







一、DINOv

效果:视觉提示通用分割、视觉提示参照分割、zero-shot视频对象和部分分割

出发点:在视觉领域利用LLMs做上下文提示(in-context prompting)
贡献:
1)我们是第一个扩展视觉上下文提示来支持通用视觉任务,如开放集通用分割和检测,并实现与基于文本提示的开放集模型相当的性能。
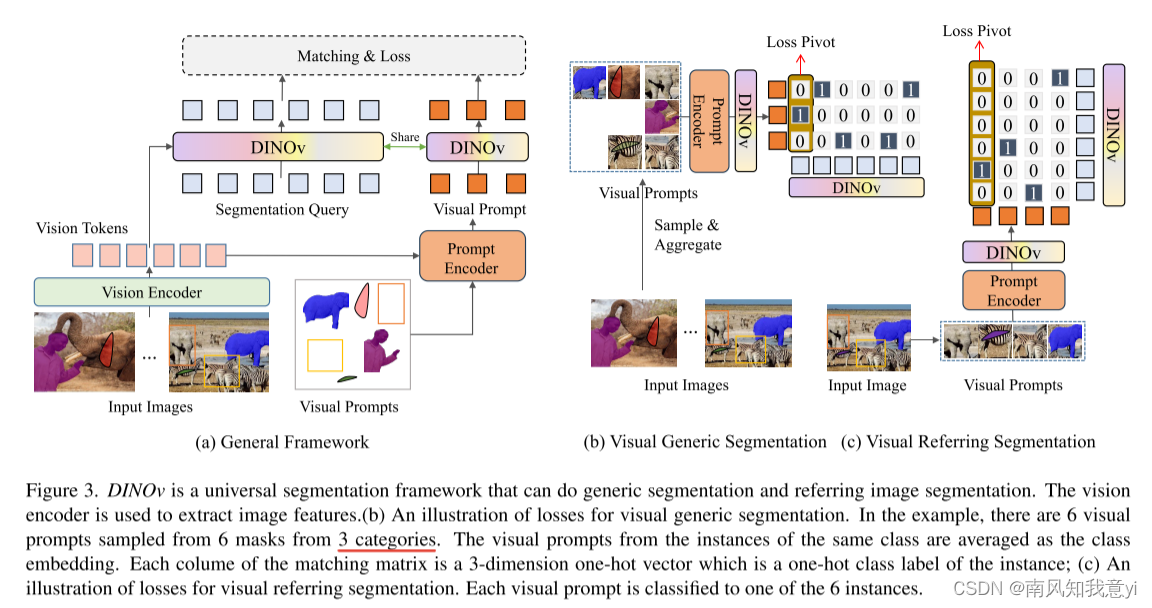
2)我们构建了DINOv,一个基于视觉上下文提示的参考分词和通用分词的统一框架。这种统一简化了模型设计,并允许我们的模型同时使用语义标记和未标记的数据,以获得更好的性能。
3)我们进行了大量的实验和可视化,以表明我们的模型可以处理通用、参考和视频对象分割任务。我们的早期尝试在开放集分割和视觉提示检测方面显示出有希望的结果。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1261
1261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









