






一、PCA
1.1 概述
主成分分析(PCA)是一种常用的数据降维方法,它通过线性变换将原始数据变换为一组各维度线性无关的表示,通常用于高维数据的处理和可视化。
1.2 特征维度约减
特征约减的目的是将高维特征向量映射到低维子空间中
给定n个样本(每个样本维度为p维)
通过特征变换/投影矩阵实现特征空间的压缩:
大多数机器学习算法在高维空间中表现不够鲁棒,查询速度与精度随着维度增加而降低.有价值的维度往往很少
1.3 协方差矩阵
在统计学中,方差是用来度量单个随机变量的离散程度,而协方差则一般用来刻画两个随机变量的相似程度
方差:
协方差:
例:如果观测N个人的体重w和身高h,这样会形成的样本空间,观测向量
表示第j个人体重和身高,观测矩阵可以表示为:
这些是观测序列
协方差矩阵是一个p*p的矩阵S,满足
由于任何具有
矩阵都是半正定的(如果B是m x n 的矩阵,那么是半正定的),所以S也是半正定的。
注:协方差矩阵也常记作Σ
例:从一个总体中随机抽取4个样本做3次测量,每个样本的观测向量为:
求样本均值及协方差矩阵。
样本均值:
去中心化(减去均值):
得到矩阵B
所以,样本的协方差矩阵S为:
1.4 PCA推导
将矩阵图片转换为高维的向量导致维度过高,如果我们能将维度降低,将提高精度和效率,因此引入PCA。
如何进行降维呢?假设我们有一个10304 * 400 的图片矩阵X,如何转换成120 * 40 的向量Y呢?
答案是通过矩阵乘法实现,我们引入一个矩阵P大小为120*10304即可实现
那么矩阵降维可视化可以理解为将二维坐标系中的点集投影到直线方向成为向量
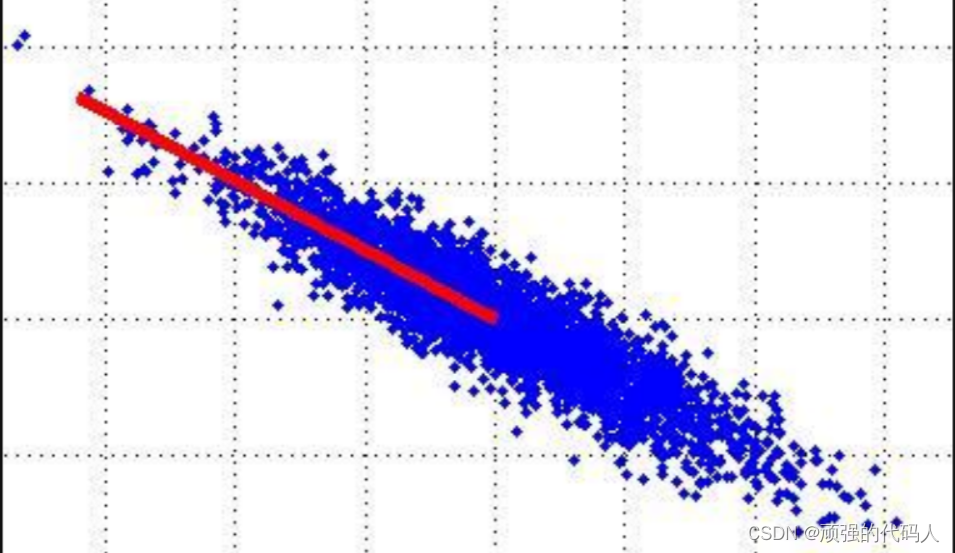
为了让损失的信息尽量少,我们希望矩阵的协方差值尽量大
(同维方差大,不同维尽量为0)
即
由于
则
转化为(W=P^T)
引入拉格朗日算子J(W):
令得,
,即
即,想要的最大方差,就是原始协方差矩阵最大的特征值,最佳投影方向就是最大特征值所对应特征向量
步骤为:
(1) 原始数据去中心化
(2) 计算原始数据的协方差矩阵
(3) 求出协方差矩阵特征值和特征向量
(4) 降为d维,则选择最大d个特征值对应特征向量组成矩阵
(5) 计算投影之后的数据
二、代码实现
2.1 数据集介绍
ORL人脸库:由英国剑桥大学AT&T实验室创建,包含40个不同个体,每个个体包含10张不同姿态的人脸图像,共400张面部图像,部分人脸图像包括了姿态,表情和面部饰物的变化,其深度旋转和平面旋转可达20度;ORL人脸数据库中每个采集对象的10幅样本图片都经过归一化处理的灰度图像,图像尺寸均为92×112,图像背景为黑色。

2.2 实现
pca_compress:这个函数用于执行PCA压缩,将高维数据降到低维。
计算数据的均值并从数据中移除均值。计算协方差矩阵。计算协方差矩阵的特征值和特征向量。根据特征值的大小排序特征向量,选择前k个。将原始数据转换到新的低维空间。
def pca_compress(data_mat, k=9999999):
mean_vals = np.mean(data_mat, axis=0)
mean_removed = data_mat - mean_vals
cov_mat = np.cov(mean_removed, rowvar=1)
eig_vals, eig_vects = np.linalg.eig(np.mat(cov_mat))
eig_val_idx = np.argsort(eig_vals)
eig_val_idx = eig_val_idx[:-(k + 1):-1]
re_eig_vects = eig_vects[:, eig_val_idx]
low_dim_data = re_eig_vects.T * mean_removed
return low_dim_data, mean_vals, re_eig_vects
test_img:用于测试一个新的图像,并将其投影到通过PCA获得的数据的子空间。通过减去均值,然后乘以低维数据转换矩阵的转置来将测试图像转换到低维空间。
def test_img(img, mean_vals, low_dim_data):
mean_removed = img - mean_vals
return mean_removed * low_dim_data.T
compute_distance:计算两个向量之间的欧氏距离
def compute_distance(vector1, vector2):
return np.linalg.norm(np.array(vector1)[0] - np.array(vector2)[0])
compute_distance_:计算两个向量之间的余弦距离
def compute_distance_(vector1, vector2):
return np.dot(np.array(vector1)[0], np.array(vector2)[0]) / (np.linalg.norm(np.array(vector1)[0]) * (np.linalg.norm(np.array(vector2)[0])))
main函数:
加载训练数据,每个人的1到9号图像,对数据进行PCA压缩。
测试,加载每个人的10号图像,并计算其与训练数据的低维表示之间的余弦距离。
if __name__ == '__main__':
# 1. use num 1- 9 image of each person to train
data = []
for i in range(1, 41):
for j in range(1, 10):
img = cv.imread('orl_faces/s' + str(i) + '/' + str(j) + '.pgm', 0)
width, height = img.shape
img = img.reshape((img.shape[0] * img.shape[1]))
data.append(img)
low_dim_data, mean_vals, re_eig_vects = pca_compress(data, 90)
# 2. use num 10 image of each person to test
correct = 0
for k in range(1, 41):
img = cv.imread('orl_faces/s' + str(k) + '/10.pgm', 0)
img = img.reshape((img.shape[0] * img.shape[1]))
distance = test_img(img, mean_vals, low_dim_data)
distance_mat = []
for i in range(1, 41):
for j in range(1, 10):
distance_mat.append(compute_distance_(re_eig_vects[(i - 1) * 9 + j - 1], distance.reshape((1, -1))))
num_ = np.argmax(distance_mat)
class_ = int(np.argmax(distance_mat) / 9) + 1
if class_ == k:
correct += 1
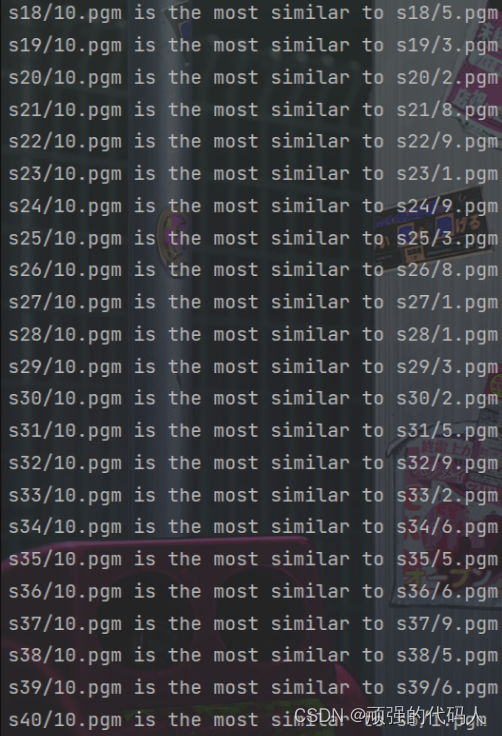
print('s' + str(k) + '/10.pgm is the most similar to s' +
str(class_) + '/' + str(num_ % 9 + 1) + '.pgm')
print("accuracy: %lf" % (correct / 40))
2.3 结果
三、总结
3.1 优点
降低维度:PCA可以减少数据的维度,减少数据量,简化模型或可视化。
去除噪声:PCA可以去除数据中的噪声和冗余信息,提高数据质量。
数据压缩:通过保留主要成分,可以实现对原始数据的压缩,减少存储和计算成本。
提高效率:去除冗余信息后,模型的训练和预测效率会得到提高。
3.2 缺点
可能会损失信息:由于PCA是通过保留主要成分来降低维度,所以可能会丢失一些次要的但有用的信息。
对异常值敏感:PCA受到异常值的影响较大,因为它的目标是最小化所有数据点的距离,所以异常值会对主成分的方向产生较大影响。
不保证最优:PCA虽然能够找到方差最大的方向,但并不一定能找到数据的最优低维表示。
难以解释:PCA的变换矩阵通常是难以解释的,尤其是在非线性数据中。















 1746
1746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









