






目录
模型、提示和解析器
模型
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(temperature=0.0)ChatOpenAI的默认模型为gpt-3.5-turbo
提示模板
from langchain.prompts import ChatPromptTemplate
template_string = """把由三个反引号分隔的文本\
翻译成一种{style}风格。\
文本: ```{text}```
"""
# 然后,我们调用`ChatPromptTemplatee.from_template()`函数将
# 上面的提示模版字符`template_string`转换为提示模版`prompt_template`
prompt_template = ChatPromptTemplate.from_template(template_string)
customer_style = """正式普通话 \
用一个平静、尊敬的语气
"""
customer_email = """
嗯呐,我现在可是火冒三丈,我那个搅拌机盖子竟然飞了出去,把我厨房的墙壁都溅上了果汁!
更糟糕的是,保修条款可不包括清理我厨房的费用。
伙计,赶紧给我过来!
"""
# 使用提示模版
customer_messages = prompt_template.format_messages(
style=customer_style,
text=customer_email)输出解析器
review_template_2 = """\
对于以下文本,请从中提取以下信息::
礼物:该商品是作为礼物送给别人的吗?
如果是,则回答 是的;如果否或未知,则回答 不是。
交货天数:产品到达需要多少天? 如果没有找到该信息,则输出-1。
价钱:提取有关价值或价格的任何句子,并将它们输出为逗号分隔的 Python 列表。
文本: {text}
{format_instructions}
"""
prompt = ChatPromptTemplate.from_template(template=review_template_2)
from langchain.output_parsers import ResponseSchema
from langchain.output_parsers import StructuredOutputParser
gift_schema = ResponseSchema(name="礼物",
description="这件物品是作为礼物送给别人的吗?\
如果是,则回答 是的,\
如果否或未知,则回答 不是。")
delivery_days_schema = ResponseSchema(name="交货天数",
description="产品需要多少天才能到达?\
如果没有找到该信息,则输出-1。")
price_value_schema = ResponseSchema(name="价钱",
description="提取有关价值或价格的任何句子,\
并将它们输出为逗号分隔的 Python 列表")
response_schemas = [gift_schema,
delivery_days_schema,
price_value_schema]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
print("输出格式规定:",format_instructions)
"""
输出格式规定:
The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "```json" and "```":
```json
{
"礼物": string // 这件物品是作为礼物送给别人的吗? 如果是,则回答 是的, 如果否或未知,则回答 不是。
"交货天数": string // 产品需要多少天才能到达? 如果没有找到该信息,则输出-1。
"价钱": string // 提取有关价值或价格的任何句子, 并将它们输出为逗号分隔的 Python 列表
}
```
"""messages = prompt.format_messages(text=customer_review, format_instructions=format_instructions)
print("第一条客户消息:",messages[0].content)
"""
第一条客户消息:
对于以下文本,请从中提取以下信息::
礼物:该商品是作为礼物送给别人的吗?
如果是,则回答 是的;如果否或未知,则回答 不是。
交货天数:产品到达需要多少天? 如果没有找到该信息,则输出-1。
价钱:提取有关价值或价格的任何句子,并将它们输出为逗号分隔的 Python 列表。
文本: 这款吹叶机非常神奇。 它有四个设置:吹蜡烛、微风、风城、龙卷风。 两天后就到了,正好赶上我妻子的周年纪念礼物。 我想我的妻子会喜欢它到说不出话来。 到目前为止,我是唯一一个使用它的人,而且我一直每隔一天早上用它来清理草坪上的叶子。 它比其他吹叶机稍微贵一点,但我认为它的额外功能是值得的。
The output should be a markdown code snippet formatted in the following schema, including the leading and trailing "```json" and "```":
```json
{
"礼物": string // 这件物品是作为礼物送给别人的吗? 如果是,则回答 是的, 如果否或未知,则回答 不是。
"交货天数": string // 产品需要多少天才能到达? 如果没有找到该信息,则输出-1。
"价钱": string // 提取有关价值或价格的任何句子, 并将它们输出为逗号分隔的 Python 列表
}
```
"""response = chat(messages)
print("结果类型:", type(response.content))
print("结果:", response.content)
"""
结果类型:
<class 'str'>
结果:
```json
{
"礼物": "不是",
"交货天数": "两天后就到了",
"价钱": "它比其他吹叶机稍微贵一点"
}
```
"""output_dict = output_parser.parse(response.content)
print("解析后的结果类型:", type(output_dict))
print("解析后的结果:", output_dict)
"""
解析后的结果类型:
<class 'dict'>
解析后的结果:
{'礼物': '不是', '交货天数': '两天后就到了', '价钱': '它比其他吹叶机稍微贵一点'}
"""output_dict类型为字典(dict), 可直接使用get方法
存储
将先前的对话嵌入到语言模型中,使其具有连续对话的能力
对话缓存储存
初始化对话模型
from langchain.chains import ConversationChain
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
# 这里我们将参数temperature设置为0.0,从而减少生成答案的随机性。
# 如果你想要每次得到不一样的有新意的答案,可以尝试增大该参数。
llm = ChatOpenAI(temperature=0.0)
memory = ConversationBufferMemory()
# 新建一个 ConversationChain Class 实例
# verbose参数设置为True时,程序会输出更详细的信息,以提供更多的调试或运行时信息。
# 相反,当将verbose参数设置为False时,程序会以更简洁的方式运行,只输出关键的信息。
conversation = ConversationChain(llm=llm, memory = memory, verbose=True )
第一轮对话
conversation.predict(input="你好, 我叫皮皮鲁")
"""
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 你好, 我叫皮皮鲁
AI:
> Finished chain.
'你好,皮皮鲁!很高兴认识你。我是一个AI助手,可以回答你的问题和提供帮助。有什么我可以帮你的吗?'
"""第二轮对话
conversation.predict(input="1+1等于多少?")
"""
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 你好, 我叫皮皮鲁
AI: 你好,皮皮鲁!很高兴认识你。我是一个AI助手,可以回答你的问题和提供帮助。有什么我可以帮你的吗?
Human: 1+1等于多少?
AI:
> Finished chain.
'1+1等于2。'
"""当我们进行第二轮对话时,它会保留上面的提示
第三轮对话
为了验证他是否记忆了前面的对话内容,我们让他回答前面已经说过的内容(我的名字)
conversation.predict(input="我叫什么名字?")
"""
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 你好, 我叫皮皮鲁
AI: 你好,皮皮鲁!很高兴认识你。我是一个AI助手,可以回答你的问题和提供帮助。有什么我可以帮你的吗?
Human: 1+1等于多少?
AI: 1+1等于2。
Human: 我叫什么名字?
AI:
> Finished chain.
'你叫皮皮鲁。'
"""查看储存缓存
print(memory.buffer)
"""
Human: 你好, 我叫皮皮鲁
AI: 你好,皮皮鲁!很高兴认识你。我是一个AI助手,可以回答你的问题和提供帮助。有什么我可以帮你的吗?
Human: 1+1等于多少?
AI: 1+1等于2。
Human: 我叫什么名字?
AI: 你叫皮皮鲁。
"""也可以通过load_memory_variables({})打印缓存中的历史消息
print(memory.load_memory_variables({}))
"""
{'history': 'Human: 你好, 我叫皮皮鲁\nAI: 你好,皮皮鲁!很高兴认识你。我是一个AI助手,可以回答你的问题和提供帮助。有什么我可以帮你的吗?\nHuman: 1+1等于多少?\nAI: 1+1等于2。\nHuman: 我叫什么名字?\nAI: 你叫皮皮鲁。'}
"""直接添加内容到储存缓存
memory = ConversationBufferMemory()
memory.save_context({"input": "你好,我叫皮皮鲁"}, {"output": "你好啊,我叫鲁西西"})
memory.load_memory_variables({})
“”“
{'history': 'Human: 你好,我叫皮皮鲁\nAI: 你好啊,我叫鲁西西'}
”“”对话缓存窗口储存
只保留一个窗口大小的对话。它只使用最近的n次交互。这可以用于保持最近交互的滑动窗口,以便缓冲区不会过大
添加两轮对话到窗口储存
from langchain.memory import ConversationBufferWindowMemory
# k=1表明只保留一个对话记忆
memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "你好,我叫皮皮鲁"}, {"output": "你好啊,我叫鲁西西"})
memory.save_context({"input": "很高兴和你成为朋友!"}, {"output": "是的,让我们一起去冒险吧!"})
memory.load_memory_variables({})
"""
{'history': 'Human: 很高兴和你成为朋友!\nAI: 是的,让我们一起去冒险吧!'}
"""通过结果,我们可以看到窗口储存中只有最后一轮的聊天记录
在对话链中应用窗口储存
llm = ChatOpenAI(temperature=0.0)
memory = ConversationBufferWindowMemory(k=1)
conversation = ConversationChain(llm=llm, memory=memory, verbose=False )
print("第一轮对话:")
print(conversation.predict(input="你好, 我叫皮皮鲁"))
print("第二轮对话:")
print(conversation.predict(input="1+1等于多少?"))
print("第三轮对话:")
print(conversation.predict(input="我叫什么名字?"))
"""
第一轮对话:
你好,皮皮鲁!很高兴认识你。我是一个AI助手,可以回答你的问题和提供帮助。有什么我可以帮你的吗?
第二轮对话:
1+1等于2。
第三轮对话:
很抱歉,我无法知道您的名字。
"""由于这里用的是一个窗口的记忆,因此只能保存一轮的历史消息,因此AI并不能知道你第一轮对话中提到的名字,他最多只能记住上一轮(第二轮)的对话信息
对话字符缓存储存
使用对话字符缓存记忆,内存将限制保存的token数量。如果字符数量超出指定数目,它会切掉这个对话的早期部分 以保留与最近的交流相对应的字符数量,但不超过字符限制
from langchain.llms import OpenAI
from langchain.memory import ConversationTokenBufferMemory
memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=30)
memory.save_context({"input": "朝辞白帝彩云间,"}, {"output": "千里江陵一日还。"})
memory.save_context({"input": "两岸猿声啼不住,"}, {"output": "轻舟已过万重山。"})
memory.load_memory_variables({})
"""
{'history': 'AI: 轻舟已过万重山。'}
"""ChatGPT 使用一种基于字节对编码(Byte Pair Encoding,BPE)的方法来进行 tokenization
对话摘要缓存储存
使用对话摘要缓存储存
from langchain.chains import ConversationChain
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationSummaryBufferMemory
# 创建一个长字符串
schedule = "在八点你和你的产品团队有一个会议。 \
你需要做一个PPT。 \
上午9点到12点你需要忙于LangChain。\
Langchain是一个有用的工具,因此你的项目进展的非常快。\
中午,在意大利餐厅与一位开车来的顾客共进午餐 \
走了一个多小时的路程与你见面,只为了解最新的 AI。 \
确保你带了笔记本电脑可以展示最新的 LLM 样例."
llm = ChatOpenAI(temperature=0.0)
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=100)
memory.save_context({"input": "你好,我叫皮皮鲁"}, {"output": "你好啊,我叫鲁西西"})
memory.save_context({"input": "很高兴和你成为朋友!"}, {"output": "是的,让我们一起去冒险吧!"})
memory.save_context({"input": "今天的日程安排是什么?"}, {"output": f"{schedule}"})
print(memory.load_memory_variables({})['history'])
"""
System: The human introduces themselves as Pipilu and the AI introduces themselves as Luxixi. They express happiness at becoming friends and decide to go on an adventure together. The human asks about the schedule for the day. The AI informs them that they have a meeting with their product team at 8 o'clock and need to prepare a PowerPoint presentation. From 9 am to 12 pm, they will be busy with LangChain, a useful tool that helps their project progress quickly. At noon, they will have lunch with a customer who has driven for over an hour just to learn about the latest AI. The AI advises the human to bring their laptop to showcase the latest LLM samples.
"""基于对话摘要缓存储存的对话链
conversation = ConversationChain(llm=llm, memory=memory, verbose=True)
conversation.predict(input="展示什么样的样例最好呢?")
"""
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
System: The human introduces themselves as Pipilu and the AI introduces themselves as Luxixi. They express happiness at becoming friends and decide to go on an adventure together. The human asks about the schedule for the day. The AI informs them that they have a meeting with their product team at 8 o'clock and need to prepare a PowerPoint presentation. From 9 am to 12 pm, they will be busy with LangChain, a useful tool that helps their project progress quickly. At noon, they will have lunch with a customer who has driven for over an hour just to learn about the latest AI. The AI advises the human to bring their laptop to showcase the latest LLM samples.
Human: 展示什么样的样例最好呢?
AI:
> Finished chain.
'展示一些具有多样性和创新性的样例可能是最好的选择。你可以展示一些不同领域的应用,比如自然语言处理、图像识别、语音合成等。另外,你也可以展示一些具有实际应用价值的样例,比如智能客服、智能推荐等。总之,选择那些能够展示出我们AI技术的强大和多样性的样例会给客户留下深刻的印象。'
"""print(memory.load_memory_variables({})) # 摘要记录更新了
"""
{'history': "System: The human introduces themselves as Pipilu and the AI introduces themselves as Luxixi. They express happiness at becoming friends and decide to go on an adventure together. The human asks about the schedule for the day. The AI informs them that they have a meeting with their product team at 8 o'clock and need to prepare a PowerPoint presentation. From 9 am to 12 pm, they will be busy with LangChain, a useful tool that helps their project progress quickly. At noon, they will have lunch with a customer who has driven for over an hour just to learn about the latest AI. The AI advises the human to bring their laptop to showcase the latest LLM samples. The human asks what kind of samples would be best to showcase. The AI suggests that showcasing diverse and innovative samples would be the best choice. They recommend demonstrating applications in different fields such as natural language processing, image recognition, and speech synthesis. Additionally, they suggest showcasing practical examples like intelligent customer service and personalized recommendations to impress the customer with the power and versatility of their AI technology."}
"""通过对比上一次输出,发现摘要记录更新了,添加了最新一次对话的内容总结
模型链
链(Chains)通常将大语言模型(LLM)与提示(Prompt)结合在一起,基于此,我们可以对文本或数据进行一系列操作
大语言模型链
import warnings
warnings.filterwarnings('ignore')
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
# 这里我们将参数temperature设置为0.0,从而减少生成答案的随机性。
# 如果你想要每次得到不一样的有新意的答案,可以尝试调整该参数。
llm = ChatOpenAI(temperature=0.0)
prompt = ChatPromptTemplate.from_template("描述制造{product}的一个公司的最佳名称是什么?")
chain = LLMChain(llm=llm, prompt=prompt)
product = "小张"
chain.run(product)简单顺序链
from langchain.chains import SimpleSequentialChain
llm = ChatOpenAI(temperature=0.9)
# 提示模板 1 :这个提示将接受产品并返回最佳名称来描述该公司
first_prompt = ChatPromptTemplate.from_template(
"描述制造{product}的一个公司的最好的名称是什么"
)
chain_one = LLMChain(llm=llm, prompt=first_prompt)
# 提示模板 2 :接受公司名称,然后输出该公司的长为20个单词的描述
second_prompt = ChatPromptTemplate.from_template(
"写一个20字的描述对于下面这个\
公司:{company_name}的"
)
chain_two = LLMChain(llm=llm, prompt=second_prompt)
overall_simple_chain = SimpleSequentialChain(chains=[chain_one, chain_two],
verbose=True)
product = "大号床单套装"
overall_simple_chain.run(product)
"""
> Entering new SimpleSequentialChain chain...
优床制造公司
优床制造公司是一家专注于生产高品质床具的公司。
> Finished chain.
'优床制造公司是一家专注于生产高品质床具的公司。'
"""顺序链
import pandas as pd
from langchain.chains import SequentialChain
from langchain.chat_models import ChatOpenAI #导入OpenAI模型
from langchain.prompts import ChatPromptTemplate #导入聊天提示模板
from langchain.chains import LLMChain #导入LLM链。
llm = ChatOpenAI(temperature=0.9)
创建四个子链
#子链1
# prompt模板 1: 翻译成英语(把下面的review翻译成英语)
first_prompt = ChatPromptTemplate.from_template(
"把下面的评论review翻译成英文:"
"\n\n{Review}"
)
# chain 1: 输入:Review 输出:英文的 Review
chain_one = LLMChain(llm=llm, prompt=first_prompt, output_key="English_Review")
#子链2
# prompt模板 2: 用一句话总结下面的 review
second_prompt = ChatPromptTemplate.from_template(
"请你用一句话来总结下面的评论review:"
"\n\n{English_Review}"
)
# chain 2: 输入:英文的Review 输出:总结
chain_two = LLMChain(llm=llm, prompt=second_prompt, output_key="summary")
#子链3
# prompt模板 3: 下面review使用的什么语言
third_prompt = ChatPromptTemplate.from_template(
"下面的评论review使用的什么语言:\n\n{Review}"
)
# chain 3: 输入:Review 输出:语言
chain_three = LLMChain(llm=llm, prompt=third_prompt, output_key="language")
#子链4
# prompt模板 4: 使用特定的语言对下面的总结写一个后续回复
fourth_prompt = ChatPromptTemplate.from_template(
"使用特定的语言对下面的总结写一个后续回复:"
"\n\n总结: {summary}\n\n语言: {language}"
)
# chain 4: 输入: 总结, 语言 输出: 后续回复
chain_four = LLMChain(llm=llm, prompt=fourth_prompt, output_key="followup_message")
对四个子链进行组合
#输入:review
#输出:英文review,总结,后续回复
overall_chain = SequentialChain(
chains=[chain_one, chain_two, chain_three, chain_four],
input_variables=["Review"],
output_variables=["English_Review", "summary","followup_message"],
verbose=True
)
df = pd.read_csv('../data/Data.csv')
review = df.Review[5]
overall_chain(review)
"""
> Entering new SequentialChain chain...
> Finished chain.
{'Review': "Je trouve le goût médiocre. La mousse ne tient pas, c'est bizarre. J'achète les mêmes dans le commerce et le goût est bien meilleur...\nVieux lot ou contrefaçon !?",
'English_Review': "I find the taste mediocre. The foam doesn't hold, it's weird. I buy the same ones in stores and the taste is much better...\nOld batch or counterfeit!?",
'summary': "The reviewer finds the taste mediocre, the foam doesn't hold well, and suspects the product may be either an old batch or a counterfeit.",
'followup_message': "后续回复(法语):Merci beaucoup pour votre avis. Nous sommes désolés d'apprendre que vous avez trouvé le goût médiocre et que la mousse ne tient pas bien. Nous prenons ces problèmes très au sérieux et nous enquêterons sur la possibilité que le produit soit soit un ancien lot, soit une contrefaçon. Nous vous prions de nous excuser pour cette expérience décevante et nous ferons tout notre possible pour résoudre ce problème. Votre satisfaction est notre priorité et nous apprécions vos commentaires précieux."}
"""路由链
如果你有多个子链,每个子链都专门用于特定类型的输入,那么可以组成一个路由链,它首先决定将它传递给哪个子链,然后将它传递给那个链
路由器由两个组件组成:
- 路由链(Router Chain):路由器链本身,负责选择要调用的下一个链
- destination_chains:路由器链可以路由到的链
from langchain.chains.router import MultiPromptChain #导入多提示链
from langchain.chains.router.llm_router import LLMRouterChain,RouterOutputParser
from langchain.prompts import PromptTemplate
llm = ChatOpenAI(temperature=0)
定义提示模板
# 中文
#第一个提示适合回答物理问题
physics_template = """你是一个非常聪明的物理专家。 \
你擅长用一种简洁并且易于理解的方式去回答问题。\
当你不知道问题的答案时,你承认\
你不知道.
这是一个问题:
{input}"""
#第二个提示适合回答数学问题
math_template = """你是一个非常优秀的数学家。 \
你擅长回答数学问题。 \
你之所以如此优秀, \
是因为你能够将棘手的问题分解为组成部分,\
回答组成部分,然后将它们组合在一起,回答更广泛的问题。
这是一个问题:
{input}"""
#第三个适合回答历史问题
history_template = """你是以为非常优秀的历史学家。 \
你对一系列历史时期的人物、事件和背景有着极好的学识和理解\
你有能力思考、反思、辩证、讨论和评估过去。\
你尊重历史证据,并有能力利用它来支持你的解释和判断。
这是一个问题:
{input}"""
#第四个适合回答计算机问题
computerscience_template = """ 你是一个成功的计算机科学专家。\
你有创造力、协作精神、\
前瞻性思维、自信、解决问题的能力、\
对理论和算法的理解以及出色的沟通技巧。\
你非常擅长回答编程问题。\
你之所以如此优秀,是因为你知道 \
如何通过以机器可以轻松解释的命令式步骤描述解决方案来解决问题,\
并且你知道如何选择在时间复杂性和空间复杂性之间取得良好平衡的解决方案。
这还是一个输入:
{input}"""
对提示模板进行命名和描述
# 中文
prompt_infos = [
{
"名字": "物理学",
"描述": "擅长回答关于物理学的问题",
"提示模板": physics_template
},
{
"名字": "数学",
"描述": "擅长回答数学问题",
"提示模板": math_template
},
{
"名字": "历史",
"描述": "擅长回答历史问题",
"提示模板": history_template
},
{
"名字": "计算机科学",
"描述": "擅长回答计算机科学问题",
"提示模板": computerscience_template
}
]
基于提示模版信息创建相应目标链
destination_chains = {}
for p_info in prompt_infos:
name = p_info["名字"]
prompt_template = p_info["提示模板"]
prompt = ChatPromptTemplate.from_template(template=prompt_template)
chain = LLMChain(llm=llm, prompt=prompt)
destination_chains[name] = chain
destinations = [f"{p['名字']}: {p['描述']}" for p in prompt_infos]
destinations_str = "\n".join(destinations)
创建默认目标链
当路由器无法决定使用哪个子链时调用的链
default_prompt = ChatPromptTemplate.from_template("{input}")
default_chain = LLMChain(llm=llm, prompt=default_prompt)
定义不同链之间的路由模板
# 多提示路由模板
MULTI_PROMPT_ROUTER_TEMPLATE = """给语言模型一个原始文本输入,\
让其选择最适合输入的模型提示。\
系统将为您提供可用提示的名称以及最适合改提示的描述。\
如果你认为修改原始输入最终会导致语言模型做出更好的响应,\
你也可以修改原始输入。
<< 格式 >>
返回一个带有JSON对象的markdown代码片段,该JSON对象的格式如下:
```json
{{{{
"destination": 字符串 \ 使用的提示名字或者使用 "DEFAULT"
"next_inputs": 字符串 \ 原始输入的改进版本
}}}}
记住:“destination”必须是下面指定的候选提示名称之一,\
或者如果输入不太适合任何候选提示,\
则可以是 “DEFAULT” 。
记住:如果您认为不需要任何修改,\
则 “next_inputs” 可以只是原始输入。
<< 候选提示 >>
{destinations}
<< 输入 >>
{{input}}
<< 输出 (记得要包含 ```json)>>
样例:
<< 输入 >>
"什么是黑体辐射?"
<< 输出 >>
```json
{{{{
"destination": 字符串 \ 使用的提示名字或者使用 "DEFAULT"
"next_inputs": 字符串 \ 原始输入的改进版本
}}}}
"""
构建路由链
这里有路由输出解析,这很重要,因为它将帮助这个链路决定在哪些子链路之间进行路由。
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(
destinations=destinations_str
)
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser(),
)
router_chain = LLMRouterChain.from_llm(llm, router_prompt)
创建整体链路
#多提示链
chain = MultiPromptChain(router_chain=router_chain, #l路由链路
destination_chains=destination_chains, #目标链路
default_chain=default_chain, #默认链路
verbose=True
)
进行提问
chain.run("什么是黑体辐射?")
"""
> Entering new MultiPromptChain chain...
物理学: {'input': '什么是黑体辐射?'}
> Finished chain.
'黑体辐射是指一个理想化的物体,它能够完全吸收并且以最高效率地辐射出所有入射到它上面的电磁辐射。这种辐射的特点是它的辐射强度与波长有关,且在不同波长下的辐射强度符合普朗克辐射定律。黑体辐射在物理学中有广泛的应用,例如研究热力学、量子力学和宇宙学等领域。'
"""基于文档QA
直接使用向量储存查询
from langchain.chains import RetrievalQA #检索QA链,在文档上进行检索
from langchain.chat_models import ChatOpenAI #openai模型
from langchain.document_loaders import CSVLoader #文档加载器,采用csv格式存储
from langchain.vectorstores import DocArrayInMemorySearch #向量存储
from IPython.display import display, Markdown #在jupyter显示信息的工具
import pandas as pd
file = '../data/OutdoorClothingCatalog_1000.csv'
# 使用langchain文档加载器对数据进行导入
loader = CSVLoader(file_path=file)
# 使用pandas导入数据,用以查看
data = pd.read_csv(file,usecols=[1, 2])
data.head()
基本文档加载器创建向量存储
#导入向量存储索引创建器
from langchain.indexes import VectorstoreIndexCreator
# 创建指定向量存储类, 创建完成后,从加载器中调用, 通过文档加载器列表加载
index = VectorstoreIndexCreator(vectorstore_cls=DocArrayInMemorySearch).from_loaders([loader])
查询创建的向量储存
query ="请用markdown表格的方式列出所有具有防晒功能的衬衫,对每件衬衫描述进行总结"
#使用索引查询创建一个响应,并传入这个查询
response = index.query(query)
#查看查询返回的内容
display(Markdown(response))

结合表征模型和向量存储
使用文本嵌入(Embeddings)算法对文档进行向量化,使语义相似的文本片段具有接近的向量表示。其次,将向量化的文档切分为小块,存入向量数据库
#创建一个文档加载器,通过csv格式加载
file = '../data/OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file)
docs = loader.load()
#查看单个文档,每个文档对应于CSV中的一行数据
docs[0]
文本向量表征模型
#使用OpenAIEmbedding类
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
#因为文档比较短了,所以这里不需要进行任何分块,可以直接进行向量表征
#使用初始化OpenAIEmbedding实例上的查询方法embed_query为文本创建向量表征
embed = embeddings.embed_query("你好呀,我的名字叫小可爱")
#查看得到向量表征的长度
print("\n\033[32m向量表征的长度: \033[0m \n", len(embed))
#每个元素都是不同的数字值,组合起来就是文本的向量表征
print("\n\033[32m向量表征前5个元素: \033[0m \n", embed[:5])
"""
向量表征的长度:
1536
向量表征前5个元素:
[-0.019283676849006164, -0.006842594710511029, -0.007344046732916966, -0.024501312942119265, -0.026608679897592472]
"""基于向量表征创建并查询向量存储
# 将刚才创建文本向量表征(embeddings)存储在向量存储(vector store)中
# 使用DocArrayInMemorySearch类的from_documents方法来实现
# 该方法接受文档列表以及向量表征模型作为输入
db = DocArrayInMemorySearch.from_documents(docs, embeddings)
query = "请推荐一件具有防晒功能的衬衫"
#使用上面的向量存储来查找与传入查询类似的文本,得到一个相似文档列表
docs = db.similarity_search(query)
print("\n\033[32m返回文档的个数: \033[0m \n", len(docs))
print("\n\033[32m第一个文档: \033[0m \n", docs[0])
"""
返回文档的个数:
4
第一个文档:
page_content=": 535\nname: Men's TropicVibe Shirt, Short-Sleeve\ndescription: This Men’s sun-protection shirt with built-in UPF 50+ has the lightweight feel you want and the coverage you need when the air is hot and the UV rays are strong. Size & Fit: Traditional Fit: Relaxed through the chest, sleeve and waist. Fabric & Care: Shell: 71% Nylon, 29% Polyester. Lining: 100% Polyester knit mesh. UPF 50+ rated – the highest rated sun protection possible. Machine wash and dry. Additional Features: Wrinkle resistant. Front and back cape venting lets in cool breezes. Two front bellows pockets. Imported.\n\nSun Protection That Won't Wear Off: Our high-performance fabric provides SPF 50+ sun protection, blocking 98% of the sun's harmful rays." metadata={'source': '../data/OutdoorClothingCatalog_1000.csv', 'row': 535}
"""使用查询结果构造提示来回答问题
#导入大语言模型, 这里使用默认模型gpt-3.5-turbo会出现504服务器超时,
#因此使用gpt-3.5-turbo-0301
llm = ChatOpenAI(model_name="gpt-3.5-turbo-0301",temperature = 0.0)
#合并获得的相似文档内容
qdocs = "".join([docs[i].page_content for i in range(len(docs))])
#将合并的相似文档内容后加上问题(question)输入到 `llm.call_as_llm`中
#这里问题是:以Markdown表格的方式列出所有具有防晒功能的衬衫并总结
response = llm.call_as_llm(f"{qdocs}问题:请用markdown表格的方式列出所有具有防晒功能的衬衫,对每件衬衫描述进行总结")
display(Markdown(response))
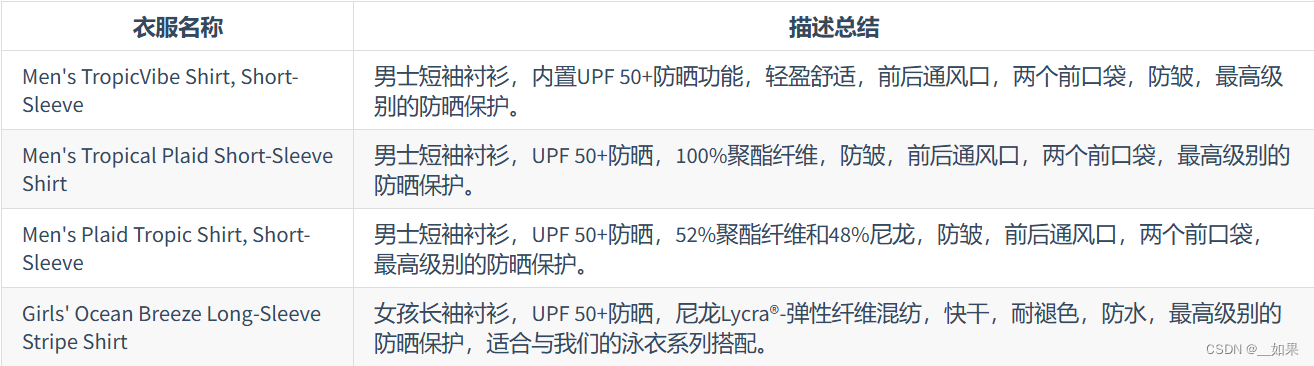
使用检索问答链来回答问题
chain_type: 传入链类型,这里使用stuff,将所有查询得到的文档组合成一个文档传入下一步。其他的方式包括:- Map Reduce: 将所有块与问题一起传递给语言模型,获取回复,使用另一个语言模型调用将所有单独的回复总结成最终答案,它可以在任意数量的文档上运行。可以并行处理单个问题,同时也需要更多的调用。它将所有文档视为独立的
- Refine: 用于循环许多文档,际上是迭代的,建立在先前文档的答案之上,非常适合前后因果信息并随时间逐步构建答案,依赖于先前调用的结果。它通常需要更长的时间,并且基本上需要与Map Reduce一样多的调用
- Map Re-rank: 对每个文档进行单个语言模型调用,要求它返回一个分数,选择最高分,这依赖于语言模型知道分数应该是什么,需要告诉它,如果它与文档相关,则应该是高分,并在那里精细调整说明,可以批量处理它们相对较快,但是更加昂贵
#基于向量储存,创建检索器
retriever = db.as_retriever()
qa_stuff = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
verbose=True
)
#创建一个查询并在此查询上运行链
query = "请用markdown表格的方式列出所有具有防晒功能的衬衫,对每件衬衫描述进行总结"
response = qa_stuff.run(query)
display(Markdown(response))

评估
手动去创建所有的问题集和答案集,那会是一个非常耗费时间和人力的成本。那有没有一种可以自动创建大量问答测试集的方法呢?那当然是有的,今天我们就来介绍 Langchain 提供的方法:QAGenerateChain
创建LLM应用
LLM生成测试用例
由于QAGenerateChain类中使用的PROMPT是英文,故我们继承QAGenerateChain类,将PROMPT加上“请使用中文输出”
from langchain.evaluation.qa import QAGenerateChain #导入QA生成链,它将接收文档,并从每个文档中创建一个问题答案对
# 下面是langchain.evaluation.qa.generate_prompt中的源码,在template的最后加上“请使用中文输出”
from langchain.output_parsers.regex import RegexParser
from langchain.prompts import PromptTemplate
from langchain.base_language import BaseLanguageModel
from typing import Any
template = """You are a teacher coming up with questions to ask on a quiz.
Given the following document, please generate a question and answer based on that document.
Example Format:
<Begin Document>
...
<End Document>
QUESTION: question here
ANSWER: answer here
These questions should be detailed and be based explicitly on information in the document. Begin!
<Begin Document>
{doc}
<End Document>
请使用中文输出
"""
output_parser = RegexParser(
regex=r"QUESTION: (.*?)\nANSWER: (.*)", output_keys=["query", "answer"]
)
PROMPT = PromptTemplate(
input_variables=["doc"], template=template, output_parser=output_parser
)
# 继承QAGenerateChain
class ChineseQAGenerateChain(QAGenerateChain):
"""LLM Chain specifically for generating examples for question answering."""
@classmethod
def from_llm(cls, llm: BaseLanguageModel, **kwargs: Any) -> QAGenerateChain:
"""Load QA Generate Chain from LLM."""
return cls(llm=llm, prompt=PROMPT, **kwargs)
example_gen_chain = ChineseQAGenerateChain.from_llm(ChatOpenAI())#通过传递chat open AI语言模型来创建这个链
new_examples = example_gen_chain.apply([{"doc": t} for t in data[:5]])
#查看用例数据
new_examples
"""
[{'qa_pairs': {'query': '这款全自动咖啡机的尺寸是多少?',
'answer': "大型尺寸为13.8'' x 17.3'',中型尺寸为11.5'' x 15.2''。"}},
{'qa_pairs': {'query': '这款电动牙刷的规格是什么?', 'answer': "一般大小 - 高度:9.5'',宽度:1''。"}},
{'qa_pairs': {'query': '这种产品的名称是什么?', 'answer': '这种产品的名称是橙味维生素C泡腾片。'}},
{'qa_pairs': {'query': '这款无线蓝牙耳机的尺寸是多少?',
'answer': "该无线蓝牙耳机的尺寸为1.5'' x 1.3''。"}},
{'qa_pairs': {'query': '这款瑜伽垫的尺寸是多少?', 'answer': "这款瑜伽垫的尺寸是24'' x 68''。"}}]
"""手动创建测试数据
examples = [
{
"query": "高清电视机怎么进行护理?",
"answer": "使用干布清洁。"
},
{
"query": "旅行背包有内外袋吗?",
"answer": "有。"
}
]
整合测试集
examples += [ v for item in new_examples for k,v in item.items()]
qa.run(examples[0]["query"])
"""
> Entering new RetrievalQA chain...
> Finished chain.
'高清电视机的护理非常简单。您只需要使用干布清洁即可。避免使用湿布或化学清洁剂,以免损坏电视机的表面。'
"""人工评估
打开debug,看看qa是如何找到问题的答案
import langchain
langchain.debug = True
#重新运行与上面相同的示例,可以看到它开始打印出更多的信息
qa.run(examples[0]["query"])
"""
[chain/start] [1:chain:RetrievalQA] Entering Chain run with input:
{
"query": "高清电视机怎么进行护理?"
}
[chain/start] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain] Entering Chain run with input:
[inputs]
[chain/start] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain > 4:chain:LLMChain] Entering Chain run with input:
{
"question": "高清电视机怎么进行护理?",
"context": "product_name: 高清电视机\ndescription: 规格:\n尺寸:50''。\n\n为什么我们热爱它:\n我们的高清电视机拥有出色的画质和强大的音效,带来沉浸式的观看体验。\n\n材质与护理:\n使用干布清洁。\n\n构造:\n由塑料、金属和电子元件制成。\n\n其他特性:\n支持网络连接,可以在线观看视频。\n配备遥控器。\n在韩国制造。\n\n有问题?请随时联系我们的客户服务团队,他们会解答您的所有问题。<<<<>>>>>product_name: 空气净化器\ndescription: 规格:\n尺寸:15'' x 15'' x 20''。\n\n为什么我们热爱它:\n我们的空气净化器采用了先进的HEPA过滤技术,能有效去除空气中的微粒和异味,为您提供清新的室内环境。\n\n材质与护理:\n清洁时使用干布擦拭。\n\n构造:\n由塑料和电子元件制成。\n\n其他特性:\n三档风速,附带定时功能。\n在德国制造。\n\n有问题?请随时联系我们的客户服务团队,他们会解答您的所有问题。<<<<>>>>>product_name: 宠物自动喂食器\ndescription: 规格:\n尺寸:14'' x 9'' x 15''。\n\n为什么我们热爱它:\n我们的宠物自动喂食器可以定时定量投放食物,让您无论在家或外出都能确保宠物的饮食。\n\n材质与护理:\n可用湿布清洁。\n\n构造:\n由塑料和电子元件制成。\n\n其他特性:\n配备LCD屏幕,操作简单。\n可以设置多次投食。\n在美国制造。\n\n有问题?请随时联系我们的客户服务团队,他们会解答您的所有问题。<<<<>>>>>product_name: 玻璃保护膜\ndescription: 规格:\n适用于各种尺寸的手机屏幕。\n\n为什么我们热爱它:\n我们的玻璃保护膜可以有效防止手机屏幕刮伤和破裂,而且不影响触控的灵敏度。\n\n材质与护理:\n使用干布擦拭。\n\n构造:\n由高强度的玻璃材料制成。\n\n其他特性:\n安装简单,适合自行安装。\n在日本制造。\n\n有问题?请随时联系我们的客户服务团队,他们会解答您的所有问题。"
}
[llm/start] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain > 4:chain:LLMChain > 5:llm:ChatOpenAI] Entering LLM run with input:
{
"prompts": [
"System: Use the following pieces of context to answer the users question. \nIf you don't know the answer, just say that you don't know, don't try to make up an answer.\n----------------\nproduct_name: 高清电视机\ndescription: 规格:\n尺寸:50''。\n\n为什么我们热爱它:\n我们的高清电视机拥有出色的画质和强大的音效,带来沉浸式的观看体验。\n\n材质与护理:\n使用干布清洁。\n\n构造:\n由塑料、金属和电子元件制成。\n\n其他特性:\n支持网络连接,可以在线观看视频。\n配备遥控器。\n在韩国制造。\n\n有问题?请随时联系我们的客户服务团队,他们会解答您的所有问题。<<<<>>>>>product_name: 空气净化器\ndescription: 规格:\n尺寸:15'' x 15'' x 20''。\n\n为什么我们热爱它:\n我们的空气净化器采用了先进的HEPA过滤技术,能有效去除空气中的微粒和异味,为您提供清新的室内环境。\n\n材质与护理:\n清洁时使用干布擦拭。\n\n构造:\n由塑料和电子元件制成。\n\n其他特性:\n三档风速,附带定时功能。\n在德国制造。\n\n有问题?请随时联系我们的客户服务团队,他们会解答您的所有问题。<<<<>>>>>product_name: 宠物自动喂食器\ndescription: 规格:\n尺寸:14'' x 9'' x 15''。\n\n为什么我们热爱它:\n我们的宠物自动喂食器可以定时定量投放食物,让您无论在家或外出都能确保宠物的饮食。\n\n材质与护理:\n可用湿布清洁。\n\n构造:\n由塑料和电子元件制成。\n\n其他特性:\n配备LCD屏幕,操作简单。\n可以设置多次投食。\n在美国制造。\n\n有问题?请随时联系我们的客户服务团队,他们会解答您的所有问题。<<<<>>>>>product_name: 玻璃保护膜\ndescription: 规格:\n适用于各种尺寸的手机屏幕。\n\n为什么我们热爱它:\n我们的玻璃保护膜可以有效防止手机屏幕刮伤和破裂,而且不影响触控的灵敏度。\n\n材质与护理:\n使用干布擦拭。\n\n构造:\n由高强度的玻璃材料制成。\n\n其他特性:\n安装简单,适合自行安装。\n在日本制造。\n\n有问题?请随时联系我们的客户服务团队,他们会解答您的所有问题。\nHuman: 高清电视机怎么进行护理?"
]
}
[llm/end] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain > 4:chain:LLMChain > 5:llm:ChatOpenAI] [2.86s] Exiting LLM run with output:
{
"generations": [
[
{
"text": "高清电视机的护理非常简单。您只需要使用干布清洁即可。避免使用湿布或化学清洁剂,以免损坏电视机的表面。",
"generation_info": {
"finish_reason": "stop"
},
"message": {
"lc": 1,
"type": "constructor",
"id": [
"langchain",
"schema",
"messages",
"AIMessage"
],
"kwargs": {
"content": "高清电视机的护理非常简单。您只需要使用干布清洁即可。避免使用湿布或化学清洁剂,以免损坏电视机的表面。",
"additional_kwargs": {}
}
}
}
]
],
"llm_output": {
"token_usage": {
"prompt_tokens": 823,
"completion_tokens": 58,
"total_tokens": 881
},
"model_name": "gpt-3.5-turbo"
},
"run": null
}
[chain/end] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain > 4:chain:LLMChain] [2.86s] Exiting Chain run with output:
{
"text": "高清电视机的护理非常简单。您只需要使用干布清洁即可。避免使用湿布或化学清洁剂,以免损坏电视机的表面。"
}
[chain/end] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain] [2.87s] Exiting Chain run with output:
{
"output_text": "高清电视机的护理非常简单。您只需要使用干布清洁即可。避免使用湿布或化学清洁剂,以免损坏电视机的表面。"
}
[chain/end] [1:chain:RetrievalQA] [3.26s] Exiting Chain run with output:
{
"result": "高清电视机的护理非常简单。您只需要使用干布清洁即可。避免使用湿布或化学清洁剂,以免损坏电视机的表面。"
}
'高清电视机的护理非常简单。您只需要使用干布清洁即可。避免使用湿布或化学清洁剂,以免损坏电视机的表面。'
"""我们正在使用 stuff 方法,现在我们正在传递这个上下文,可以看到,这个上下文是由我们检索到的不同文档创建的
通过LLM进行评估实例
-
首先,我们使用 LLM 自动构建了问答测试集,包含问题及标准答案。
-
然后,同一 LLM 试图回答测试集中的所有问题,得到响应。
-
下一步,需要评估语言模型的回答是否正确。这里奇妙的是,我们再使用另一个 LLM 链进行判断,所以 LLM 既是“球员”,又是“裁判”。
langchain.debug = False
#为所有不同的示例创建预测
predictions = qa.apply(examples)
# 对预测的结果进行评估,导入QA问题回答,评估链,通过语言模型创建此链
from langchain.evaluation.qa import QAEvalChain #导入QA问题回答,评估链
#通过调用chatGPT进行评估
llm = ChatOpenAI(temperature=0)
eval_chain = QAEvalChain.from_llm(llm)
#在此链上调用evaluate,进行评估
graded_outputs = eval_chain.evaluate(examples, predictions)
#我们将传入示例和预测,得到一堆分级输出,循环遍历它们打印答案
for i, eg in enumerate(examples):
print(f"Example {i}:")
print("Question: " + predictions[i]['query'])
print("Real Answer: " + predictions[i]['answer'])
print("Predicted Answer: " + predictions[i]['result'])
print("Predicted Grade: " + graded_outputs[i]['results'])
print()
"""
Example 0:
Question: 高清电视机怎么进行护理?
Real Answer: 使用干布清洁。
Predicted Answer: 高清电视机的护理非常简单。您只需要使用干布清洁即可。避免使用湿布或化学清洁剂,以免损坏电视机的表面。
Predicted Grade: CORRECT
Example 1:
Question: 旅行背包有内外袋吗?
Real Answer: 有。
Predicted Answer: 是的,旅行背包有多个实用的内外袋,可以轻松装下您的必需品。
Predicted Grade: CORRECT
Example 2:
Question: 这款全自动咖啡机的尺寸是多少?
Real Answer: 大型尺寸为13.8'' x 17.3'',中型尺寸为11.5'' x 15.2''。
Predicted Answer: 这款全自动咖啡机有两种尺寸可选:
- 大型尺寸为13.8'' x 17.3''。
- 中型尺寸为11.5'' x 15.2''。
Predicted Grade: CORRECT
Example 3:
Question: 这款电动牙刷的规格是什么?
Real Answer: 一般大小 - 高度:9.5'',宽度:1''。
Predicted Answer: 这款电动牙刷的规格是:高度为9.5英寸,宽度为1英寸。
Predicted Grade: CORRECT
Example 4:
Question: 这种产品的名称是什么?
Real Answer: 这种产品的名称是橙味维生素C泡腾片。
Predicted Answer: 这种产品的名称是儿童益智玩具。
Predicted Grade: INCORRECT
Example 5:
Question: 这款无线蓝牙耳机的尺寸是多少?
Real Answer: 该无线蓝牙耳机的尺寸为1.5'' x 1.3''。
Predicted Answer: 这款无线蓝牙耳机的尺寸是1.5'' x 1.3''。
Predicted Grade: CORRECT
Example 6:
Question: 这款瑜伽垫的尺寸是多少?
Real Answer: 这款瑜伽垫的尺寸是24'' x 68''。
Predicted Answer: 这款瑜伽垫的尺寸是24'' x 68''。
Predicted Grade: CORRECT
"""Real Answer是有先前的QAGenerateChain创建的问答测试集中的答案,而Predicted Answer则是由我们的qa链给出的答案,最后的Predicted Grade则是由上面代码中的QAEvalChain回答的
代理
使用LangChain内置工具llm-math和wikipedia
要使用代理 (Agents) ,我们需要三样东西:
- 一个基本的 LLM
- 我们将要进行交互的工具 Tools
- 一个控制交互的代理 (Agents) 。
from langchain.agents import load_tools, initialize_agent
from langchain.agents import AgentType
from langchain.python import PythonREPL
from langchain.chat_models import ChatOpenAI
# 参数temperature设置为0.0,从而减少生成答案的随机性。
llm = ChatOpenAI(temperature=0)
tools = load_tools(
["llm-math","wikipedia"],
llm=llm #第一步初始化的模型
)
# 初始化代理
agent= initialize_agent(
tools, #第二步加载的工具
llm, #第一步初始化的模型
agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, #代理类型
handle_parsing_errors=True, #处理解析错误
verbose = True #输出中间步骤
)
llm-math工具结合语言模型和计算器用以进行数学计算wikipedia工具通过API连接到wikipedia进行搜索查询。agent: 代理类型。这里使用的是AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION。其中CHAT代表代理模型为针对对话优化的模型;Zero-shot意味着代理 (Agents) 仅在当前操作上起作用,即它没有记忆;REACT代表针对REACT设计的提示模版。DESCRIPTION根据工具的描述 description 来决定使用哪个工具。(我们不会在本章中讨论 * REACT 框架 ,但您可以将其视为 LLM 可以循环进行 Reasoning 和 Action 步骤的过程。它启用了一个多步骤的过程来识别答案。)handle_parsing_errors: 是否处理解析错误。当发生解析错误时,将错误信息返回给大模型,让其进行纠正。verbose: 是否输出中间步骤结果。
agent("计算300的25%")
"""
> Entering new AgentExecutor chain...
Question: 计算300的25%
Thought: I can use the calculator tool to calculate 25% of 300.
Action:
```json
{
"action": "Calculator",
"action_input": "300 * 0.25"
}
```
Observation: Answer: 75.0
Thought:The calculator tool returned the answer 75.0, which is 25% of 300.
Final Answer: 25% of 300 is 75.0.
> Finished chain.
{'input': '计算300的25%', 'output': '25% of 300 is 75.0.'}
"""上面的过程可以总结为下
-
模型对于接下来需要做什么,给出思考
思考:我可以使用计算工具来计算300的25%
-
模型基于思考采取行动
行动: 使用计算器(calculator),输入(action_input)300*0.25
-
模型得到观察
观察:答案: 75.0
-
基于观察,模型对于接下来需要做什么,给出思考
思考: 计算工具返回了300的25%,答案为75
-
给出最终答案(Final Answer)
最终答案: 300的25%等于75。
-
以字典的形式给出最终答案。
使用LangChain内置工具PythonREPLTool
让agent可以调用python的库
from langchain.agents.agent_toolkits import create_python_agent
from langchain.tools.python.tool import PythonREPLTool
agent = create_python_agent(
llm, #使用前面一节已经加载的大语言模型
tool=PythonREPLTool(), #使用Python交互式环境工具 REPLTool
verbose=True #输出中间步骤
)
customer_list = ["小明","小黄","小红","小蓝","小橘","小绿",]
agent.run(f"将使用pinyin拼音库这些客户名字转换为拼音,并打印输出列表: {customer_list}。")
"""
> Entering new AgentExecutor chain...
Python REPL can execute arbitrary code. Use with caution.
I need to use the pinyin library to convert the names to pinyin. I can then print out the list of converted names.
Action: Python_REPL
Action Input: import pinyin
Observation:
Thought:I have imported the pinyin library. Now I can use it to convert the names to pinyin.
Action: Python_REPL
Action Input: names = ['小明', '小黄', '小红', '小蓝', '小橘', '小绿']
pinyin_names = [pinyin.get(i, format='strip') for i in names]
print(pinyin_names)
Observation: ['xiaoming', 'xiaohuang', 'xiaohong', 'xiaolan', 'xiaoju', 'xiaolv']
Thought:I have successfully converted the names to pinyin and printed out the list of converted names.
Final Answer: ['xiaoming', 'xiaohuang', 'xiaohong', 'xiaolan', 'xiaoju', 'xiaolv']
> Finished chain.
"['xiaoming', 'xiaohuang', 'xiaohong', 'xiaolan', 'xiaoju', 'xiaolv']"
"""定义自己的工具并在代理中使用
LangChian tool 函数装饰器可以应用用于任何函数,将函数转化为LangChain 工具,使其成为代理可调用的工具。我们需要给函数加上非常详细的文档字符串, 使得代理知道在什么情况下、如何使用该函数/工具。
# 导入tool函数装饰器
from langchain.agents import tool
from datetime import date
@tool
def time(text: str) -> str:
"""
返回今天的日期,用于任何需要知道今天日期的问题。\
输入应该总是一个空字符串,\
这个函数将总是返回今天的日期,任何日期计算应该在这个函数之外进行。
"""
return str(date.today())
# 初始化代理
agent= initialize_agent(
tools=[time], #将刚刚创建的时间工具加入代理
llm=llm, #初始化的模型
agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, #代理类型
handle_parsing_errors=True, #处理解析错误
verbose = True #输出中间步骤
)
# 使用代理询问今天的日期.
# 注: 代理有时候可能会出错(该功能正在开发中)。如果出现错误,请尝试再次运行它。
agent("今天的日期是?")
"""
> Entering new AgentExecutor chain...
根据提供的工具,我们可以使用`time`函数来获取今天的日期。
Thought: 使用`time`函数来获取今天的日期。
Action:
```
{
"action": "time",
"action_input": ""
}
```
Observation: 2023-08-09
Thought:我现在知道了最终答案。
Final Answer: 今天的日期是2023-08-09。
> Finished chain.
{'input': '今天的日期是?', 'output': '今天的日期是2023-08-09。'}
"""














 198
198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









