比如说0101(5),每一位取反,得到的1010(10),两者相加必定全为1,即1111,对应该二进制数所能表示的最大数15,这很好理解
所以,任何一个负数的补码,它的变化规则如下:
符号位不变,其余位置按位取反(得到"互补正数"),再补上一个1
进一步思考,假如是一个负的小数呢?在哪里添上1?
假如理解上面的过程,就明白其实添1这个操作,本质是由于0霸占了正数的一个位置所导致的,我们要加上1,消去这个影响,使正数表示的范围(其余位)能够和负数(最高符号位)表示的范围相同
所以补1,始终是在末尾补1,加的不是"数值1"
更为详细的总结如下:

比如-1,这里拿一个字节存储举例
它的1原码是1000 0001,符号位不变,所有位按位取反,则它的反码是1111 1110
反码+1得到补码,也就是1111 1111,所以-1在计算机中就是1111 1111来存储的.
当然补码得到原码的另一种方式,除了逆着进行外,还可以重新按照原码得到补码的方式再重新操作一遍,非常神奇!!!
通过这种方法,我们不仅实现了符号位和数值域进行统一处理,无论负数还是正数,都有唯一一个二进制与之对应转化,同时,我们通过补码,统一了加法和减法运算.

Pro5.假如我现在想把Pro4中的5从5位变成8位呢?又应该如何表示?
+5的表示直接往前填0,凑齐8位即可,![]()
那-5呢?
由于变成了8位,则此时符号位所对应的权重,已经不是当初的那个它,变得更负了,当初只是![]() ,现在则变成
,现在则变成![]() ,因此,假如我们想要它继续保持-5,不难看出,正数部分也要相应增大,消去对应权值才行,所以补1才是正确操作
,因此,假如我们想要它继续保持-5,不难看出,正数部分也要相应增大,消去对应权值才行,所以补1才是正确操作
![]()
由上述的补码运算规则,也很容易验证我们的结果是对的
正负数相加,就是对应补码进行相加即可,至于最后是负数还是正数,就看对应符号位与最高位数字位进位相加(舍弃进位)的结果.

2.大小端存储

在了解正数以补码的形式存储后,我们就可以打开vs2019进行内存监视了,16的十六进制为10,在内存监视中,我们可以很好的观察到,不过为什么有点像是倒着存的?
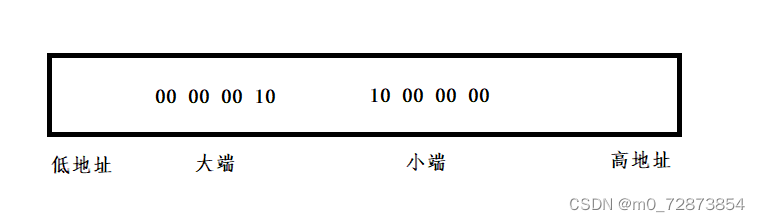 数据的存储有如图两种存储方式, 统称为字节序存储(以字节为一个单位),像char类型一个字节大小,则完全没有大端小端这样的概念.
数据的存储有如图两种存储方式, 统称为字节序存储(以字节为一个单位),像char类型一个字节大小,则完全没有大端小端这样的概念.
一种称为大端(字节序, 指数据的低位存储在高地址,数据的高位存储在内存的低地址
一种称为小端 (字节序),指数据的低位存储在低地址,数据的高位存储在内存的高地址
因此由上图在内存中的显示,我们可以知道,在目前X86环境底下是以小端字节序存储.而在我们知道的KEIL C51是大端字节序存储,有些ARM处理器,其可以通过硬件,根据自己的设置,调整是大端还是小端.
至于如何判断是大端还是小端,我们可以简单设计一个代码,1在大小端存储是不同的,我们取出1的地址(低地址),将其转为char *类型,再解引用(访问一个字节),得到1即为小端,得到0即为大端.
int check_sys(int x)
{
return (*(char*)&x);
}
#include <stdio.h>
int main()
{
int a = 1;
if (check_sys(a))
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}三.浮点数的存储
1.浮点数的二进制转化
根据国际标准IEEE,任意一个二进制浮点数都可以表示为这样的形式(类似十进制的科学计数法)
(-1)^S * M * 2^E
其中S用来确定正负,正数为0,负数为1,M是具体的一个数,范围在1~2间,E代表指数位
比如5.5,用二进制表示101.1,然后类似科学计数法,101.1可以表示成1.011*(2^2),然后是正数,所以5.5即可表示为(-1)^0 * 1.011 * 2 ^ 2,S为0(正数),M为1.011,E为2
但是我们也可以发现一些像是无限不循环小数,比如pi,只能无限逼近,而不能精确表示出来,所以我们也说C语言中,不能直接进行浮点数比较,原因就在此,本身存储就不是精确的.
2.存储方式

无论是单精度(float)或者是双精度 (double),其在内存中都是按照这样的格式进行存储,唯一不同的是float是32个比特位,而double是64个比特位
| bit位数目 | S | E | M |
| float | 1 | 8 | 23 |
| double | 1 | 11 | 52 |
对于M,由于M的取值范围必定在1~2之间,所以可以省略前面的1,例如1.011就可以省略1,只存入011进去,这样就可以多保存一位,达到24位
对于E,E是一个unsigned int类型的数字,但我们指数是可能出现负数的,所以为了让负数变为正数(无符号整型),像float类型,我们便加一个127(8个bit位能表示的最大负数)再存进去,对于double类型,则加一个1023再存进去.
Lg.例如0.5 二进制标准形式为(-1)^0 * 1.0 * 2 ^ (-1) (1) -1+127 = 126 (2)1.0的1可以去掉
其在内存中存储即为0 01111110 00000000000000000000000
当E全为0,它原本的指数即为-127(1000 0001 + 0111 1111),代表一个非常接近0的数字;
当E全为1,它原本的指数即为128(1000 0000 + 0111 1111), 并且有效数字也全为0,则代表无穷大,由S区分,正无穷还是负无穷.














 7237
7237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









