






把detection和phrase ground(对于给定的sentence,要定位其中提到的全部物体)这两个任务合起来变成统一框架,从而扩展数据来源,因为文本图像对的数据还是很好收集的
目标检测的loss是分类loss+定位loss,它与phrase ground的定位loss差不多,但是二者分类loss不同,因为对于目标检测,它的标签是一个或者两个单词,是one-hot标签,但是对于vision grounding它的标签是一个句子
目标检测的分类loss:分类头预测bonding box类别,nms排序,跟ground truth算交叉熵
vision grounding的分类loss:先计算匹配分数s,看看图像中的区域和句子中的单词是怎么匹配的。图像经过image backbone得到一些region feature,但是接下来不用分类头,而是一个文本编码器生成的文本特征做相似度计算,得到s
改动:判断什么时候算是一个positive match,什么时候算是negative match。当这些sub-words的phrase与目标region匹配时,每个positive sub-word都与目标region所匹配。例如,吹风机的phrase是“Hair dryer”,那么吹风机的region就会与“Hair”和“dryer”这两个词都匹配
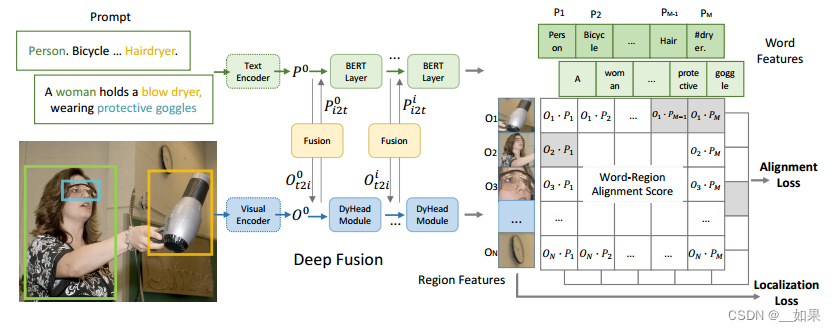
中间的deep fusion是加几个层让文本和图像的模态信息融合得更好一点















 2971
2971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









