







Efficient Estimation of Word Representations in Vector Space
论文:Efficient Estimation of Word Representations in Vector Space
作者:Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean
时间:2013
地址:https://arxiv.org/pdf/1301.3781.pdf%C3%AC%E2%80%94%20%C3%AC%E2%80%9E%C5%93
Word2Vec 是一种词向量模型,它使用浅层神经网络将单词嵌入到低维向量空间中。结果是一组词向量,其中在向量空间中靠近的向量根据上下文具有相似的含义,而彼此相距较远的词向量具有不同的含义。
一、完整代码
使用python代码进行实现来增强理解
实现过程如下所示,但是我没有对算法进行任何优化,所以运行速度很慢,如果只是要用这个功能最好是利用官方库gensim,实现过程可以看下面代码;
word2vec 有两种出名的模型,两种加速方式,如果理解可以在此自由配置,
sg : {0, 1}, optional
Training algorithm: 1 for skip-gram; otherwise CBOW.
hs : {0, 1}, optional
If 1, hierarchical softmax will be used for model training.
If 0, hierarchical softmax will not be used for model training.
negative : int, optional
If > 0, negative sampling will be used, the int for negative specifies how many “noise words” should be drawn (usually between 5-20).
If 0, negative sampling will not be used.
模型相关代码:
text_corpus = [['实验室', 'abc', '计算机', '应用', '的', '人', '机界', '面'],
['用户', '对', '计算机', '系统', '响应', '时间', '的', '看法', '调查']]
word2vec = gensim.models.Word2Vec(
sentences=text_corpus,
min_count=1,
window=3,
vector_size=100,
)
# 输出word向量
word2vec.wv['中']
# array([ 0.00480066, -0.00362838, -0.00426481, 0.00121976, -0.0041273, ... dtype=float32)
# 计算两个词之间的相似性
word2vec.wv.similarity('图表','图子')
# 0.13703643
# 类似于king-man+woman=queen
word2vec.wv.most_similar(positive=['图子', '图表'], negative=['中'])
# [('系统工程', 0.1806158870458603),('感知', 0.17817144095897675),('界面', 0.13787229359149933),...]
# 找不和其他匹配的项
word2vec.wv.doesnt_match(['图子', '图表', '中'])
# '中'
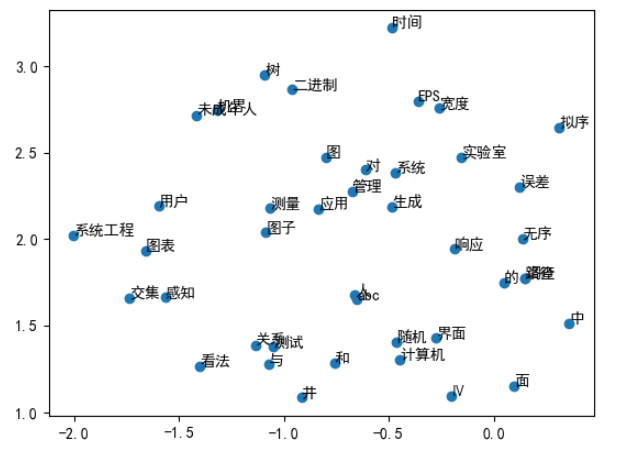
词向量可视化 这里使用的是TSNE算法进行的降维
from sklearn.manifold import TSNE
import numpy as np
import matplotlib.pyplot as plt
# 中文设置
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
def reduce_dimensions(model):
num_dimensions = 2
# 提取vectors和labels
vectors = np.asarray(model.wv.vectors)
labels = np.asarray(model.wv.index_to_key)
# 降维
tsne = TSNE(n_components=num_dimensions, random_state=0)
vectors = tsne.fit_transform(vectors)
x_vals = [v[0] for v in vectors]
y_vals = [v[1] for v in vectors]
return x_vals, y_vals, labels
x,y,label = reduce_dimensions(word2vec)
plt.scatter(x,y)
for x_,y_,label_ in zip(x,y,label):
plt.text(x_, y_, label_)
plt.show()
可视化结果如下:
二、论文解读
这篇论文主要介绍了两个框架,另外在这里再介绍两种加速手段
2.1 两个框架
两个框架:CBOW和Skip-gram,其中CBOW全称为 Continuous Bag-of-Words Model,Skip-gram全称为Continuous Skip-gram Model;
这两个框架试图最小化计算复杂度的同时解决数据量由于在这两个框架之前,主要用的是类NNLM模型,在使用加速策略优化了softmax层后,其中大部分的复杂性是由模型中的隐藏层引起的。为了简化模型加快训练速度,同时为了更好的拓展,这两种框架都把隐藏层给删掉;
2.1.1 CBOW
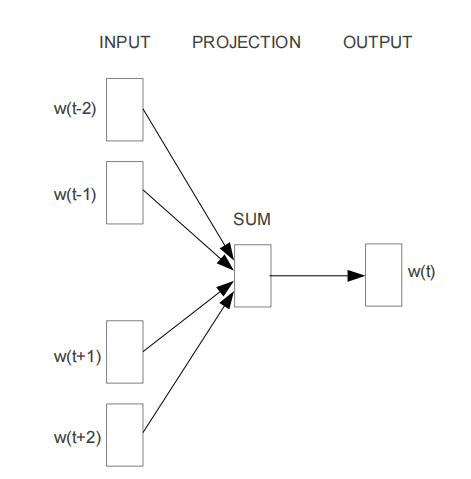
O u t p u t 1 ⋅ v = S u m ( I n p u t n ⋅ v ⋅ H v ⋅ d , a x i s = 0 ) 1 ⋅ d ⋅ W d ⋅ v Output_{1·v} = Sum( Input_{n·v}·H_{v·d}, axis=0)_{1·d}·W_{d·v} Output1⋅v=Sum(Inputn⋅v⋅Hv⋅d,axis=0)1⋅d⋅Wd⋅v
2.1.2 Skip-gram
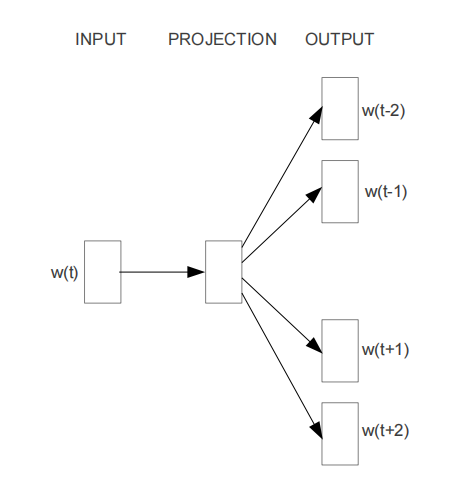
O u t p u t 2 R ⋅ v = [ I n p u t 1 ⋅ v ⋅ H v ⋅ d ⋅ W i d ⋅ v ] i = 1 , 2 , … 2 R Output_{2R·v} = [Input_{1·v}·H_{v·d}·Wi_{d·v}] \quad i = 1,2,\dots 2R Output2R⋅v=[Input1⋅v⋅Hv⋅d⋅Wid⋅v]i=1,2,…2R
2.2 两种加速
两种加速:Hierarchical Softmax和Negative Sampling
这两种加速是为了在softmax层减轻计算量,采取方法取替代
W
d
⋅
v
W_{d·v}
Wd⋅v,进而加快计算;Hierarchical Softmax 采取的方式是使用huffman树对output进行压缩,其名字中虽然有softmax,实际上只是采用了softmax的思想进行多层次的logistic回归;而 Negative Sampling 采取的方法是通过构造负样本集,进行极大似然估计。计算复杂度都减小为
l
o
g
2
V
log_2V
log2V。
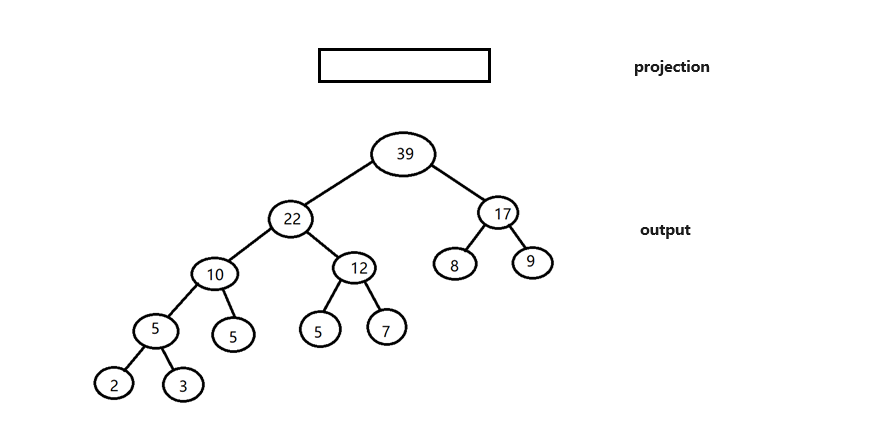
2.2.1 Hierarchical Softmax
Hierarchical Softmax 是利用哈夫曼树实现的,首先构造一棵huffman树,在每一层都进行一次logistic回归,进而对回归结果进行判定;
2.2.2 Negative Sampling
Negative Sampling 主要是通过构造负样本,然后利用负样本去最大化损失函数;例如Hierarchical Softmax 中 huffman树的某个叶子节点是正样本,则其他节点必然是负样本;其核心思想是利用已知的参数和已知参数与未知参数之间的关系去推断未知的参数,即极大似然估计,统计学上一个经典的参数估计方法;统计学的同学一定不会陌生;在这里我们通过负采样技术构造了负样本,已知参数是正样本和负样本;同时在这里我们使用logistic去定义了正样本和负样本的关系;未知参数就是正样本与负样本关系之间的参数,利用极大似然估计计算,至此Negative Sampling 的思想介绍完成!
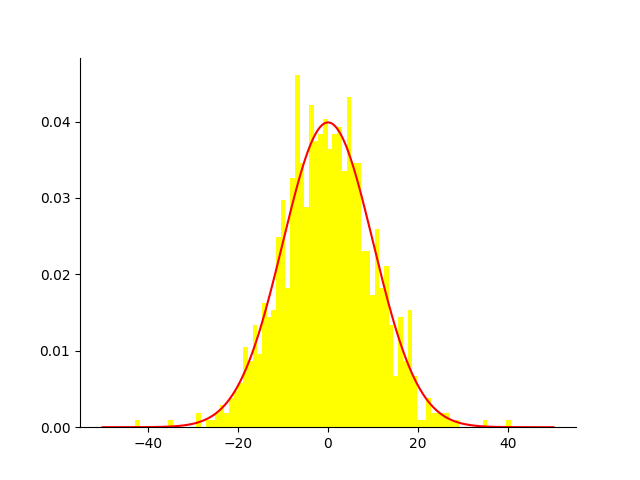
如上图所示,利用样本和关系去推断关系的参数;
三、过程实现
3.1 Huffman 树 构建
编写代码如下:
class Node:
def __init__(self, number, val, name=None, left=None, right=None):
self.number = number
self.val = val
self.name = name
self.left = left
self.right = right
class Huffman:
def __init__(self, data):
self.root = None
self.leafs = sorted([Node(ix, item[1], item[0]) for ix, item in enumerate(data)], key=lambda x: x.val, reverse=True)
self.len = len(data)
self.build()
self.res = ''
self.codes = []
def build(self):
while len(self.leafs) != 1:
node_right = self.leafs.pop()
node_left = self.leafs.pop()
new_node = Node(val= node_left.val + node_right.val, number=self.len, left=node_left, right=node_right)
self.leafs.append(new_node)
self.len += 1
for i in range(len(self.leafs)-1, 0, -1):
if self.leafs[i-1].val > self.leafs[i].val:
break
else:
self.leafs[i-1], self.leafs[i] = self.leafs[i], self.leafs[i-1]
self.root = self.leafs[0]
def bfs(self, node, target, s):
if not node:
return None
if node.name == target:
self.res = s
self.bfs(node.left, target, s+'1')
self.bfs(node.right, target, s+'0')
def bfs_codes(self, node, s):
if not node:
return None
if node.name is not None:
self.codes.append((s, node.name))
self.bfs_codes(node.left, s+'1')
self.bfs_codes(node.right, s+'0')
def get_code(self, name):
self.res = ''
self.bfs(self.root, name, '')
if self.res:
return self.res
else:
raise Exception(f"can't find \"{name}\"")
def get_all_code(self):
self.codes = []
self.bfs_codes(self.root, '')
return self.codes
Huffman类的使用:
# from collections import Counter
# s = '东胜神洲傲来国海边有一花果山,山顶一石,受日月精华,产下一个石猴,石猴勇探瀑布飞泉,发现水帘洞,被众猴奉为美猴王,猴王领群猴在山中自由自在数百载,偶闻仙、佛、神圣三者可躲过轮回,与天地山川齐寿,遂独自乘筏泛海,历南赡部洲,至西牛贺洲,终在灵台方寸山斜月三星洞,为菩提祖师收留,赐其法名孙悟空,悟空在三星洞悟彻菩提妙理,学到七十二般变化和筋斗云之术后返回花果山,一举灭妖魔混世魔王,花果山狼、虫、虎、豹等七十二洞妖王都来奉其为尊,'
# data = list(Counter(s).items())
data = [('东', 1), ('胜', 1), ('神', 2), ('洲', 3), ('傲', 1), ('来', 2), ('国', 1), ('海', 2), ('边', 1), ('有', 1), ('一', 4), ('花', 3), ('果', 3), ('山', 7), (',', 20), ('顶', 1), ('石', 3), ('受', 1), ('日', 1), ('月', 2), ('精', 1), ('华', 1), ('产', 1), ('下', 1), ('个', 1), ('猴', 6), ('勇', 1), ('探', 1), ('瀑', 1), ('布', 1), ('飞', 1), ('泉', 1), ('发', 1), ('现', 1), ('水', 1), ('帘', 1), ('洞', 4), ('被', 1), ('众', 1), ('奉', 2), ('为', 3), ('美', 1), ('王', 4), ('领', 1), ('群', 1), ('在', 4), ('中', 1), ('自', 3), ('由', 1), ('数', 1), ('百', 1), ('载', 1), ('偶', 1), ('闻', 1), ('仙', 1), ('、', 5), ('佛', 1), ('圣', 1), ('三', 3), ('者', 1), ('可', 1), ('躲', 1), ('过', 1), ('轮', 1), ('回', 2), ('与', 1), ('天', 1), ('地', 1), ('川', 1), ('齐', 1), ('寿', 1), ('遂', 1), ('独', 1), ('乘', 1), ('筏', 1), ('泛', 1), ('历', 1), ('南', 1), ('赡', 1), ('部', 1), ('至', 1), ('西', 1), ('牛', 1), ('贺', 1), ('终', 1), ('灵', 1), ('台', 1), ('方', 1), ('寸', 1), ('斜', 1), ('星', 2), ('菩', 2), ('提', 2), ('祖', 1), ('师', 1), ('收', 1), ('留', 1), ('赐', 1), ('其', 2), ('法', 1), ('名', 1), ('孙', 1), ('悟', 3), ('空', 2), ('彻', 1), ('妙', 1), ('理', 1), ('学', 1), ('到', 1), ('七', 2), ('十', 2), ('二', 2), ('般', 1), ('变', 1), ('化', 1), ('和', 1), ('筋', 1), ('斗', 1), ('云', 1), ('之', 1), ('术', 1), ('后', 1), ('返', 1), ('举', 1), ('灭', 1), ('妖', 2), ('魔', 2), ('混', 1), ('世', 1), ('狼', 1), ('虫', 1), ('虎', 1), ('豹', 1), ('等', 1), ('都', 1), ('尊', 1)]
huffman = Huffman(data)
huffman.get_code('石')
## 输出 '011000'
huffman树展示(部分):
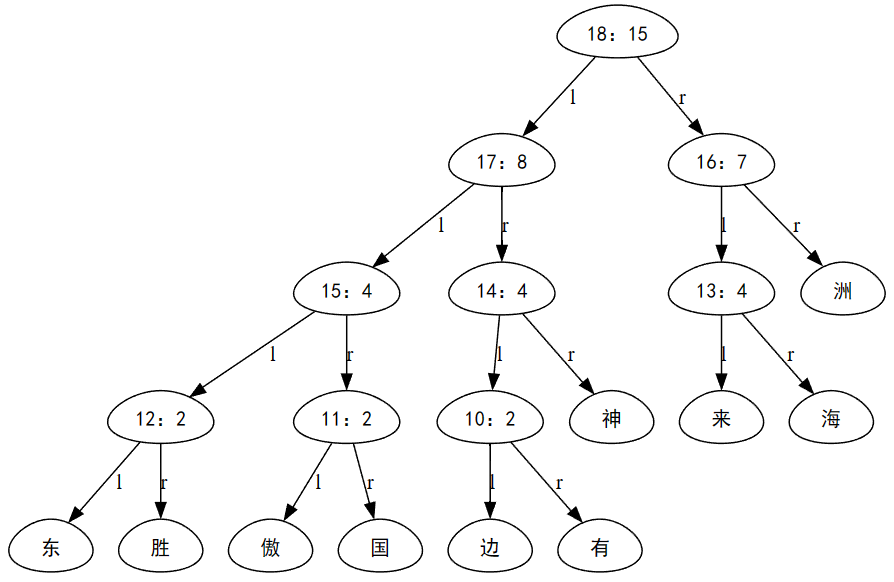
画图来自 数据结构可视化 Graphviz在Python中的使用 [树的可视化]
3.1.1 CBOW
先准备数据,还是以西游记为例子
from collections import Counter
s = '东胜神洲傲来国海边有一花果山,山顶一石,受日月精华,产下一个石猴,石猴勇探瀑布飞泉,发现水帘洞,被众猴奉为美猴王,猴王领群猴在山中自由自在数百载,偶闻仙、佛、神圣三者可躲过轮回,与天地山川齐寿,遂独自乘筏泛海,历南赡部洲,至西牛贺洲,终在灵台方寸山斜月三星洞,为菩提祖师收留,赐其法名孙悟空,悟空在三星洞悟彻菩提妙理,学到七十二般变化和筋斗云之术后返回花果山,一举灭妖魔混世魔王,花果山狼、虫、虎、豹等七十二洞妖王都来奉其为尊,'
vocabulary = list(set(list(s)))
# ['虎', '返', '收', '法', '可', '闻', '果', '个', '牛', '尊', '现', '发', '理', '月', '世', '菩', '空', '洞', '之', '下', '日', '猴', '被', '等', '顶', '王', '斗', '寸', '魔', '西', '虫', '泉', '佛', '华', '众', '师', '山', '云', '举', '在', '一', '圣', '齐', '赡', '帘', '探', '祖', '狼', '川', '筏', '群', '泛', '都', '至', '和', '历', '其', '勇', '赐', '国', '妖', '部', '方', '后', '留', '自', '仙', '三', '悟', '到', '过', '者', '花', '天', '东', '般', '受', '灭', '载', '、', '精', '与', '傲', '寿', '终', '七', '边', '有', '地', '台', '胜', '混', '贺', '提', '瀑', '美', '独', '躲', '学', ',', '为', '遂', '洲', '变', '布', '妙', '名', '乘', '神', '回', '化', '孙', '星', '百', '海', '术', '豹', '筋', '由', '灵', '斜', '二', '数', '产', '领', '飞', '十', '石', '彻', '奉', '轮', '水', '中', '南', '来', '偶']
data = list(Counter(s).items())
hufffman = Huffman(data)
codes = [code for code, name in hufffman.get_all_code()]
route = set()
for item in codes:
for i in range(1, len(item)):
route.add(item[:i])
n = 4
x_list = []
y_list = []
for i in range(len(s)-n):
x_list.append(list(s[i:i+n//2] + s[i+n//2+1:i+n+1]))
y_list.append(hufffman.get_code(s[i+n//2]))
再建立模型如下:
table = tf.keras.layers.StringLookup(vocabulary=vocabulary, output_mode='one_hot')
init = tf.initializers.glorot_normal(seed=42)
projection = tf.Variable(
initial_value=init(shape=(137, 200), dtype="float32"),
trainable=True
)
hashmap = {item:[tf.Variable(initial_value=init(shape=(200, 1), dtype="float32"),trainable=True), tf.Variable(initial_value=init(shape=(1, 1), dtype="float32"),trainable=True)] for item in route}
# 定义损失
def calculate_loss(x,y):
x = table(x)
x = tf.reduce_sum(x, axis=0, keepdims=True)
x = tf.matmul(x, projection)
loss = 0
w_list = []
b_list = []
for i in range(1, len(y)):
route = y[:i]
w, b = hashmap[route]
w_list.append(w)
b_list.append(b)
d = int(route[-1])
x_ = tf.matmul(x, w) + b
loss_ = tf.reshape(tf.math.log(tf.sigmoid(x_)) * (1-d) + tf.math.log(1 - tf.sigmoid(x_)) * d, shape=())
loss -= loss_
return loss, w_list + b_list
训练:
epoch = 100
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
loss_list = []
for i in tqdm(range(epoch)):
loss_batch_list = []
for x, y in zip(x_list,y_list):
with tf.GradientTape() as tape:
loss, para = calculate_loss(x, y)
dpara = tape.gradient(loss, para)
optimizer.apply_gradients(grads_and_vars=zip(dpara, para))
loss_batch_list.append(loss.numpy())
del tape
loss_list.append(np.mean(loss_batch_list))
画图如下:
import matplotlib.pyplot as plt
plt.plot(loss_list)
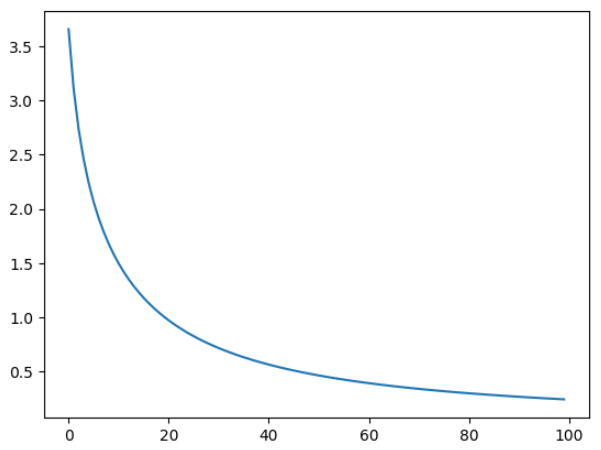
3.1.2 Skip-gram
和CBOW差不多,把输出一起处理求loss就好,准备数据如下:
from collections import Counter
s = '东胜神洲傲来国海边有一花果山,山顶一石,受日月精华,产下一个石猴,石猴勇探瀑布飞泉,发现水帘洞,被众猴奉为美猴王,猴王领群猴在山中自由自在数百载,偶闻仙、佛、神圣三者可躲过轮回,与天地山川齐寿,遂独自乘筏泛海,历南赡部洲,至西牛贺洲,终在灵台方寸山斜月三星洞,为菩提祖师收留,赐其法名孙悟空,悟空在三星洞悟彻菩提妙理,学到七十二般变化和筋斗云之术后返回花果山,一举灭妖魔混世魔王,花果山狼、虫、虎、豹等七十二洞妖王都来奉其为尊,'
vocabulary = list(set(list(s)))
# ['虎', '返', '收', '法', '可', '闻', '果', '个', '牛', '尊', '现', '发', '理', '月', '世', '菩', '空', '洞', '之', '下', '日', '猴', '被', '等', '顶', '王', '斗', '寸', '魔', '西', '虫', '泉', '佛', '华', '众', '师', '山', '云', '举', '在', '一', '圣', '齐', '赡', '帘', '探', '祖', '狼', '川', '筏', '群', '泛', '都', '至', '和', '历', '其', '勇', '赐', '国', '妖', '部', '方', '后', '留', '自', '仙', '三', '悟', '到', '过', '者', '花', '天', '东', '般', '受', '灭', '载', '、', '精', '与', '傲', '寿', '终', '七', '边', '有', '地', '台', '胜', '混', '贺', '提', '瀑', '美', '独', '躲', '学', ',', '为', '遂', '洲', '变', '布', '妙', '名', '乘', '神', '回', '化', '孙', '星', '百', '海', '术', '豹', '筋', '由', '灵', '斜', '二', '数', '产', '领', '飞', '十', '石', '彻', '奉', '轮', '水', '中', '南', '来', '偶']
data = list(Counter(s).items())
hufffman = Huffman(data)
codes = [code for code, name in hufffman.get_all_code()]
route = set()
for item in codes:
for i in range(1, len(item)):
route.add(item[:i])
n = 4
x_list = []
y_list = []
for i in range(len(s)-n):
y_list.append(list(hufffman.get_code(item) for item in s[i:i+n//2] + s[i+n//2+1:i+n+1]))
x_list.append(s[i+n//2])
建立模型如下:
table = tf.keras.layers.StringLookup(vocabulary=vocabulary, output_mode='one_hot')
init = tf.initializers.glorot_normal(seed=42)
projection = tf.Variable(
initial_value=init(shape=(137, 200), dtype="float32"),
trainable=True
)
hashmap = {item:[tf.Variable(initial_value=init(shape=(200, 1), dtype="float32"),trainable=True), tf.Variable(initial_value=init(shape=(1, 1), dtype="float32"),trainable=True)] for item in route}
定义损失如下:
def calculate_loss(x, y):
x = tf.expand_dims(table(x), axis=0)
x = tf.matmul(x, projection)
loss = 0
para = []
for item in y:
for i in range(1, len(item)):
route = item[:i]
w, b = hashmap[route]
para.append(w)
para.append(b)
d = int(route[-1])
x_ = tf.matmul(x, w) + b
loss_ = tf.reshape(tf.math.log(tf.sigmoid(x_)) * (1-d) + tf.math.log(1 - tf.sigmoid(x_)) * d, shape=())
loss -= loss_
return loss, para
训练:
epoch = 100
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
loss_list = []
for i in tqdm(range(epoch)):
loss_batch_list = []
for x, y in zip(x_list,y_list):
with tf.GradientTape() as tape:
loss, para = calculate_loss(x, y)
dpara = tape.gradient(loss, para)
optimizer.apply_gradients(grads_and_vars=zip(dpara, para))
loss_batch_list.append(loss.numpy())
del tape
loss_list.append(np.mean(loss_batch_list))
画图如下:
import matplotlib.pyplot as plt
plt.plot(loss_list)
3.2 Negative Sampling 映射关系 构建
建表代码如下:
# from collections import Counter
# s = '东胜神洲傲来国海边有一花果山,山顶一石,受日月精华,产下一个石猴,石猴勇探瀑布飞泉,发现水帘洞,被众猴奉为美猴王,猴王领群猴在山中自由自在数百载,偶闻仙、佛、神圣三者可躲过轮回,与天地山川齐寿,遂独自乘筏泛海,历南赡部洲,至西牛贺洲,终在灵台方寸山斜月三星洞,为菩提祖师收留,赐其法名孙悟空,悟空在三星洞悟彻菩提妙理,学到七十二般变化和筋斗云之术后返回花果山,一举灭妖魔混世魔王,花果山狼、虫、虎、豹等七十二洞妖王都来奉其为尊,'
# vocabulary = list(set(list(s)))
# n = len(s)
# data = list(Counter(s).items())
# data = [(name, val/n) for name, val in data]
# names = [name for name, val in data]
# vals = np.cumsum([val for name, val in data])
names = ['东', '胜', '神', '洲', '傲', '来', '国', '海', '边', '有', '一', '花', '果', '山', ',', '顶', '石', '受', '日', '月', '精', '华', '产', '下', '个', '猴', '勇', '探', '瀑', '布', '飞', '泉', '发', '现', '水', '帘', '洞', '被', '众', '奉', '为', '美', '王', '领', '群', '在', '中', '自', '由', '数', '百', '载', '偶', '闻', '仙', '、', '佛', '圣', '三', '者', '可', '躲', '过', '轮', '回', '与', '天', '地', '川', '齐', '寿', '遂', '独', '乘', '筏', '泛', '历', '南', '赡', '部', '至', '西', '牛', '贺', '终', '灵', '台', '方', '寸', '斜', '星', '菩', '提', '祖', '师', '收', '留', '赐', '其', '法', '名', '孙', '悟', '空', '彻', '妙', '理', '学', '到', '七', '十', '二', '般', '变', '化', '和', '筋', '斗', '云', '之', '术', '后', '返', '举', '灭', '妖', '魔', '混', '世', '狼', '虫', '虎', '豹', '等', '都', '尊']
vals = [0.004672897196261682, 0.009345794392523364, 0.018691588785046728, 0.03271028037383177, 0.037383177570093455, 0.04672897196261682, 0.0514018691588785, 0.06074766355140187, 0.06542056074766354, 0.07009345794392523, 0.08878504672897196, 0.102803738317757, 0.11682242990654206, 0.14953271028037382, 0.24299065420560745, 0.24766355140186913, 0.2616822429906542, 0.26635514018691586, 0.27102803738317754, 0.2803738317757009, 0.2850467289719626, 0.2897196261682243, 0.29439252336448596, 0.29906542056074764, 0.3037383177570093, 0.3317757009345794, 0.3364485981308411, 0.3411214953271028, 0.34579439252336447, 0.35046728971962615, 0.35514018691588783, 0.3598130841121495, 0.3644859813084112, 0.3691588785046729, 0.37383177570093457, 0.37850467289719625, 0.397196261682243, 0.40186915887850466, 0.40654205607476634, 0.4158878504672897, 0.42990654205607476, 0.43457943925233644, 0.4532710280373832, 0.45794392523364486, 0.46261682242990654, 0.48130841121495327, 0.48598130841121495, 0.5, 0.5046728971962616, 0.5093457943925233, 0.5140186915887849, 0.5186915887850465, 0.5233644859813081, 0.5280373831775698, 0.5327102803738314, 0.5560747663551397, 0.5607476635514014, 0.565420560747663, 0.579439252336448, 0.5841121495327096, 0.5887850467289713, 0.5934579439252329, 0.5981308411214945, 0.6028037383177561, 0.6121495327102795, 0.6168224299065411, 0.6214953271028028, 0.6261682242990644, 0.630841121495326, 0.6355140186915876, 0.6401869158878493, 0.6448598130841109, 0.6495327102803725, 0.6542056074766341, 0.6588785046728958, 0.6635514018691574, 0.668224299065419, 0.6728971962616807, 0.6775700934579423, 0.6822429906542039, 0.6869158878504655, 0.6915887850467272, 0.6962616822429888, 0.7009345794392504, 0.705607476635512, 0.7102803738317737, 0.7149532710280353, 0.7196261682242969, 0.7242990654205586, 0.7289719626168202, 0.7383177570093435, 0.7476635514018669, 0.7570093457943903, 0.7616822429906519, 0.7663551401869135, 0.7710280373831752, 0.7757009345794368, 0.7803738317756984, 0.7897196261682218, 0.7943925233644834, 0.799065420560745, 0.8037383177570067, 0.8177570093457917, 0.827102803738315, 0.8317757009345766, 0.8364485981308383, 0.8411214953270999, 0.8457943925233615, 0.8504672897196232, 0.8598130841121465, 0.8691588785046699, 0.8785046728971933, 0.8831775700934549, 0.8878504672897165, 0.8925233644859781, 0.8971962616822398, 0.9018691588785014, 0.906542056074763, 0.9112149532710246, 0.9158878504672863, 0.9205607476635479, 0.9252336448598095, 0.9299065420560712, 0.9345794392523328, 0.9392523364485944, 0.9485981308411178, 0.9579439252336411, 0.9626168224299028, 0.9672897196261644, 0.971962616822426, 0.9766355140186876, 0.9813084112149493, 0.9859813084112109, 0.9906542056074725, 0.9953271028037342, 0.9999999999999958]
def table(names, vals):
r = np.random.rand()
for i in range(len(vals)):
if r > vals[i]:
pass
else:
return names[i]
return names[-1]
3.2.1 CBOW
准备数据和对输出进行负采样函数,代码如下:
def get_neg(target, k):
lst = []
while len(lst) != k:
name = table(names, vals)
if name != target:
lst.append(name)
return lst
n = 4
x_list = []
y_list = []
for i in range(len(s)-n):
x_list.append(list(s[i:i+n//2] + s[i+n//2+1:i+n+1]))
y_list.append(s[i+n//2])
# x_list [['东', '胜', '洲', '傲'], ['胜', '神', '傲', '来'], ['神', '洲', '来', '国']...]
# y_list ['神', '洲', '傲'...]
建立模型如下:
Vocabulary = tf.keras.layers.StringLookup(vocabulary=vocabulary, output_mode='one_hot')
init = tf.initializers.glorot_normal(seed=42)
projection = tf.Variable(
initial_value=init(shape=(137, 200), dtype="float32"),
trainable=True
)
hashmap = {item:[tf.Variable(initial_value=init(shape=(200, 1), dtype="float32"),trainable=True), tf.Variable(initial_value=init(shape=(1, 1), dtype="float32"),trainable=True)] for item in vocabulary}
损失计算如下:
def calculate_loss(x, y):
y = [y] + get_neg(y, 4)
para = []
def get_sigmoid(x, w, b):
x = Vocabulary(x)
x = tf.reduce_sum(x, axis=0, keepdims=True)
x = tf.matmul(x, projection)
return tf.reshape(tf.sigmoid(tf.matmul(x, w) + b), shape=())
loss = -tf.math.log(get_sigmoid(x, hashmap[y[0]][0], hashmap[y[0]][1]))
para.append(hashmap[y[0]][0])
para.append(hashmap[y[0]][1])
for item in y[1:]:
loss -= tf.math.log(1 - get_sigmoid(x, hashmap[item][0], hashmap[item][1]))
para.append(hashmap[item][0])
para.append(hashmap[item][1])
return loss, para
训练代码如下:
epoch = 100
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
loss_list = []
for i in tqdm(range(epoch)):
loss_batch_list = []
for x, y in zip(x_list,y_list):
with tf.GradientTape() as tape:
loss, para = calculate_loss(x, y)
dpara = tape.gradient(loss, para)
optimizer.apply_gradients(grads_and_vars=zip(dpara, para))
loss_batch_list.append(loss.numpy())
del tape
loss_list.append(np.mean(loss_batch_list))
结果作图:
import matplotlib.pyplot as plt
plt.plot(loss_list)
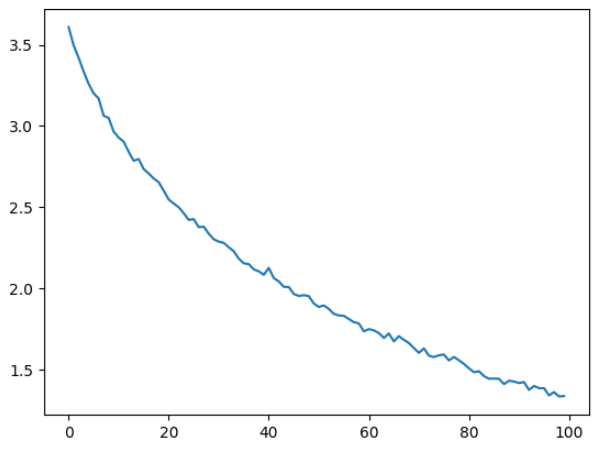
3.2.2 Skip-gram
除了数据准备和损失计算以外,其他与CBOW相同:
数据准备如下:
n = 4
x_list = []
y_list = []
for i in range(len(s)-n):
y_list.append(list(s[i:i+n//2] + s[i+n//2+1:i+n+1]))
x_list.append(s[i+n//2])
损失计算代码如下:
def calculate_loss(x, ys):
loss = 0
para = []
x = Vocabulary(x)
x = tf.expand_dims(x, axis=0)
x = tf.matmul(x, projection)
for y in ys:
y = [y] + get_neg(y, 4)
def get_sigmoid(x, w, b):
return tf.reshape(tf.sigmoid(tf.matmul(x, w) + b), shape=())
loss -= tf.math.log(get_sigmoid(x, hashmap[y[0]][0], hashmap[y[0]][1]))
para.append(hashmap[y[0]][0])
para.append(hashmap[y[0]][1])
for item in y[1:]:
loss -= tf.math.log(1 - get_sigmoid(x, hashmap[item][0], hashmap[item][1]))
para.append(hashmap[item][0])
para.append(hashmap[item][1])
return loss, para
得到训练损失图像如下:
四、整体总结
1. 为什么使用huffman树,其他树可以实现吗?
使用其他树是同样可以实现的,但是使用huffman树会保证出现频率高的词的高度小,这样会导致计算的次数小;利用huffman树的无损压缩这一功能,可以加快训练速度。














 9366
9366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









