






目录
一、介绍
逻辑回归是机器学习中的一种分类模型,逻辑回归是一种分类算法,虽然名字中带有回归。由于算法的简单和高效,在实际中应用非常广泛。
二、sigmoid函数
(1)公式:
z取值为负无穷到正无穷,g(z)的取值为[0, 1]。他将一个任意的值映射到[0, 1]区间上,我们从线性回归中得到一个预测值,并将该值映射到sigmoid函数中,因为是二分类,所以我们就可以把这个函数看成预测为正类的概率,我们给定一个阈值,如果大于该阈值就判断为正类,如果小于就预测为负类,以此达到分类的效果。
举个例子:当我们抽奖的时候,假设有60%的概率会中奖,当我们线性回归预测得到的预测值代入sigmoid函数的时候值大等于60%,就预测中奖,否则预测为不中奖。
(2)sigmoid函数的输入
预测函数:
其中
按照上面所说,我们用h(x)来表示预测为正类的概率那么预测为负类的概率就为1-h(x)
当二分类的时候就用1来表示正类用0来表示负类,那么我们就可以得到公式:
这样使得y取值为0和1都能表示为预测为y的概率。
以下是sigmoid函数代码:
其中np.exp()也就是e
def sigmoid(z):
return 1 / (1 + np.exp(-z))三、梯度上升
(1)似然函数
公式:
概念:
似然函数是一种衡量参数与观测数据之间关系的函数,通过最大化似然函数来估计参数的取值,从而使模型更好地拟合观测数据。
也就是说我们要使得这个似然函数的值尽可能大,才能使得这个函数拟合效果好。
这时候我们就需要求导求出这个函数的极值。但是由于这个函数求导计算量大,所以我们可以对这个函数取对数,得到对数似然函数。
对数平均似然函数公式:
我们对L(θ)除以m得到平均似然函数,当然可除可不除。
转化为对数似然将原来的累乘转化为累加使得通过导数求极值的计算量得到减少。
对数似然函数代码:
def srhs(X, y, theta):
m = len(y)
h = sigmoid(X.dot(theta))
res = (1/m) * (y.dot(np.log(h)) + (1-y).dot(np.log(1-h)))
return res代码解释:
m是y的样本数量,theta是以数组存储的θ,也就是上面说的θ1到θn,也就是sigmoid的输入,线性回归方程。h得到的也是一个列向量,是数据集x中每个样本点代入到sigmoid函数中的值。因为是累加的,所以我们最后结果就可以直接将其分为两部分用矩阵相乘计算。最后返回一个浮点型的值。
梯度上升
因为我们是求似然函数的最大值,所以我们用梯度上升来求解。当然还有一个算法是梯度下降,求损失函数的最小值,损失函数公式就是我们的平均似然函数乘以-1的结果。本质上来看其实算法原理都一样,只是表示的内容不一样。
学习率:
决定了模型在训练过程中更新权重参数的速度与方向
再梯度上升中就是表示每次对θ值梯度上升的步长,就有点像微积分中某点的导数来估计这个点在一个范围为t内的的导数, t取尽可能小来减少误差。这里的t也就是θ步长。
学习率的选取:
1.选取的太大大,那么在每一步迭代中,模型参数可能会跨过最优解,导致震荡或者发散,这被称为“振荡现象”或“不稳定性”。
2.如果学习率设置得太小,模型收敛到最优解的速度将会非常慢,而且可能会陷入局部极小点,而不是全局最优解。
普通梯度上升和随机梯度上升的区别也就在学习率的选取上,随机梯度上升的学习率不是固定的,更新时通常使用较小的学习率,并且这个学习率可以自适应地调整。
接下来是对似然函数求导以求极大值
在网上查阅资料得到以下求导公式:
其中的xij就表示对应的θj的那一列。
那我们就求得了
参数更新:
梯度上升代码:
def gradient_ascent(X, y, num, alpha):
m, n = X.shape
theta = np.zeros(n)
for i in range(num_):
h = sigmoid(np.dot(X, theta))
for j in range(n):
theta[j] += alpha*(np.sum((y - h) * X[:, j]) / m)
return theta代码解释:
按照上面的思路,我们先假设一个,我们用数组theta来存储θ。我们初始值都赋值为0,从0开始使用梯度上升函数对其进行修改。
第一个for循环表示的是总共的迭代次数,也就是进行梯度上升的次数。内层循环遍历就是对θ中的每个值进行修改。theta[j] += alpha*(np.sum((y - h) * X[:, j]) / m)就是套用上面给定的参数更新公式进行迭代。
四、打印散点图和线性回归图像及数据集处理
1.数据集处理
(1)代码思路
数据集使用的是鸢尾花数据集,因为还不会多维的在图像上表示,所以我取的是鸢尾花数据集的"Sepal.Length" "Sepal.Width" 两列来代表二维坐标轴的横纵坐标。
打印一下我的数据:
因为实验是二分类,所以我挑选的是鸢尾花数据集中的setosa和versicolor类别。为了方便我将versicolor赋值为0,setosa赋值为1.最后得到整合的数据。
对迭代次数赋值为1000,步长alafa赋值为0.01。
(2)代码展现
data = pd.read_csv(r"C:\\Users\\李烨\\Desktop\\ljhg.txt", sep=' ')
X = data.iloc[:, :2].values
y1 = data.iloc[:, -1].values
#print(X);
len1=len(y1);
y=np.zeros(len1);
for i in range(len1):
if y1[i] == 'setosa':
y[i]=1
if y1[i] == 'versicolor':
y[i]=0
#print(y)
X = np.c_[np.ones(X.shape[0]), X]
num = 1000
alafa = 0.1 2.散点图
思路解析:
用plt.rcParams['font.sans-serif'] = ['SimHei']使得图像上面可以正常显示中文。
用plt.scatter将数据中的点都画到图上
代码展现:
plt.rcParams['font.sans-serif'] = ['SimHei']
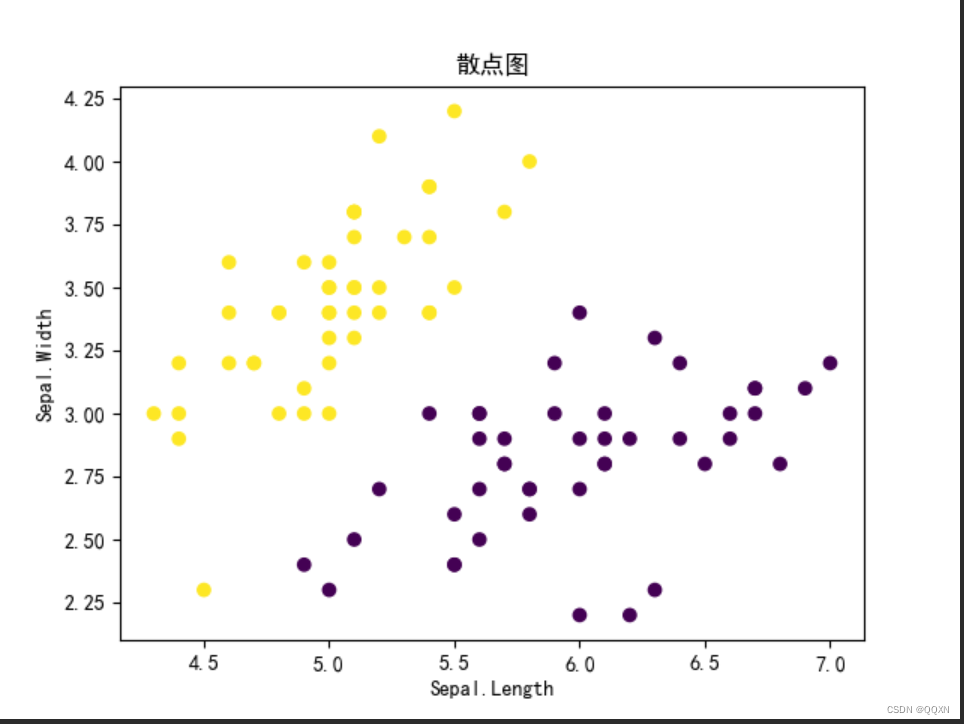
plt.scatter(X[:, 1], X[:, 2], c=y, cmap='viridis')
plt.xlabel('Sepal.Length')
plt.ylabel('Sepal.Width')
plt.title('散点图')
plt.show()运行结果截图:
3.逻辑回归曲线
代码解析:
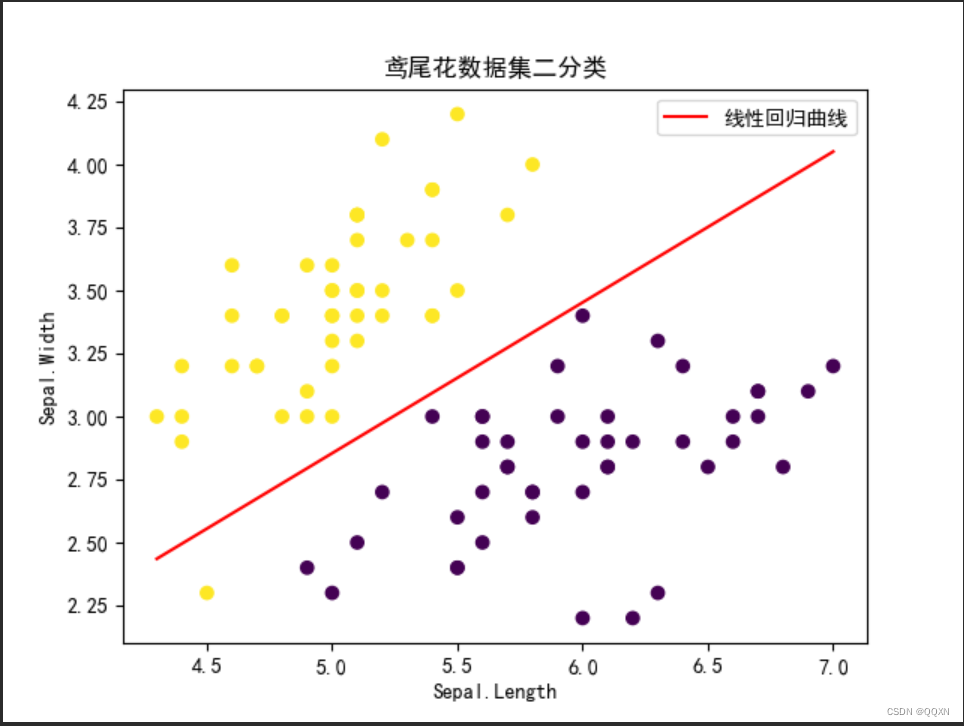
因为我们要连接这一条直线,直线其实是很多的点连接起来的,我们就在x的范围内平均取100个点,因为我们的特征只有两个,我们的线性回归方程为。所以第二个特征的解析式x2的取值就为代码所示。然后就是把点代入得到直线。
当然我们看到总共代码有一些和散点图中的重复。但是还得再敲一遍代码,因为plt.show()会把当前的图像打印出来,并不会保留。
代码展现:
xi = np.linspace(np.min(X[:, 1]), np.max(X[:, 1]), 100)
yi = -(theta[0] + theta[1] * xi) / theta[2]
plt.scatter(X[:, 1], X[:, 2], c=y, cmap='viridis')
plt.plot(xi, yi, "r-", label='线性回归曲线')
plt.xlabel('Sepal.Length')
plt.ylabel('Sepal.Width')
plt.title('鸢尾花数据集二分类')
plt.legend()
plt.show()运行截图:
五、利用逻辑回归进行分类
代码思路:
导入测试集,处理一下数据。
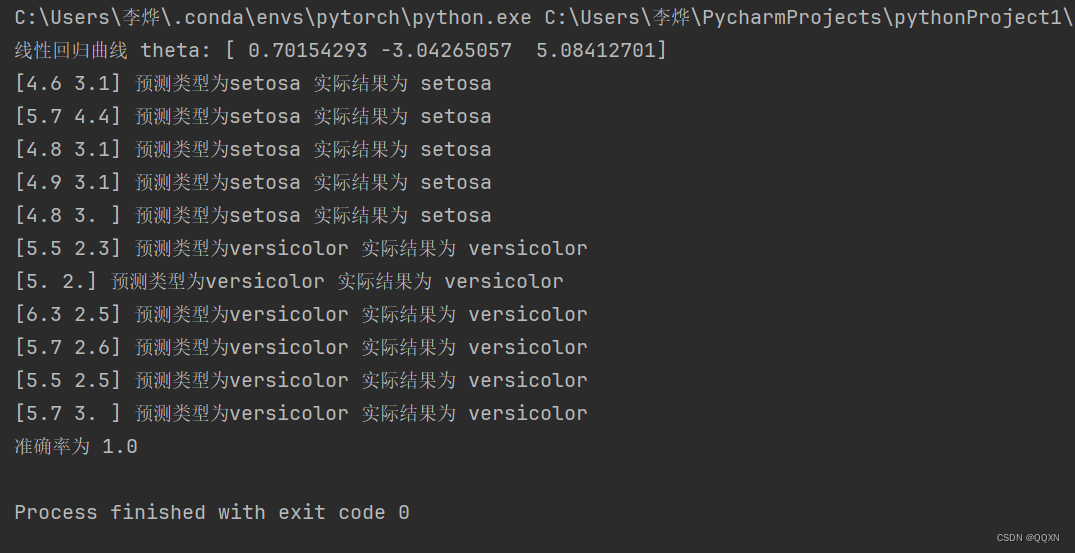
将每一个数据代入到线性回归方程上,得到一个值,这个值的取值就是负无穷到正无穷,代入到sigmoid函数上映射到0,1上,如果大等于0.5就将其分类为正类,否则就是分类为负类,如果分类正确就记录下来。以此得到准确率
代码展现:
test_data = pd.read_csv("C:\\Users\\李烨\\Desktop\\ljhgtest.txt", sep='\s+')
X_test = test_data[["Sepal.Length", "Sepal.Width"]].values
y_test = test_data["Species"].values
cnt=len(y_test)
#print(X_test[1][0])
num=0
for i in range(cnt):
t = theta[0] + theta[1] * X_test[i][0] + theta[2] * X_test[i][1]
res1 = res1 = sigmoid(t)
print(X_test[i],end=' ')
flag=0
if res1 >= 0.5 :
flag=1
print(f"预测类型为setosa",end=' ')
else :
print(f"预测类型为versicolor",end=' ')
print("实际结果为",y_test[i])
if flag==1 and y_test[i]=='setosa':
num=num+1
if flag==0 and y_test[i]=='versicolor':
num=num+1
print("准确率为",num/cnt)运行截图:
六、实验中遇到的问题
(1)本来以为逻辑回归这是简单的线性回归加上sigmoid函数,但是逻辑回归中得到的线和线性回归中得到的不太一样,线性回归中得到的好像是只有一个类别的拟合函数,而逻辑回归得到的是将多个类别分开的曲线,二者的性质不太一样。
(2)对似然函数的求导化简过程需要先取对数减少计算量,靠查阅资料得到化简后的函数,进而得到参数更新的公式。
(3)学习率的选取上需要选择合适的数据,太大太小都会影响程序的准确率。
(4)对于实验数据的选择,实验实现二分类,如果样本特征太多的话,就会导致在坐标轴上无法正确画出图像,我在实验运行选取的是在二维上,所以只选取两个特征。当然我的程序是可以分类多特征值的算法,公式就可以保证我的算法可以解决多特征值的算法,但是特征太多就无法正确映射到坐标轴上。
七、逻辑回归的优缺点
优点:
- 输出值自然地落在0到1之间,类比到概率
- 参数代表每个特征对输出的影响
- 时间空间复杂度低,计算量小
缺点:
- 因为它本质上是一个线性的分类器,所以处理不好特征之间相关的情况。
- 容易欠拟合,精度不高
八、实验的改进
(1)实验中可以实现从二分类到多分类的算法,
(2)实验中的梯度上升可以升级为随机梯度上升
随机梯度和梯度的区别主要是在梯度上升每次迭代使用整个训练集计算梯度,然后更新参数;而随机梯度上升每次迭代只使用一个样本数据计算梯度,并更新参数。
修改我的代码改为随机梯度上升只需要修改td函数,两个函数大差不差。
def sgd(X, y, num, alpha):
m, n = X.shape
theta = np.zeros(n)
for j in range(num):
for i in range(m):
pos = np.random.randint(0, m)
h = sigmoid(np.dot(X[pos], theta))
theta += alpha * (y[pos] - h) * X[pos]
return theta与梯度上升相比随机梯度上升的优缺点:
随机梯度上升在每次迭代中只需要计算一个样本数据的梯度,因此通常比梯度上升更快。但是由于每次只用一个样本就会导致曲线的效果没那么好。
九、总代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def sigmoid(z):
return 1.00 / (1.00 + np.exp(-z))
def sr(X, y, theta):
m = len(y)
h = sigmoid(X.dot(theta))
res = (1 / m) * (y.dot(np.log(h)) + (1 - y).dot(np.log(1 - h)))
return res
def td(X, y, num_iterations, alpha):
m, n = X.shape
theta = np.zeros(n)
for iteration in range(num_iterations):
h = sigmoid(np.dot(X, theta))
for j in range(n):
theta[j] += alpha*(np.sum((y - h) * X[:, j]) / m)
return theta
data = pd.read_csv(r"C:\\Users\\李烨\\Desktop\\ljhg.txt", sep=' ')
X = data.iloc[:, :2].values
y1 = data.iloc[:, -1].values
#print(X)
len1 = len(y1)
y=np.zeros(len1)
for i in range(len1):
if y1[i] == 'setosa':
y[i]=1
if y1[i] == 'versicolor':
y[i]=0
#print(y)
X = np.c_[np.ones(X.shape[0]), X]
num = 1000
alafa = 0.1
theta = td(X, y, num, alafa)
print("线性回归曲线 theta:", theta)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.scatter(X[:, 1], X[:, 2], c=y, cmap='viridis')
plt.xlabel('Sepal.Length')
plt.ylabel('Sepal.Width')
plt.title('散点图')
plt.show()
xi = np.linspace(np.min(X[:, 1]), np.max(X[:, 1]), 100)
yi = -(theta[0] + theta[1] * xi) / theta[2]
plt.scatter(X[:, 1], X[:, 2], c=y, cmap='viridis')
plt.plot(xi, yi, "r-", label='线性回归曲线')
plt.xlabel('Sepal.Length')
plt.ylabel('Sepal.Width')
plt.title('鸢尾花数据集二分类')
plt.legend()
plt.show()
test_data = pd.read_csv("C:\\Users\\李烨\\Desktop\\ljhgtest.txt", sep='\s+')
X_test = test_data[["Sepal.Length", "Sepal.Width"]].values
y_test = test_data["Species"].values
cnt=len(y_test)
#print(X_test[1][0])
num=0
for i in range(cnt):
t = theta[0] + theta[1] * X_test[i][0] + theta[2] * X_test[i][1]
res1 = sigmoid(t)
print(X_test[i],end=' ')
flag=0
if res1 >= 0.5 :
flag=1
print(f"预测类型为setosa",end=' ')
else :
print(f"预测类型为versicolor",end=' ')
print("实际结果为",y_test[i])
if flag==1 and y_test[i]=='setosa':
num=num+1
if flag==0 and y_test[i]=='versicolor':
num=num+1
print("准确率为",num/cnt)














 1128
1128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









