



相信各个公司以及科研工作者都有很多自己的AI算法,但是却很零散,需要调用的时候要到各个项目底下进行查找和运行代码,且对外服务特别不方便。这篇文章运用triton,将所有模型通过模型转换和服务端部署,轻松在client端无脑进行图像、视频的识别。
一、windows系统安装docker
注意:docker支持的windows版本:Windows 10/11 64位:专业版、企业版或教育版(Build 19041或更高版本) 。所以需要先对windows系统进行升级。在升级之前最好把C盘中的内容备份一下,以免丢失。
可以下载微软提供的windows11安装工具进行系统更新:下载 Windows 11
1.从docker官网下载docker程序访问 Docker 官网下载 Docker Desktop Installer.exe
2.点击docker进行安装,直接下一步即可
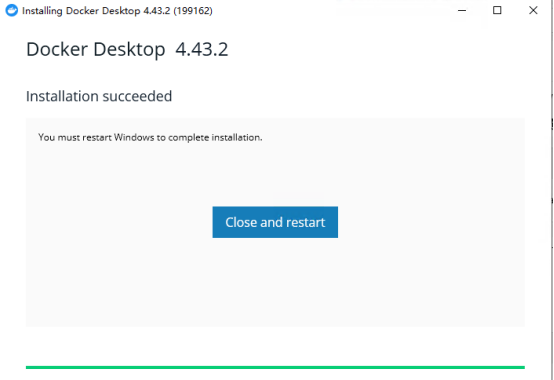
3.在终端打开,输入命令行docker --version,出现以下界面即为安装成功

打开docker之后出现
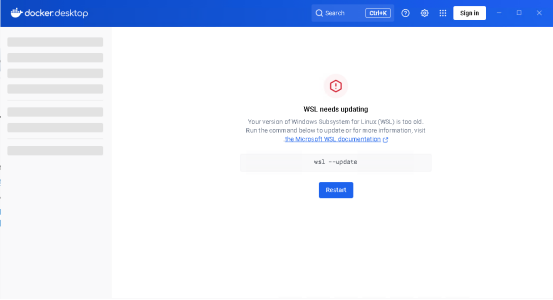
解决:
- 以管理员身份打开命令提示符:点击 “开始” 菜单,搜索 “cmd”,右键单击 “命令提示符”,选择 “以管理员身份运行”。
- 执行更新命令:在命令提示符窗口中,输入 wsl --update 并回车。系统会自动下载并安装 WSL 的更新。
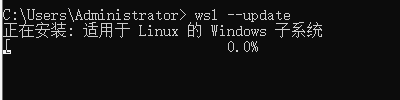
- 重启电脑:更新完成后,关闭命令提示符窗口,重启计算机,让更新生效。
- 重新打开 Docker Desktop:电脑重启后,再次打开 Docker Desktop,查看是否还会出现该提示。
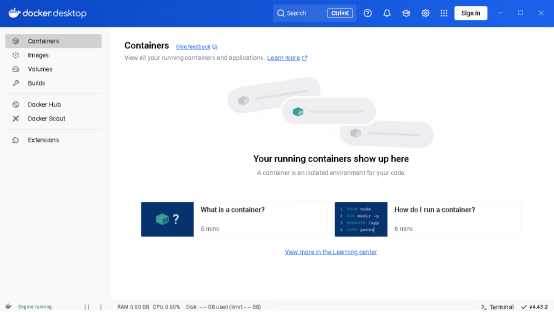
二、搭建tritonserver
拉镜像:在终端运行
docker pull nvcr.io/nvidia/tritonserver:24.06-py3 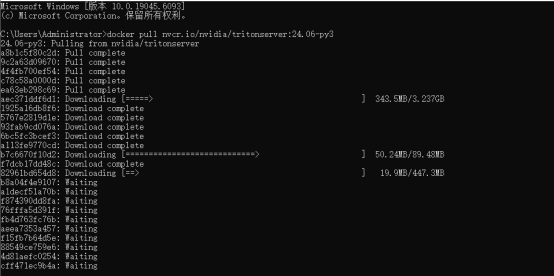
这里我选择的是24.06版本的镜像,是比较新的可以直接支持onnx推理调用的版本,也可以根据自己的需求进行选择。需要说明的是最好有gpu 如果没有需要拉cpu版本的triton
验证镜像拉取成功
![]()
创建服务端容器:
docker run -it --name tritonserver --gpus all -p 8000:8000 -p 8001:8001 -p 8002:8002 -v D:\triton\server:/models -e CUDA_MODULE_LOADING=LAZY --net host nvcr.io/nvidia/tritonserver:24.06-py3说明一下参数的作用
docker run:运行
-it:进入容器内部进行操作
--name:容器的名称
--gpus:在容器内可使用电脑上的gpu,all为可以使用全部
-p:端口映射。triton中有三个映射端口,其中8000为http端口、8001为grpc端口、8002为本地使用端口,将三个端口分别映射到了电脑的对应端口
-v:路径映射,这里需要将模型路径映射到docker容器中才可以将模型拉起。
后面的nvcr.io/nvidia/tritonserver:24.06-py3为镜像的名称和版本号。
-e:启动启用 CUDA 延迟加载
一般docker进行triton服务部署用这些参数可以覆盖所需功能。
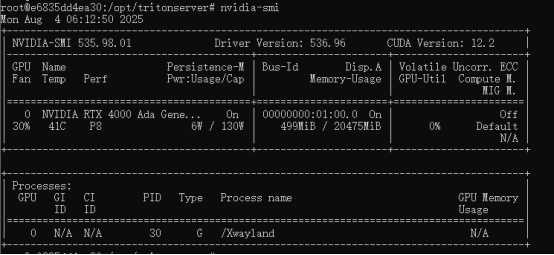
创建好之后在容器内输入命令行:nvidia-smi
显示下图则表示容器内可正常使用gpu
接着规范存放模型文件,按照下图格式进行存放,其中resnet50为文件名,也是模型的名字,其他名称不能修改。
.\triton-models/
└── resnet50/
├── 1/
│ └── model.onnx
└── config.pbtxt
我其中一个配置文件的内容供参考
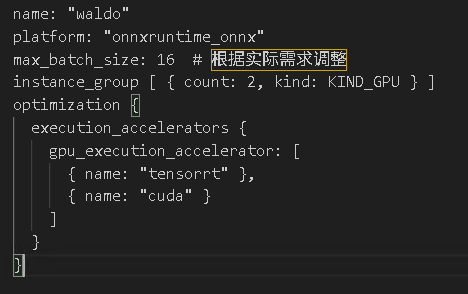
解析一下各个参数含义,以便大家自行修改
1. name: "waldo"
含义:定义模型的名称,Triton 会通过此名称识别模型(如客户端请求时需指定 model_name=waldo)。
作用:区分不同模型,确保请求能路由到正确模型。
2. platform: "onnxruntime_onnx"
含义:指定模型的推理后端(平台类型),这里表示使用 ONNX Runtime 后端加载和运行 ONNX 模型。
作用:Triton 根据此参数调用对应的推理引擎(如 ONNX Runtime、TensorRT、PyTorch 等),需确保 Triton 已安装对应后端。
3. max_batch_size: 16
含义:设置模型支持的最大批量推理大小,即一次推理请求最多可包含 16 个样本(如 16 张图片、16 条数据)。
作用:
控制内存占用(批量越大,内存需求越高)。
优化吞吐量(合理批量可提升 GPU 利用率)。
注意:需与模型实际能力匹配(若模型不支持批量推理,需设为 0 或调整代码)。
4. instance_group [ { count: 2, kind: KIND_GPU } ]
count: 2:
含义:为模型创建 2 个推理实例(Instance),每个实例独立占用 GPU 资源并行处理请求。
作用:增加并行能力,提升吞吐量(实例数越多,同时处理的请求数越多,但受 GPU 显存 / 算力限制)。
kind: KIND_GPU:
含义:指定实例运行在 GPU 上(若为 KIND_CPU 则运行在 CPU)。
作用:利用 GPU 加速推理,需确保模型和后端支持 GPU 推理。
5.加速策略:execution_accelerators → 用 TensorRT 和 CUDA 优化推理性能。
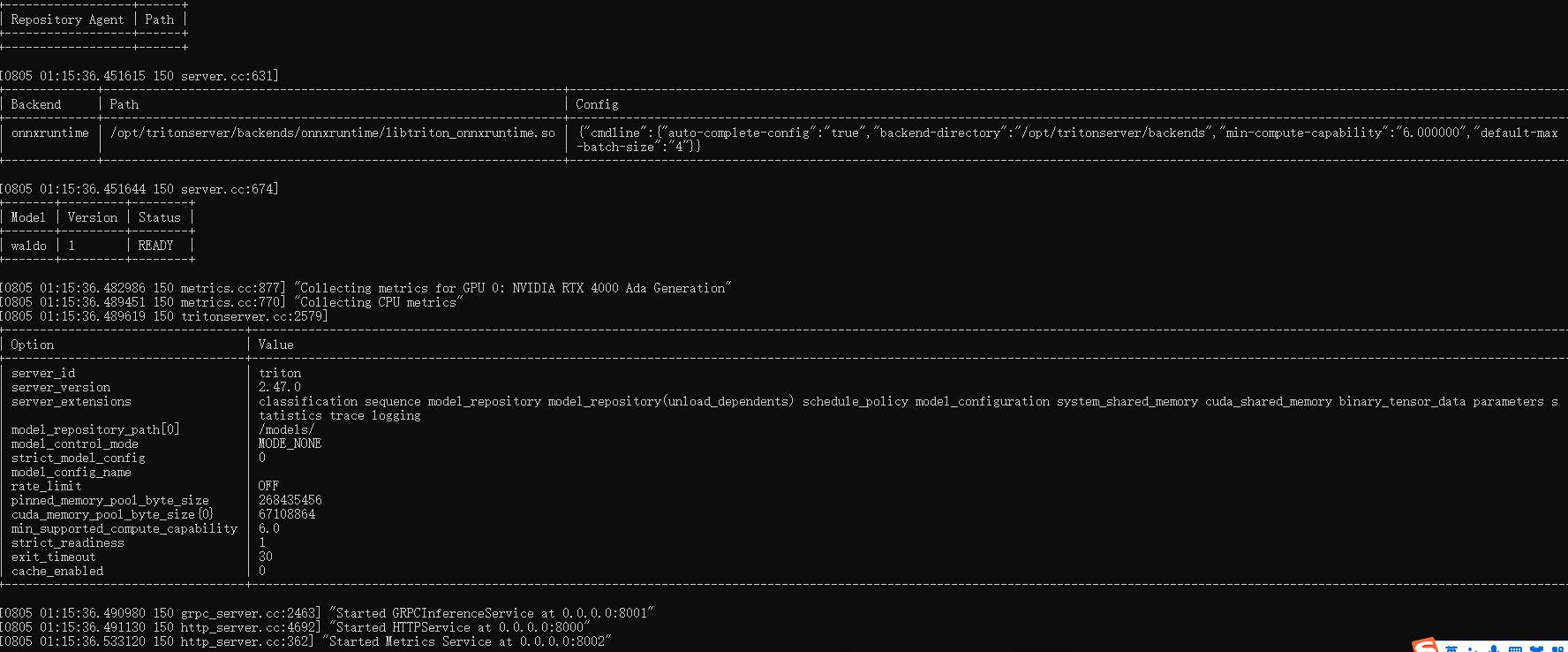
在docker容器终端运行tritonserver --model-repository=/models/,出现以下界面即为模型启动成功,就可以在client端进行调用了
三、搭建tritonclient
搭建客户端可以在此环境下进行模型推理调用
首先拉取和server端版本对应的docker镜像
docker pull nvcr.io/nvidia/tritonserver:24.06-py3-sdk然后搭建docker容器
docker run -it --name tritonclient --gpus all --net host -v D:\triton\clients:/clients nvcr.io/nvidia/tritonserver:24.06-py3-sdk在上述clients文件夹下面编写调用代码:
onnx调用方法用http和端口直接调用即可
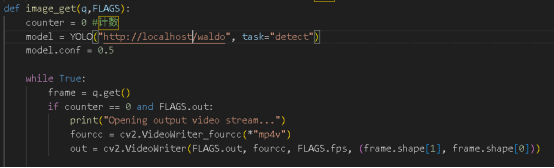
在tritonclient终端运行python代码即可进行模型推理啦。私有化部署可小企鹅寻求帮助(1901935655)

















 3708
3708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









