






Python数据分析之pandas-3
文章目录
准备工作
3.1 数据重塑和轴向旋转
(1)层次化索引
- 层次化索引是pandas的一项重要功能,它能使我们在一个轴上拥有多个索引。
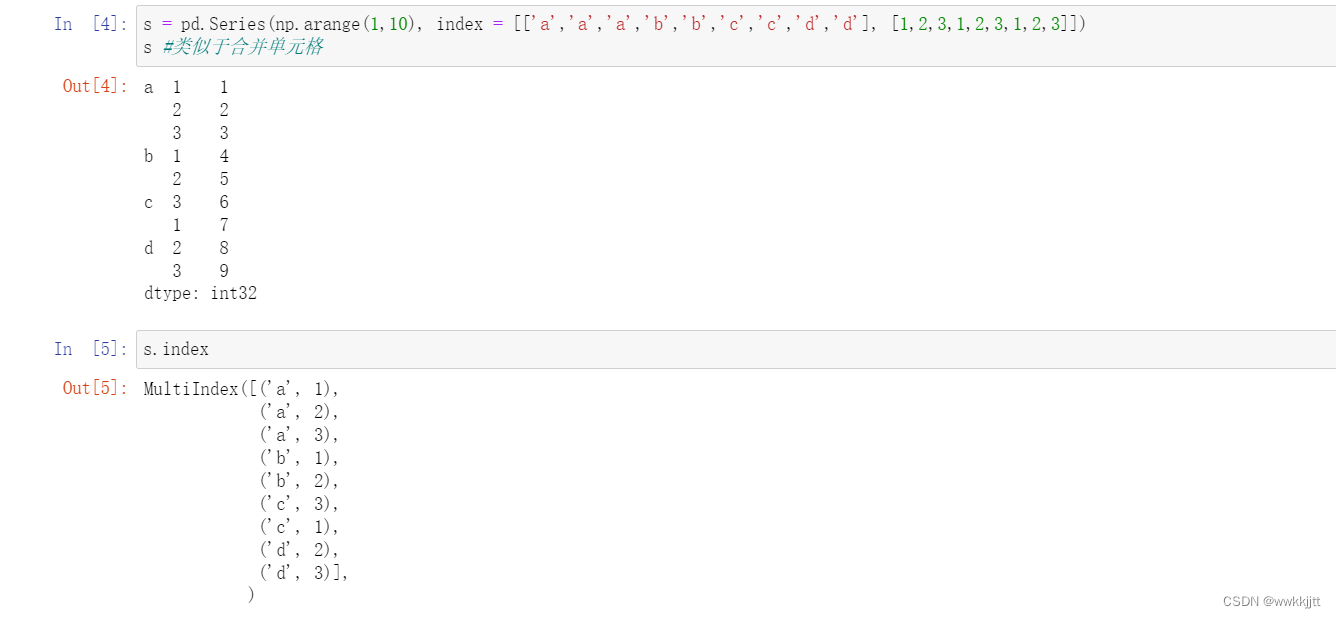
- Series的层次化索引:
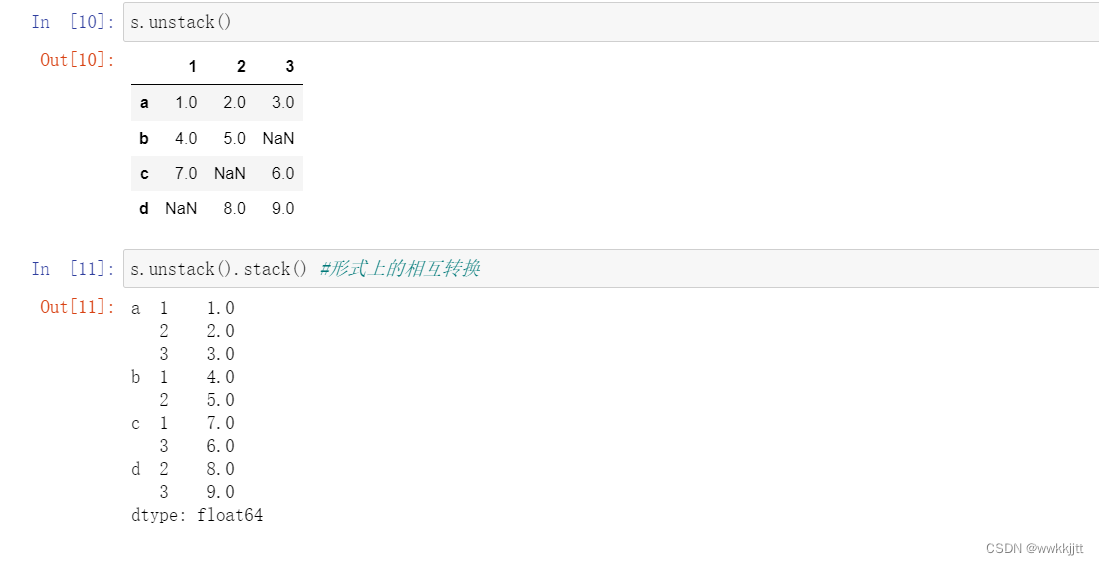
- 通过unstack方法可以将Series变成一个DataFrame:
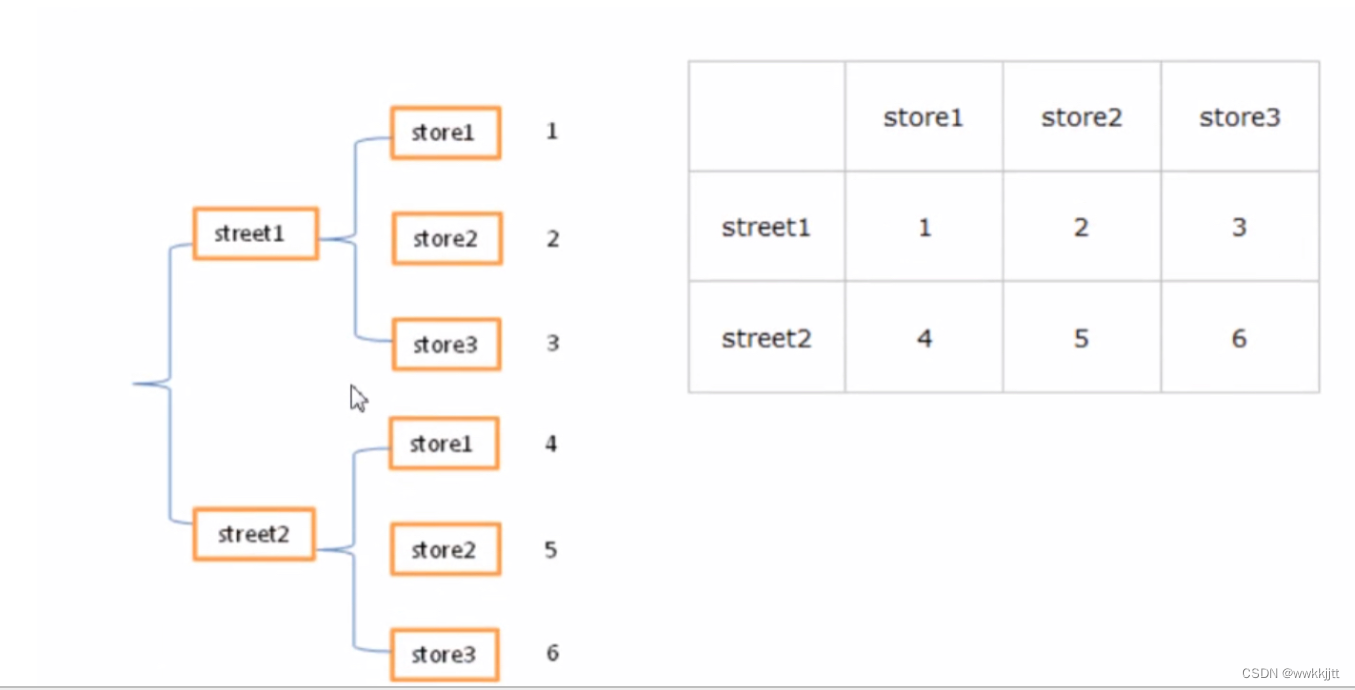
- Dataframe的层次化索引:

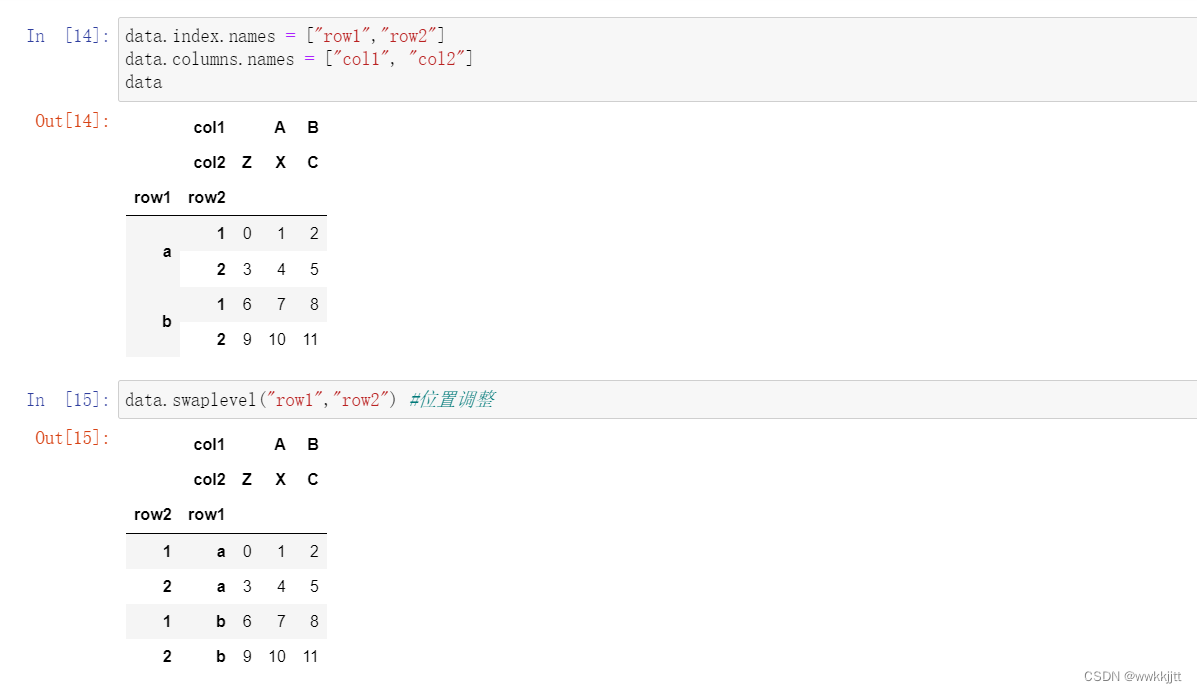
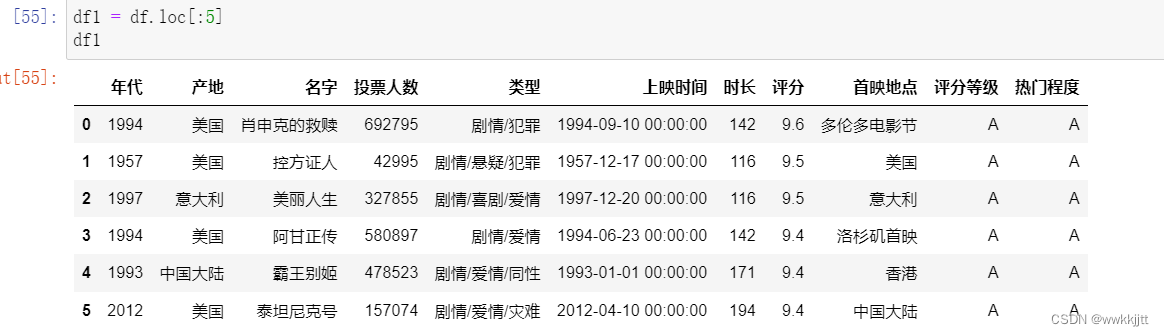
- set_index可以把列变成索引
reset_index是把索引变成列
(2)数据旋转
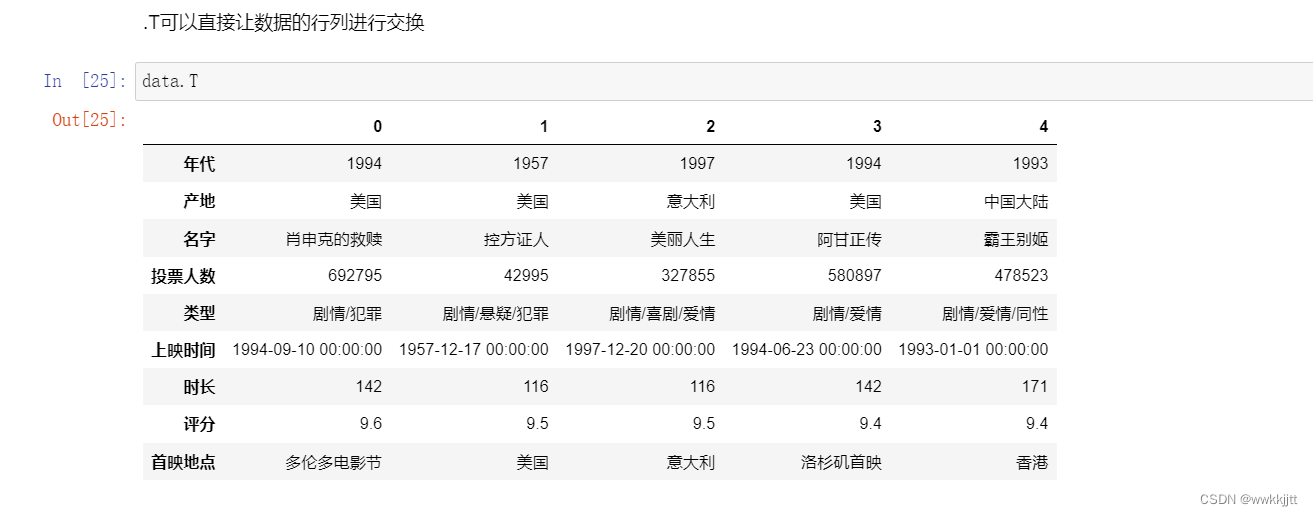
.T可以直接让数据的行列进行交换:
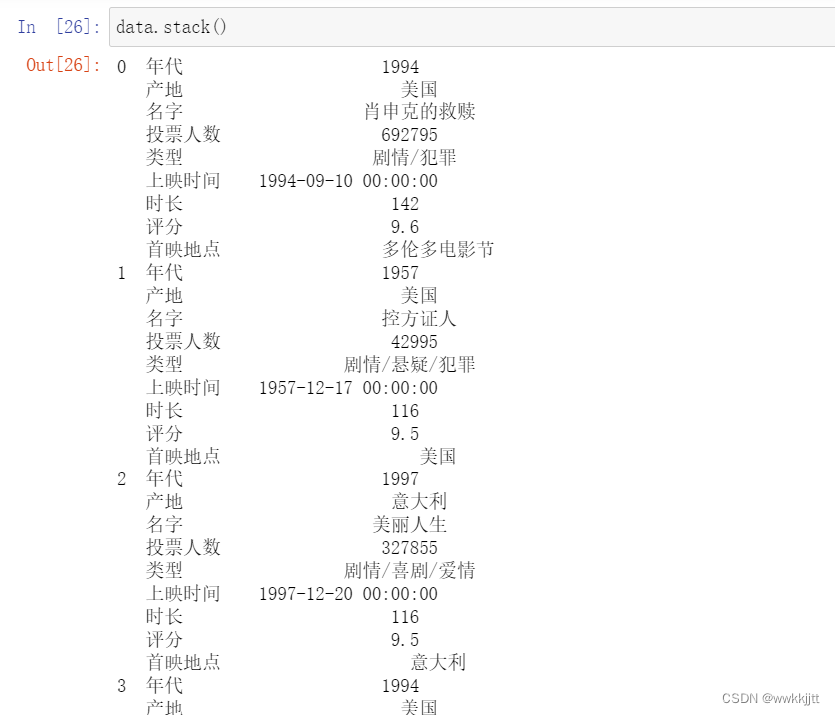
- dataframe也可以使用stack和unstack,转化为层次化索引的Series:
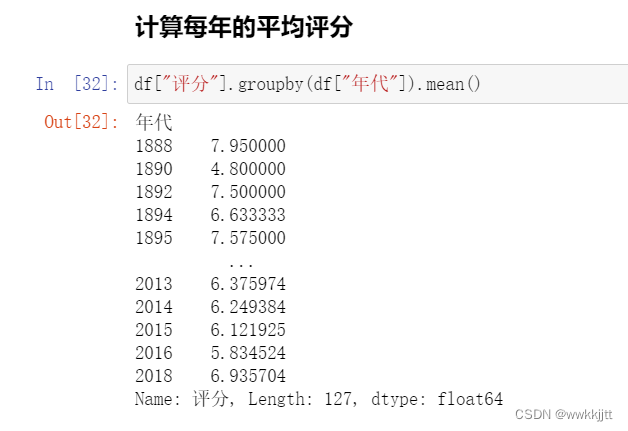
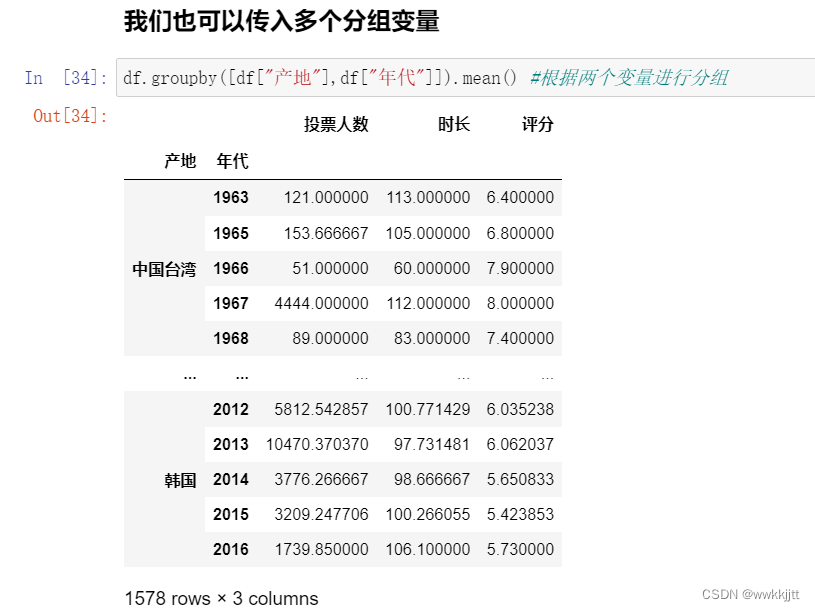
3.2 数据分组,分组运算
- GroupBy技术:实现数据的分组,和分组运算,作用类似于数据透视表

3.3 离散化处理
-
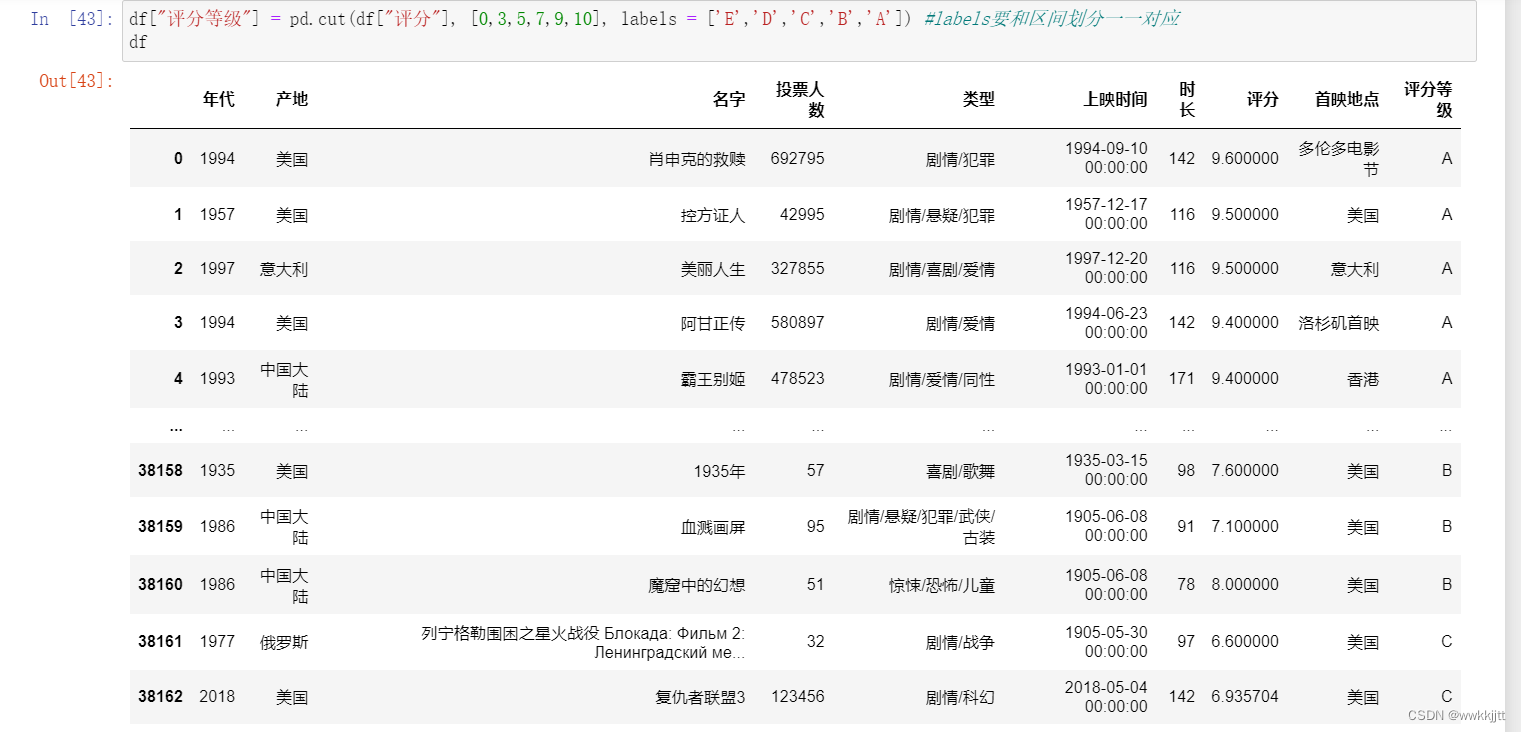
在实际的数据分析项目中,对有的数据属性,我们往往并不关注数据的绝对取值,只关心它所处的区间或者等级。
-
比如,我们可以把评分9分及以上的电影定义为A,7到9分定义为B,5到7分定义为C,3到5分定义为D,小于3分定义为E。
-
离散化也可称为分组、区间化。
-
Pandas为我们提供了方便的函数cut():
pd.cut(x,bins,right = True,labels = None, retbins = False,precision = 3,include_lowest = False) -
参数解释:
-
x:需要离散化的数组、Series、DataFrame对象
-
bins:分组的依据
-
right = True
-
include_lowest = False,默认左开右闭,可以自己调整
-
labels:是否要用标记来替换返回出来的数组
-
retbins:返回x当中每一个值对应的bins的列表
-
precision精度
-
3.4 合并数据集
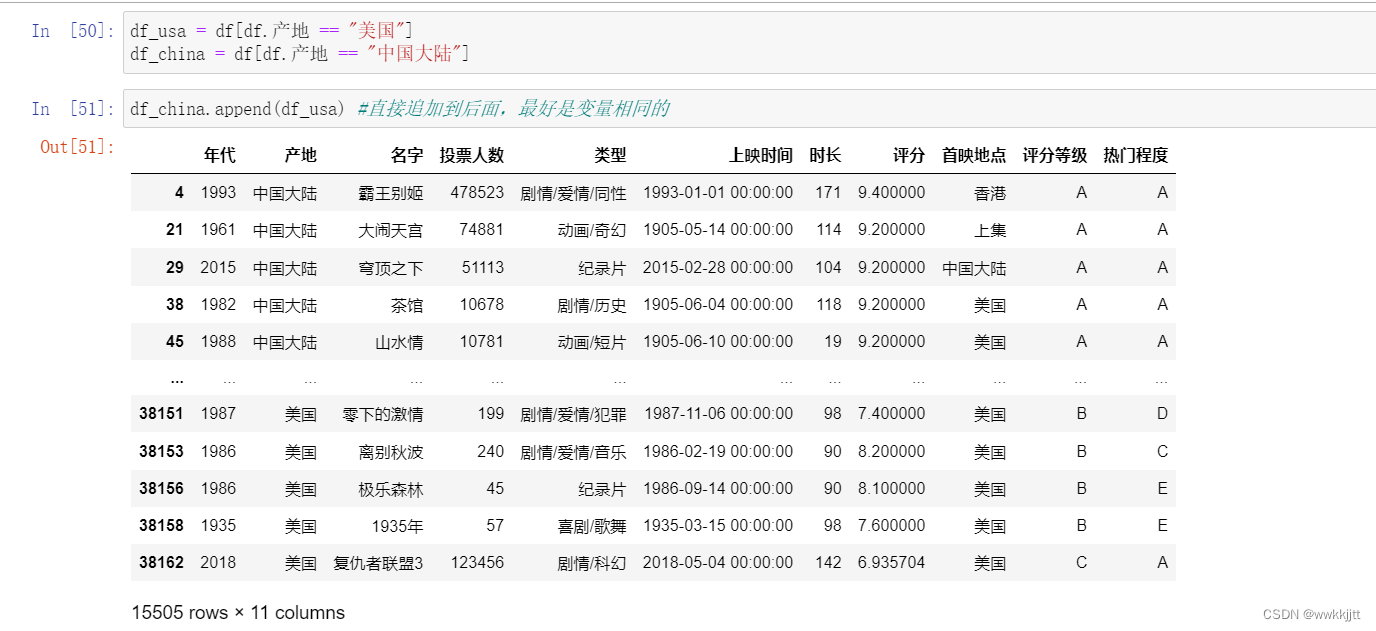
( 1 )append
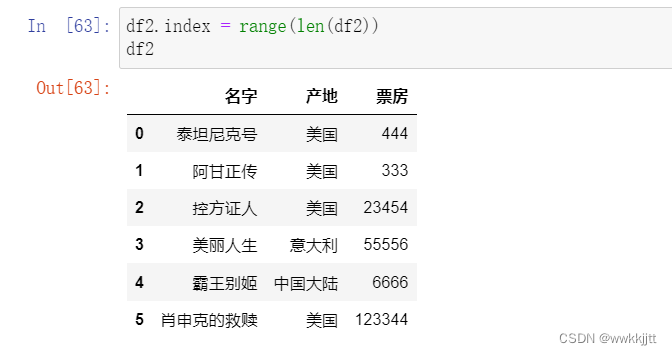
( 2 )merge

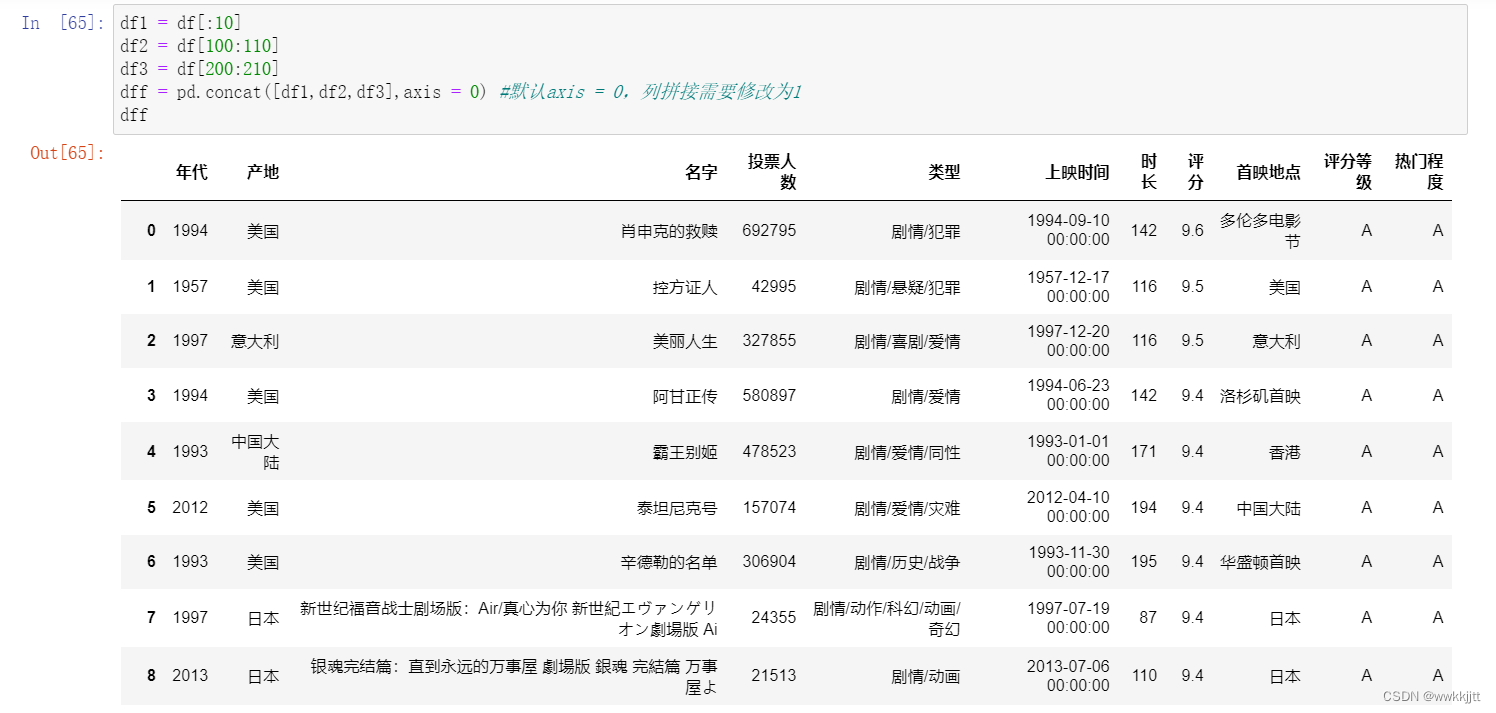
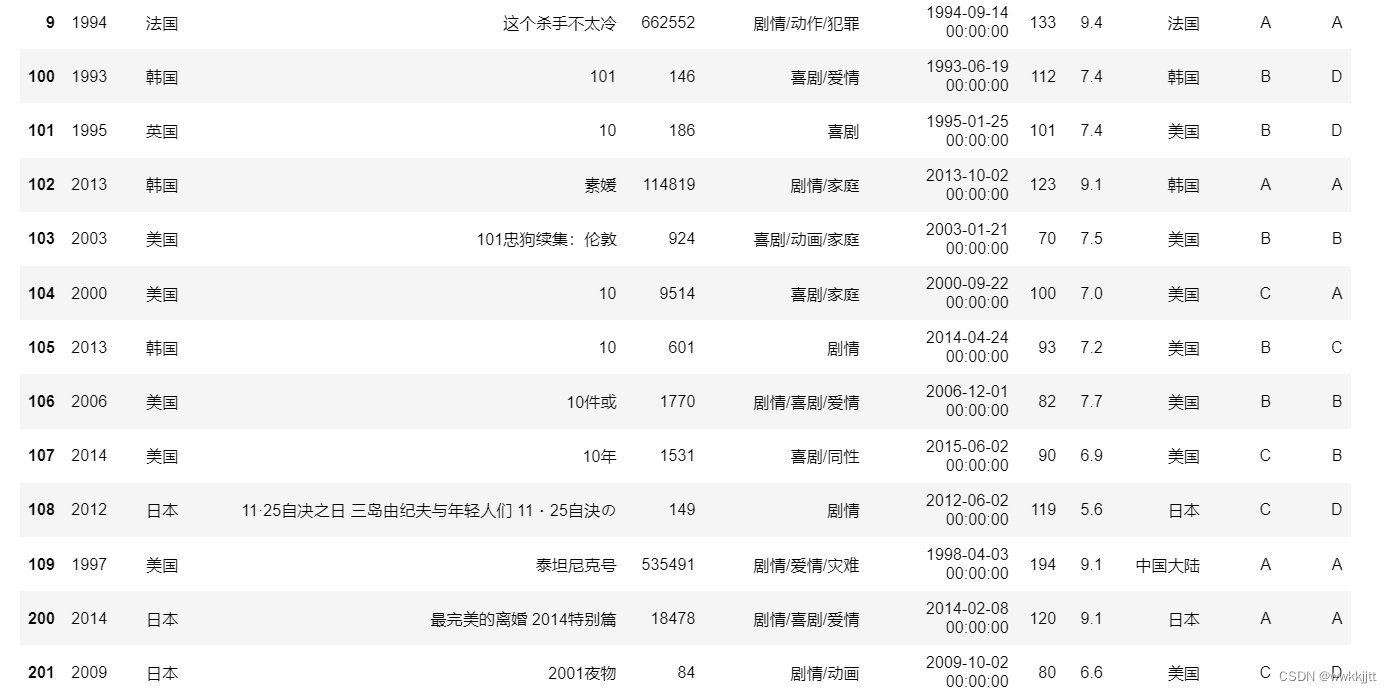
( 3 )concat
以上就是本文的全部内容,感谢各位的阅读与支持!















 1317
1317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









