






目录
前言
两种 Finetune 范式
增量预训练微调
使用场景:让基座模型学习到一些新知识,如某个垂类领域的常识 训练数据:文章、书籍、代码等
指令跟随微调
使用场景:让模型学会对话模板,根据人类指令进行对话 训练数据:高质量的对话、问答数据
不同数据集下使用微调
-
数据集1 - 数据量少,但数据相似度非常高在这种情况下,我们所做的只是修改最后几层或最终的softmax图层的输出类别。
-
数据集2 - 数据量少,数据相似度低在这种情况下,我们可以冻结预训练模型的初始层(比如k层),并再次训练剩余的(n-k)层。由于新数据集的相似度较低,因此根据新数据集对较高层进行重新训练具有重要意义。
-
数据集3 - 数据量大,数据相似度低在这种情况下,由于我们有一个大的数据集,我们的神经网络训练将会很有效。但是,由于我们的数据与用于训练我们的预训练模型的数据相比有很大不同。使用预训练模型进行的预测不会有效。因此,最好根据你的数据从头开始训练神经网络(Training from scatch)。
-
数据集4 - 数据量大,数据相似度高这是理想情况。在这种情况下,预训练模型应该是最有效的。使用模型的最好方法是保留模型的体系结构和模型的初始权重。然后,我们可以使用在预先训练的模型中的权重来重新训练该模型。
微调指导事项
使用较小的学习率来训练网络。由于我们预计预先训练的权重相对于随机初始化的权重已经相当不错,我们不想过快地扭曲它们太多。通常的做法是使初始学习率比用于从头开始训练(Training from scratch)的初始学习率小10倍。
其他方案
Adapt Tuning
每个 Adapter 模块由两个前馈子层组成,第一个前馈子层将 Transformer 块的输出作为输入,将原始输入维度 d 投影到 m,通过控制 m 的大小来限制 Adapter 模块的参数量,通常情况下 m << d。在输出阶段,通过第二个前馈子层还原输入维度,将 m 重新投影到 d,作为 Adapter 模块的输出
Prefix Tuning
在每一个输入 token 前构造一段与下游任务相关的 virtual tokens 作为 prefix,在微调时只更新 prefix 部分的参数,而其他参数冻结不变
模型可用序列长度减少。由于加入了 virtual tokens,占用了可用序列长度,因此越高的微调质量,模型可用序列长度就越低。
LoRa
思想
大模型是将数据映射到高维空间进行处理,对下游子任务可能只需要在某个子空间范围内就可以解决。这个子空间参数矩阵的秩就可以称为对应当前待解决问题的本征秩(intrinsic rank)
我们可以通过优化密集层在适应过程中变化的秩分解矩阵来间接训练神经网络中的一些密集层,从而实现仅优化密集层的秩分解矩阵来达到微调效果
原理
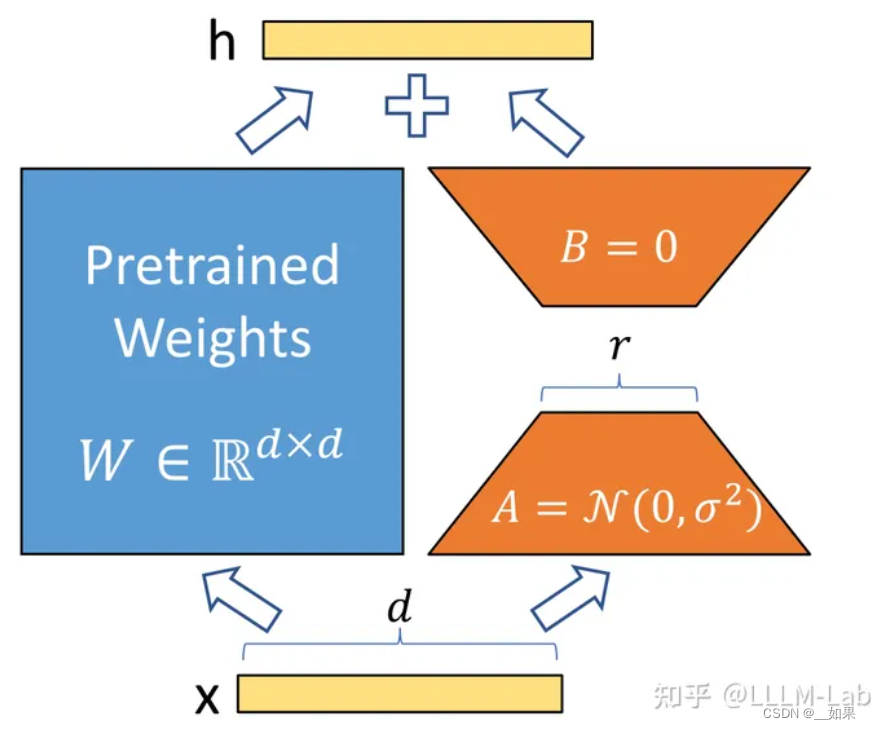
使用低秩分解来表示预训练的权重参数矩阵更新
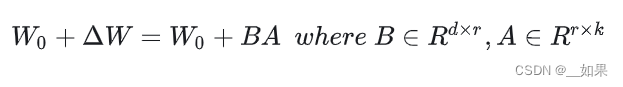
在训练过程中,W0冻结不更新,A、B 包含可训练参数
在开始训练时,对 A 使用随机高斯初始化,对 B 使用零初始化,然后使用 Adam 进行优化
在 Transformer 结构中,LoRA 技术主要应用在注意力模块的四个权重矩阵: 𝑊𝑞 、 𝑊𝑘 、 𝑊𝑣 、 𝑊0 ,而冻结 MLP 的权重矩阵
通过消融实验发现同时调整 𝑊𝑞 和 𝑊𝑣 会产生最佳结果
在上述条件下,可训练参数个数为:
Θ=2×𝐿𝐿𝑜𝑅𝐴×𝑑𝑚𝑜𝑑𝑒𝑙×𝑟
其中, 𝐿𝐿𝑜𝑅𝐴 为应用 LoRA 的权重矩阵的个数, 𝑑𝑚𝑜𝑑𝑒𝑙 为 Transformer 的输入输出维度,r 为设定的 LoRA 秩。
一般情况下,r 取到 4、8、16。
代码
LoRA 层在具体实现上,是定义了一个基于 Lora 基类的 Linear 类,该类同时继承了 nn.Linear 和 LoraLayer
class LoraLayer:
def __init__(
self,
r: int, # LoRA 的秩
lora_alpha: int, # 归一化参数
lora_dropout: float, # LoRA 层的 dropout 比例
merge_weights: bool, # eval 模式中,是否将 LoRA 矩阵的值加到原权重矩阵上
):
self.r = r
self.lora_alpha = lora_alpha
# Optional dropout
if lora_dropout > 0.0:
self.lora_dropout = nn.Dropout(p=lora_dropout)
else:
self.lora_dropout = lambda x: x
# Mark the weight as unmerged
self.merged = False
self.merge_weights = merge_weights
self.disable_adapters = Falseclass Linear(nn.Linear, LoraLayer):
# LoRA 层
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.0,
fan_in_fan_out: bool = False,
merge_weights: bool = True,
**kwargs,
):
# 继承两个基类的构造函数
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoraLayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=merge_weights)
self.fan_in_fan_out = fan_in_fan_out
# Actual trainable parameters
if r > 0:
# 参数矩阵 A
self.lora_A = nn.Linear(in_features, r, bias=False)
# 参数矩阵 B
self.lora_B = nn.Linear(r, out_features, bias=False)
# 归一化系数
self.scaling = self.lora_alpha / self.r
# 冻结原参数,仅更新 A 和 B
self.weight.requires_grad = False
# 初始化 A 和 B
self.reset_parameters()
if fan_in_fan_out:
self.weight.data = self.weight.data.Tdef forward(self, x: torch.Tensor):
if self.disable_adapters:
if self.r > 0 and self.merged:
self.weight.data -= (
transpose(self.lora_B.weight @ self.lora_A.weight, self.fan_in_fan_out) * self.scaling
)
self.merged = False
return F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)
'''主要分支'''
elif self.r > 0 and not self.merged:
result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)
if self.r > 0:
result += self.lora_B(self.lora_A(self.lora_dropout(x))) * self.scaling
return result
else:
return F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)对应于这个式子
peft
peft 库目前支持调用 LoRA 的层包括:nn.Linear、nn.Embedding、nn.Conv2d 三种
import torch.nn as nn
from transformers import AutoTokenizer, AutoModel
from peft import get_peft_model, LoraConfig, TaskType, PeftModel
from transformers import Trainer
# 加载底座模型
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
model = AutoModel.from_pretrained(
MODEL_PATH, load_in_8bit=False, trust_remote_code=True, device_map="auto"
)
# 对底座模型做一些设置
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
model.is_parallelizable = True
model.model_parallel = True
model.config.use_cache = (
False # silence the warnings. Please re-enable for inference!
)
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1,
)task_type 是模型的任务类型,大模型一般都是 CAUSAL_LM 即传统语言模型。
inference_mode 在 LoraConfig 中用于指示模型当前配置的模式。设置为 False 表示训练模式,适配器权重保持分离,以便更新。设置为 True 表示推理模式,适配器权重与主权重合并,以提高推理效率
model = get_peft_model(model, peft_config)
trainer = Trainer(
model=model,
train_dataset=dataset,
args=training_args,
data_collator=lambda x : data_collator_glm(x, tokenizer),
)
trainer.train()使用 transformers 提供的 Trainer 进行训练即可
例如,若要使用 Trainer 类进行训练,请设置具有一些训练超参数的 TrainingArguments 类
training_args = TrainingArguments(
output_dir="your-name/bigscience/mt0-large-lora",
learning_rate=1e-3,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
num_train_epochs=2,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
)














 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









