






根据训练数据有无标记(label)信息可以分为:无监督学习、监督学习
监督学习流程:

1.线性回归:以房屋定价问题为例
一元线性回归模型:,房屋售价y只考虑房屋面积
一个变量,
是根据已有数据拟合出来的函数
二元线性回归模型:,有两个变量(楼层、面积)
多元线性回归模型:,待解决的问题有n个变量
模型预测结果正确性评价:误差

损失函数计算等同于m次预测的结果和真实的结果之间的差的平方和。线性回归的目的是寻找最佳,使损失函数
最小。
寻找最优的方法:梯度下降法。该方法计算损失函数在当前点的梯度,然后沿负梯度方向(即损失函数值下降最快的方向)调整参数,通过多次迭代就可以找到
值最小的参数。
具体过程:首先给定初始参数向量,如随机向量;计算损失函数对
的偏导(即梯度),然后沿负梯度方向按照一定的步长(学习率)
调整参数的值,并进行迭代,使更新后的
不断变小,直到找到使
最小的
值。
2.感知机:只有一个神经元的单层神经网络


该感知机可以完成对输入样本的分类。该感知机模型的形式化表示为:
感知机模型训练目的是找到超平面,将线性可分的数据集中所有样本点正确的分为两类。超平面是N维线性空间中维度为N-1的子空间。二维空间超平面是一条直线,三维空间的超平面是一个二维平面。
超平面要将两类点区分开来,因此损失函数定义为误分类的点到超平面的总距离。


3.两层神经网络——多层感知机
下图的多层感知机由一组输入、一个隐层和一个输出层组成。


4.深度学习——深层神经网络
深层神经网络的隐层可以超过一层。

5.神经网络训练
神经网络的训练是通过调整隐层和输出层的参数,使得神经网络计算出来的结果与真实结果y尽量接近。神经网络的训练包括正向传播和反向传播两个过程。

正向传播:基于训练好的神经网络模型,输入目标通过权重、偏执和激活函数计算出隐层,隐层通过下一级的权重、偏执和激活函数得到下一个隐层,经过逐层迭代,将输入的特征向量从低级特征逐步提取为抽象特征,最终输出目标分类结果。



反向传播:根据正向传播结果和真实值计算出损失函数L(w),然后采用梯度下降法,通过链式法则计算出损失函数对每个权重和偏置的偏导,即权重或偏置对损失的影响,最后更新权重和偏置。


6.网络拓扑结构
给定训练样本后,神经网络的输入和输出层的节点就确定了,但隐层神经元的个数及隐层的层数是可以调整的。隐层是用来提取输入特征中的隐藏规律的。隐层的数量、神经元节点的数量应该和真正隐藏的规律数量相当,但隐藏的规律是很难描述清楚的。
泛化:机器学习不仅要求模型在训练集上误差较小,在测试集上也要表现好
AutoML(自动机器学习):直接用机器自动化调节神经网络的超参数
7.激活函数
由于基于反向传播的神经网络训练算法使用梯度下降法来做优化训练,所以激活函数必须是可微的。激活函数的输出决定了下一层神经网络的输入。如果激活函数的输出范围是有限的,特征表示受到有限权重的影响会更显著,基于梯度的优化方法就会更稳定;如果激活函数的输出范围是无限的,神经网络的训练速度可能会很快,但必须选择合适的学习率。
- sigmoid函数:将输入的连续实值变换到(0,1)的范围内,从而可以使神经网络中的每一层权重对应的输入都是一个固定范围内的值,所以权重的取值也会更加稳定。

缺点:
(1)输出的均值不是0,会导致下一层的输入的均值产生偏移,可能会影响神经网络的收敛性;
(2)计算复杂度高;
(3)饱和性问题,当输入值x是比较大的正数或比较小的负数时,sigmoid函数提供的梯度会接近0,导致参数更新变得非常缓慢。sigmoid函数的导数的取值范围是(0,0.25],当深度学习网络层数较多时,通过链式法则计算偏导,相当于很多小于0.25的值相乘,由于初始化的权重的绝对值通常小于1,就会导致梯度趋于0,进而导致梯度消失。
- tanh函数:把输入变换到(-1,1)的对称范围内,解决了sigmoid函数的非零均值问题。但是输入很大或很小时,tanh的输出是非常平滑的,不利于权重更新,仍没有解决梯度消失问题。


- ReLU函数



- PReLU/Leaky ReLU函数

- ELU函数


8.损失函数
- 均方差损失函数:
假设激活函数是sigmoid函数,则,
均方差损失函数对w和b的梯度为:


- 交叉熵损失函数


9.过拟合与正则化
过拟合:


正则化:提高泛化能力
- 参数范数惩罚:在损失函数中增加对高次项的惩罚,可以避免过拟合。



- 稀疏化

- Bagging集成学习


- Dropout:在训练阶段会随机删掉一些隐层节点,在计算时无视这些连接。





- 提前终止:当训练较大网络模型时,能观察到训练误差会随着时间的推移降低而在测试集上的误差却再次上升,因此训练过程中一旦测试误差不再降低且达到预定的迭代次数,就可以提前终止训练。
- 多任务学习:多个相关任务同时学习来减少神经网络的泛化误差。
- 数据集增强:使用更多数据进行训练,可对原数据集进行变换形成新数据集添加到训练数据中。
- 参数共享:强迫两个模型的某些参数相等,使其共享唯一的一组参数。
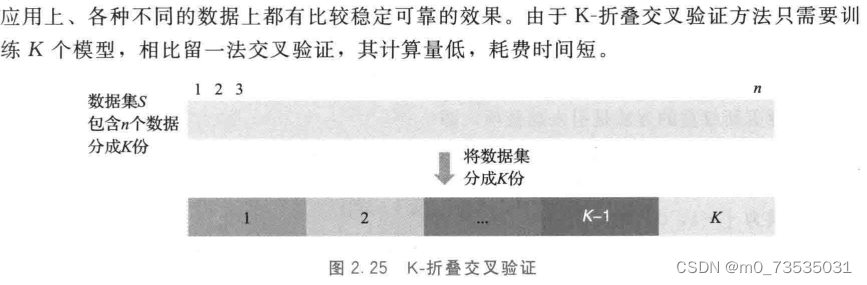
10.交叉验证
要求把机器学习用到的数据集分成两部分,一部分是训练集,一部分是测试机集。
随机分:

留一法:

K-折叠:















 420
420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









