






MLCA-AVSR
基于多层交叉注意融合的视听语音识别
ABSTRACT
目标任务现状、目前研究现状(研究大方向、研究的欠缺)、本文方法、方法效果(排名、分数)
有一个Index Terms
INTRODUCTION
目标任务的简单发展历程与发展现状,目前任务的难点,指出为什么会有这样的想法
针对任务的难点,列出不同论文的相似方法,按段划分
介绍自己的模型架构与方法,说明自己方法的创新性、可靠性、重要性、实验结果
Method
Previous
画了一张改进前的方法的框架图
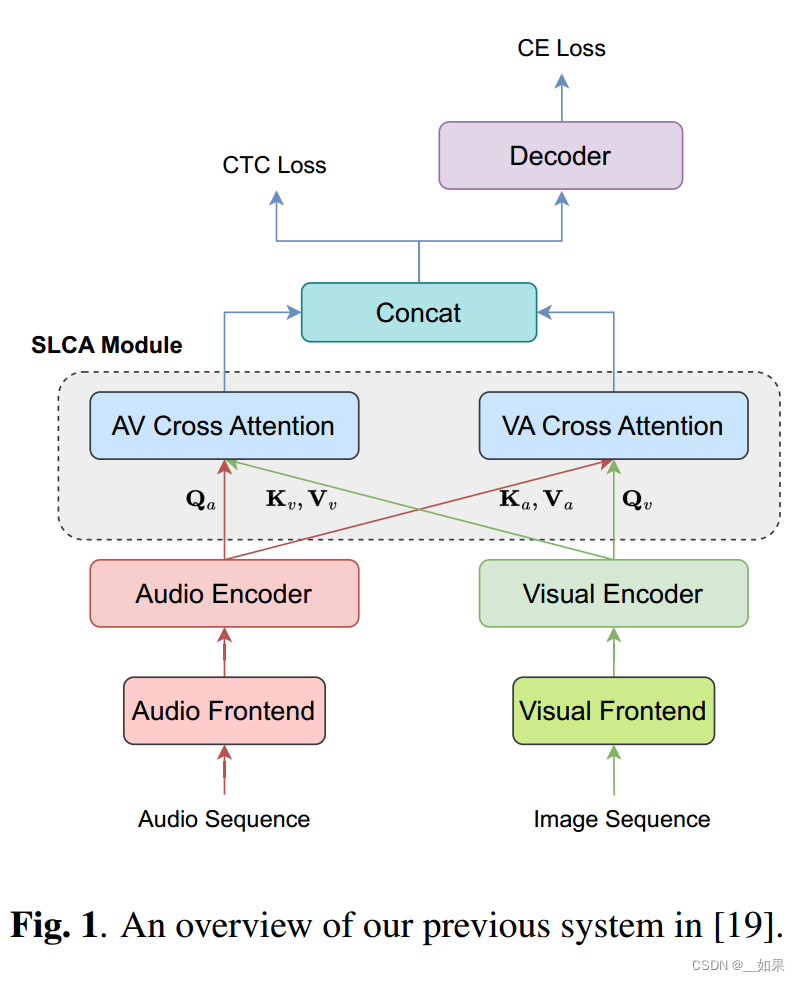
详细介绍每个模块的输入输出及其作用
还放了个公式
Improved Cross Attention
画了个改进后的、本文的核心方法框架
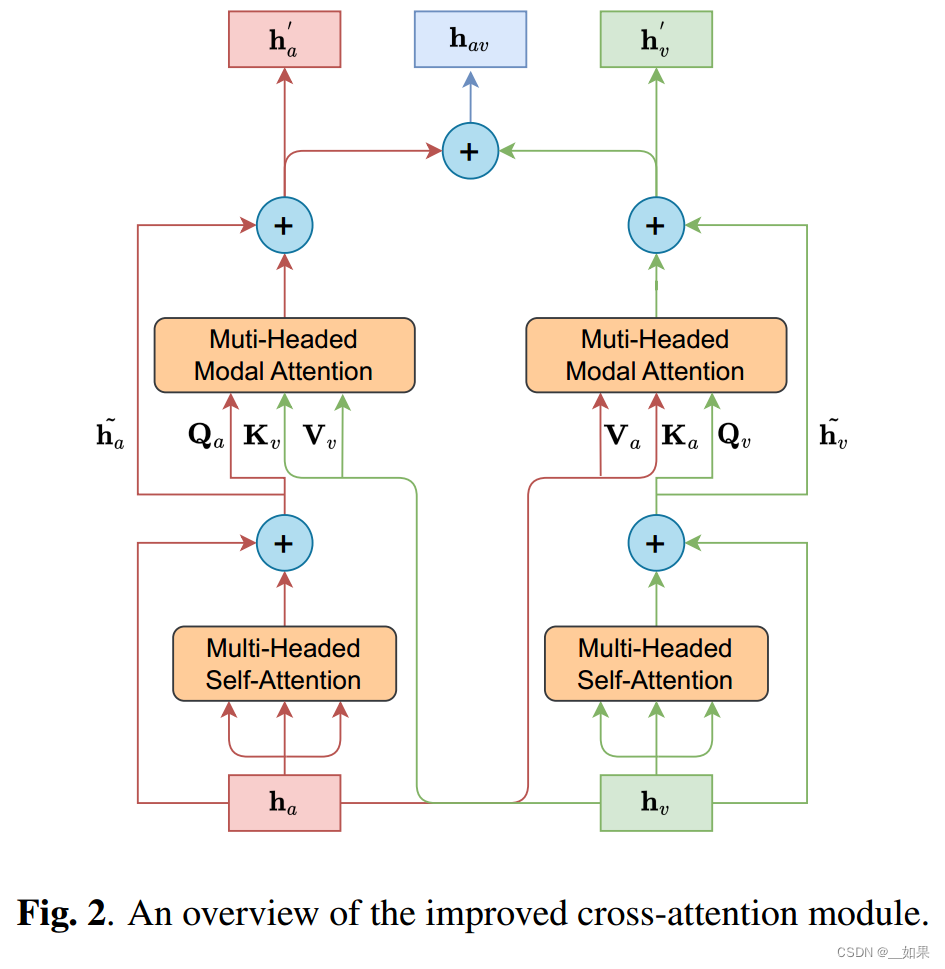
详细介绍每个模块的输入输出及其作用,每个模块中与之前模型的区别
放了个公式

Multi-Layer Cross Attention Fusion
画了总体模型框架

之前介绍过的一笔带过,没介绍过的介绍一下用了啥
介绍整体架构的优越性与模块间连接的效果与作用,介绍模型整体的流程,从输入到输出+损失之类的
EXPERIMENT
Data Processing
介绍Dataset
介绍音频的数据预处理
介绍视频的数据预处理
Setup
各种超参:层的维度、dropout等
Results and Analysis
单一模态对比
与常用融合方法对比
消融实验
与数据集上其他SOTA模型对比
CONCLUSION
本文提出了什么方法,核心方法作用,模型在数据集上的效果
TALKNCE
ABSTRACT
目标任务的介绍,以前的工作的侧重点,本文提出的方法及其作用,方法的效果
有Index Terms
INTRODUCTION
目标任务的产生背景,任务的难点
一般的模型架构及其缺陷
本文方法的关注点、优越性及其效果
贡献总结
METHOD
Preliminaries
介绍之前广泛使用的技术框架并画了个图

还介绍了一些在该任务上往其他方向的研究
Contrastive Learning with TalkNCE Loss
介绍原技术架构中,本文技术方案更新的地方,并列了个式子
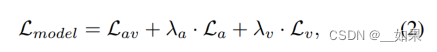
用公式解释技术方案
EXPERIMENTS
介绍数据集
介绍超参和评价指标
新方法在数据集上的表现
消融实验
CONCLUSION
提出了什么方法,解决了什么问题,有何优势,效果如何
NEURAL SPEAKER DIARIZATION USING MEMORY-AWARE MULTI-SPEAKER
EMBEDDING WITH SEQUENCE-TO-SEQUENCE ARCHITECTURE
ABSTRACT
本文提出的方法、它的优点、效果对比、代码仓库
有一个Index Terms
INTRODUCTION
介绍目标任务是什么、目前面对的挑战
传统方法及其缺陷
其他人的改进方法及其缺陷
本方法是为了解决什么问题、用了什么架构与模型、效果怎么样
METHODS
画了个本文方法总览图
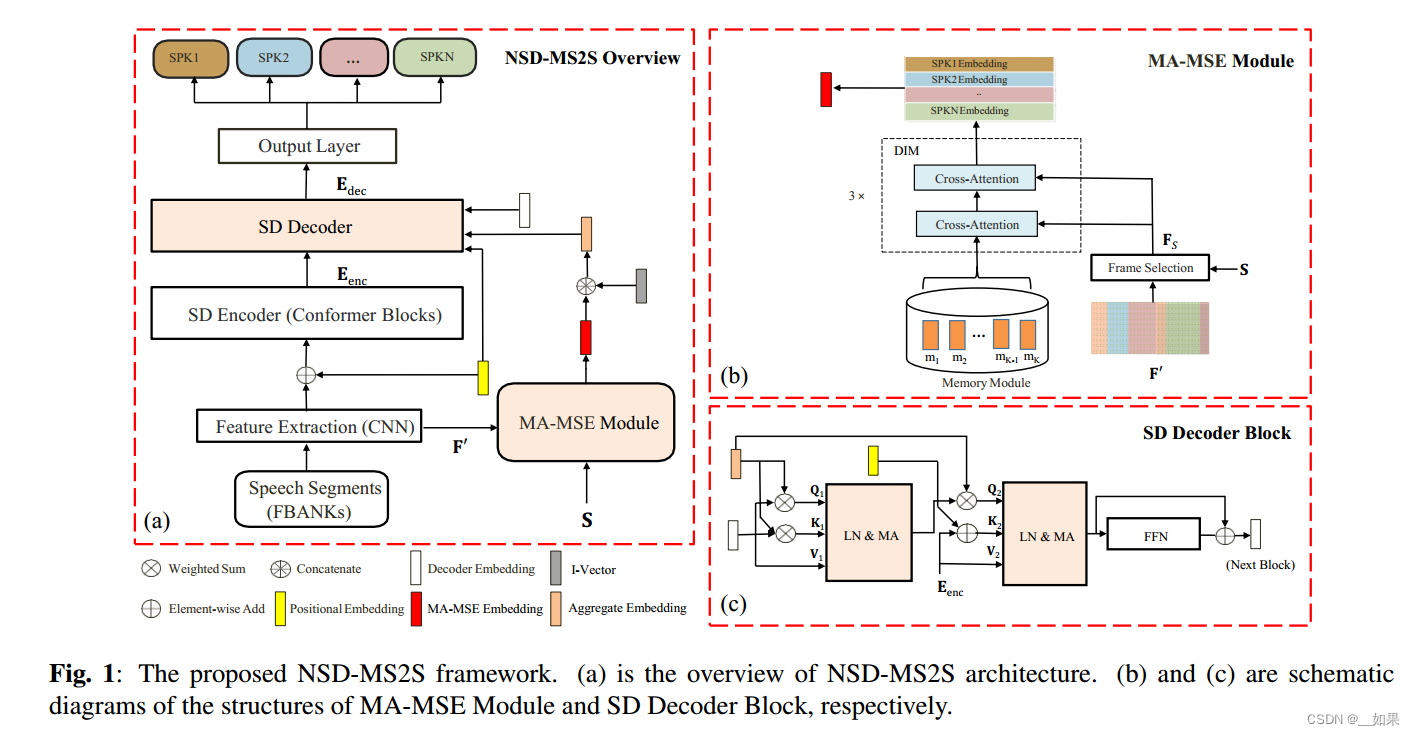
Overview of Network
用公式和字符说明输入输出维度和组件间连接方式
Speaker Detection Decoder
这个模块收到哪篇文章的启发、模块的详细细节(用字符+公式说明)
MA-MSE with Deep Interactive Module
模块的细节与核心想法(用字符+公式说明)
Loss Fuction
谁和谁做loss,公式
EXPERIMENT
CHiME-7 DASR Challenge
对这个数据集的介绍
Implementation Details
实现细节:维度、超参
Results and Analysis
和其他模型对比的实验如何控制变量之类的
对比的效果
消融实验
CONCLUSIONS
本文提出的方法及其应用场景
方法效果和影响
ONLINE SPEAKER DIARIZATION OF MEETINGS GUIDED BY SPEECH SEPARATION
ABSTRACT
指出本文方法解决的问题、最近的其他工作为什么不行、本文核心方法简介
方法效果
Index Terms
INTRODUCTION
任务介绍
传统方法及其缺陷
本文基于的方法介绍
本方法基于上面的方法的改进和效果
RELATED WORK
其他工作
PROPOSED SYSTEM
介绍按模块总体架构,列式子,画图
EXPERIMENTAL SETUP
Dataset
介绍数据集,怎么样使用该数据集
Architecture configuration and training details
模型架构与超参
RESULTS
评分标准
消融实验
各方面性能对比
在任务的不同方面的效果
CONCLUSIONS
本文提出的方法、解决了什么问题















 9337
9337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









