







官方定义
Ascend c是CANN针对算子开发场景推出的编程语言,原生支持C和C++标准规范,最大化匹配用户开发习惯;通过多层接口抽象、自动并行计算、李生调试等关键技术,极大提高算子开发效率,助力AI开发者低成本完成算子开发和模型调优部署
使用AscendC开发自定义算子的优势:
- C/C++原语编程,最大化配用户的开发习惯
- 编程模型屏蔽硬件差异,编程范式提高开发效率
- 多层级API封装,从简单到灵活,兼顾易用与高效
- 孪生调试,CPU侧模拟NPU侧的行为,可优先在CPU侧调试
多层接口抽象
软件开发里的多层接口抽象就像是搭乐高。你从最基础的功能块(像数据库这样的东西)开始,然后搭建更高层的东西(比如让用户与程序交互的部分),每一层都依赖于下面的,但却又往上提供了新的功能。这样一来,改动底层的东西不会影响到顶层,使得维护和升级变得简单许多。
自动并行计算
自动并行计算就是让计算机自己搞清楚怎么样分配任务给不同的“厨师”(这里指的是处理器或计算核心),以便同时处理多个任务,大大加快完成的速度。
李生调试
调试是花时间找出这个问题所在的过程,并修正它,让机器能正确运作。孪生调试第一次听说。可能是在CPU调试好,在NPU运行吧。
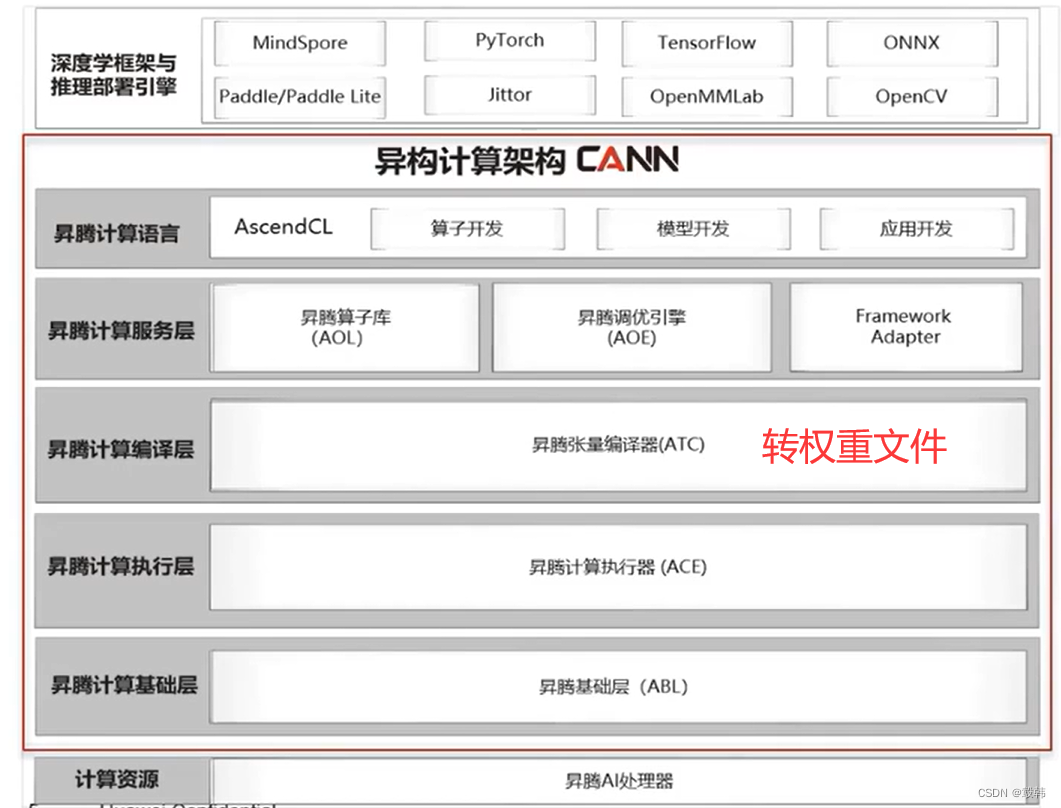
CANN
华为的CANN提供一个统一的开发环境,支持各种规模的AI应用,从边缘设备到云端数据中心
- 兼容性:支持广泛的算法和网络,能够适应各种各样的AI需求和场景。
- 高效性:通过优化的计算库和高效的算法,CANN旨在提供高性能的AI计算能力,充分发挥华为鲲鹏处理器的性能。
- 易用性:提供了丰富的工具和API,简化AI模型的开发和部署过程,使开发者能够更加方便地开发AI应用。
AICORE
AICORE是优化用来处理机器学习和深度学习模型中的大量计算的处理单元。加速深度学习模型的推理(模型应用阶段)和训练过程。支持在边缘设备上进行实时数据分析和处理,如智能手机上的面部识别、语音助手等。
以华为鲲鹏处理器中的AICORE为例,这些AICORE被设计来加快人工智能模型的处理速度,提升AI任务处理的能力和效率。不同的技术实现和架构解决方案可能会具有不同的名称和特点,但它们的共同目标是利用专门的硬件加速AI计算,从而带来比使用通用处理器更高的性能和效率。
标量计算

int x=0, y=0;
int z=x + y;
向量计算
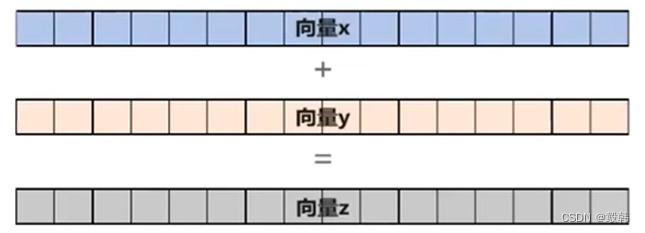
NPU一个核可以在1个时钟周期处理128个FP16的加法
int x[1024],y[1024], Z[1024];
~~
Add(z, ,Y, 1024); //z=x + y;
矩阵计算
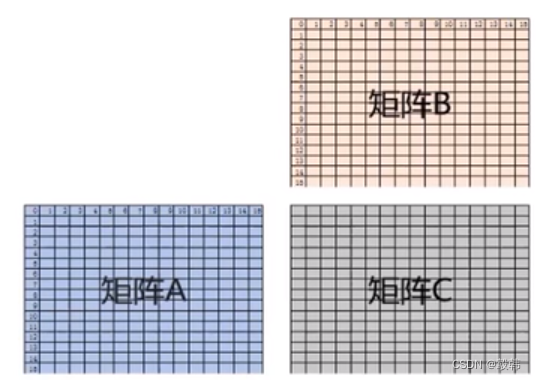
C=AB
NPU一个核可以在1个时钟周期处理完成1616*16的矩阵乘法FP16数据类型的矩阵乘
Mmad(C, A, B, M, K, N);
SIMD,也就是单指令多数据计算,一条指令可以处理多个数据:
Ascend C编程API主要是向量计算API和矩阵运算API,计算API都是SIMD样式
SPMD数据并行与流水线并行
SPMD-单程序多数据
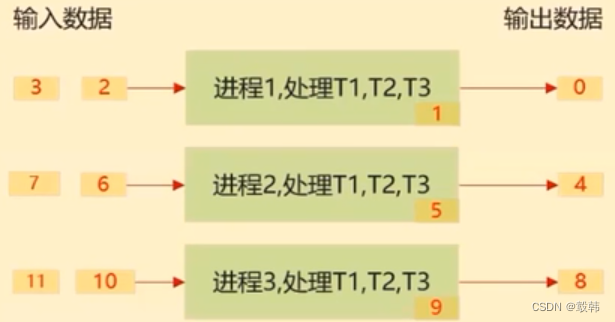
SPMD 数据并行计算原理
- 启动一组进程,他们运行的相同程序
- 把待处理数据切分,把切分后数据分片分发给不同进程处理
- 每个进程对自己的数据分片进行3个任务T1、T2、T3的处理
如何工作: 在深度学习中,SPMD数据并行通常涉及将训练数据集分割成多个批次,然后在多个GPU或其他处理单元上并行处理这些批次。每个处理单元计算其批次数据的梯度,然后通过某种形式的通讯(例如,通过参数服务器或使用All-Reduce操作)聚合这些梯度,以更新全局模型参数。
流水线并行
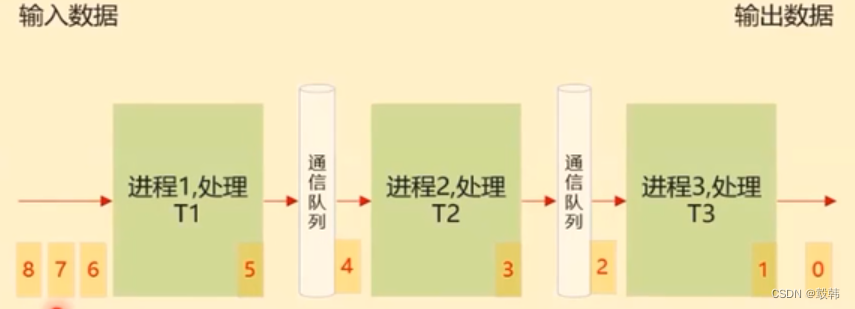
流水线并行原理
- 启动一组进程
- 对数据进行切分
- 每个进程都处理所有的数据切片,对输入数据分片只做一个任务的处理
如何工作: 流水线并行通常用于模型本身很大,不能完全装入单个GPU的显存或需要在多个GPU上分割模型以增加训练速度的情况。训练过程中,不同的模型部分(如不同的层或子网络)被分配到不同的处理单元上。这些单元可以同时处理不同批次的数据,每个单元处理完当前阶段的计算任务后,就将其结果传递给下一个阶段的单元。流水线并行的主要挑战是减少因数据传递和等待而产生的空闲时间。
比较
- 适用场景:SPMD数据并行适用于模型相对较小、可以在单个处理单元上完全载入,但数据集巨大的情况。而流水线并行更适合于那些模型较大,不容易在单个处理器上执行的场景。
- 通讯开销:SPMD数据并行需要在处理单元之间同步模型参数,可能面临较大的通讯开销。流水线并行也有通讯需求(数据和计算结果的传递),但其挑战更多地在于优化流水线的效率,减少延迟和空闲时间。
- 实施复杂性:与SPMD相比,流水线并行可能涉及更复杂的实施策略,因为需要精确地安排和同步不同模型部分的数据流和计算任务。


















 366
366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











