









本文所用参数含义:
i 当前循环下的起始节点 j 当前循环下的结束节点 k 当前循环下的中心节点
1.思考背景
在B站学习Floyd算法时出现了一个Path矩阵用来记录路径信息,但是在程序过程演示的时候对这个矩阵的更新逻辑产生了疑问,为什么在更新的时候,Path矩阵要把Path(i,j)这个位置的路径点更新为Path(i,k)这个位置对应的路径点呢,而不是把Path(i,j)这个位置更新为k呢?思考许久,笔者认为可以用递归思维去理解。
2 递归思维
递归思维,简单地说,就是如果在函数中存在着调用函数本身的情况,这种现象就叫递归。用大白话来理解,就是你每天不断疯狂锻炼,最后练出了八块腹肌(doge)。那如果抽象的概括一下,也就是我们不断循环一个过程,达到一个结果。那么笔者为什么会认为这个矩阵有着递归的影子呢?我们通过一个例子来看。

这个图的权重邻接矩阵是:

这个例子里面,我们定义了一个如上结构的图,我们将这一个图抛入Floyd算法并逐循环分析。注意,为了简化过程,我们只关注1~4这一条路径。
2.1Path矩阵初始化:
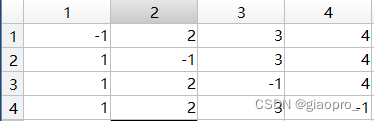
Floyd算法核心:
for k=1:n % 中间节点k从1 ~ n 循环
for i=1:n % 起始节点i从1 ~ n 循环
for j=1:n % 终点节点j从1 ~ n 循环
if dist(i,j)>dist(i,k)+dist(k,j) % 如果i,j两个节点间的最短距离大于i和k的最短距离+k和j的最短距离
dist(i,j)=dist(i,k)+dist(k,j); % 那么我们就令这两个较短的距离之和取代i,j两点之间的最短距离
path(i,j)=path(i,k); % 起点为i,终点为j的两个节点之间的最短路径要经过的节点更新为path(i,k)
end
end
end
end
2.2第一次循环(即k = 1):
Path更新为:
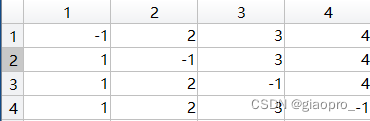
没有变化,因为1节点作为头节点并不能串联连接它的两个节点(1节点度为1)
2.3第二次循环(即k = 2):
Path更新为:
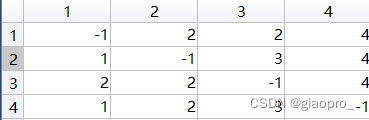
Path(1,3)位置更新为2,Path(3,1)位置更新为2。显然,若没有2这个节点,1和3之间距离为inf,而2节点作为中间节点串联1和3,使1,3之间距离缩短为了8,所以进行了更新。
2.4第三次循环(即k = 3):
Path更新为:
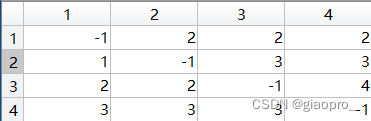
注意我们这里只关注1~4这条路径,所以笔者这里着重分析Path(1,4)这个位置的数据更新!!!
我们可以看到,Path(1,4)位置的数据更新成了2,这是为什么呢?
让我们先从程序的角度分析:在更新之前,我们可以得知,1~4的Distance数据为inf(因为1~4在图上并不直接相连),1~3的距离为8,3~4的距离为4,根据代码:
if dist(i,j)>dist(i,k)+dist(k,j)
dist(i,j)=dist(i,k)+dist(k,j);
path(i,j)=path(i,k);
endPath(1,4)数据更新为Path(1,3)数据,即2。
那么接下来,笔者就从递归角度来解读这个更新逻辑。首先我们知道,通过Floyd算法逻辑,1节点和4节点的中间节点为3节点,再通过Floyd算法,1节点和3节点的中间节点为2节点,再通过Floyd算法,1节点和2节点的中间节点为2节点,输出结果也就是2,那么我们写入Path(1,4)位置。不难看出,上面的逻辑就满足着递归思维,把Floyd算法作为函数,在循环中不断调用它,最后得到结果,更新矩阵。
以上就是从递归角度取理解这个更新逻辑了,到了这里,我们其实可以进一步把Path矩阵抽象化,笔者这里把它抽象化了一个寄存器,它存储的是递归函数Floyd算法每一步的值。为什么这么理解呢?还是上一段那个例子,1和3的中间节点2就可以理解为存放在Path(1,3)这个位置,当我们在上一级Floyd算法调用这个Path“寄存器”的时候,就调用了这个位置的值,从而完成递归,更新数据。不仅如此,在最后生成1~4路径的时候,也可以以理解为调用不同层递归结果所串联起来的路径。也正是这种链式思维,Path矩阵的更新方式才是递归方式,Path(1,4)的值是2而不是3也是因为这种思维。是不是很美妙?
好了,以上就是笔者对Floyd算法中Path矩阵的理解方式,希望能够帮助到你,谢谢你的阅读!















 1780
1780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









