






pandas学习-Series-02
前提:
- 已经完成pandas、juputer notebook的安装
背景:
在这一章中我们还是采用pandas学习-Series-01提到的10种手机列子,这儿我再将表格放在下面并根据表格创建 Series 对象s。
我们有以下部分手机的价格,现在我们要基于以下数据来进行一些数据处理工作。
| 手机名称 | 价格(人民币 |
|---|---|
| OnePlus 11 Pro Max | 4999 |
| Xiaomi Mi 14 Ultra | 5499 |
| Samsung Galaxy S23 Ultra | 7999 |
| Apple iPhone 15 Pro Max | 8999 |
| Google Pixel 8 Pro | 8999 |
| Huawei Mate 60 Pro+ | 6999 |
| Vivo X90 Pro+ | 6499 |
| Oppo Find X6 Pro | 5999 |
| Realme GT Neo5 Ultimate Edition | 5699 |
| Lenovo Legion Y90 Gaming Phone | 3999 |
import pandas as pd
s=pd.Series([4999,5499,7999,8999,8999,6999,6499,5999,5699,3999],
index=['OnePlus 11 Pro Max','Xiaomi Mi 14 Ultra','Samsung Galaxy S23 Ultra','Apple iPhone 15 Pro Max','Google Pixel 8 Pro','Huawei Mate 60 Pro+','Vivo X90 Pro+','Oppo Find X6 Pro','Realme GT Neo5 Ultimate Edition','Lenovo Legion Y90 Gaming Phone'],name='phone_price')
布尔索引筛选
Q:如何筛选手机价格为8999的手机有哪些?如何筛选手机价格在3999-4999之间的手机?
A:
#手机价格为8999的手机
s[s==8999]
#手机价格在3999-4999之间的手机
s[(s>=3999) & (s<=4999)]

在上面列子中我们使用了条件筛选,以此来确定哪些数据要返回,而哪些数据要过滤?
Pandas Series中进行条件筛选,主要使用布尔索引技术 来实现数据的筛选。
什么是布尔索引?
在Pandas库中,布尔索引是一种强大的数据过滤技术,允许你根据Series或DataFrame中的值是否满足特定条件来选择子集。具体来说,你可以通过创建一个布尔型数组(由True和False组成的Series),然后我们就可以提取series 中值为True的值了。
举例来说 我们上面答案中的 s==8999 、 (s>=3999) & (s<=4999)就是重新生成的一个布尔索引。

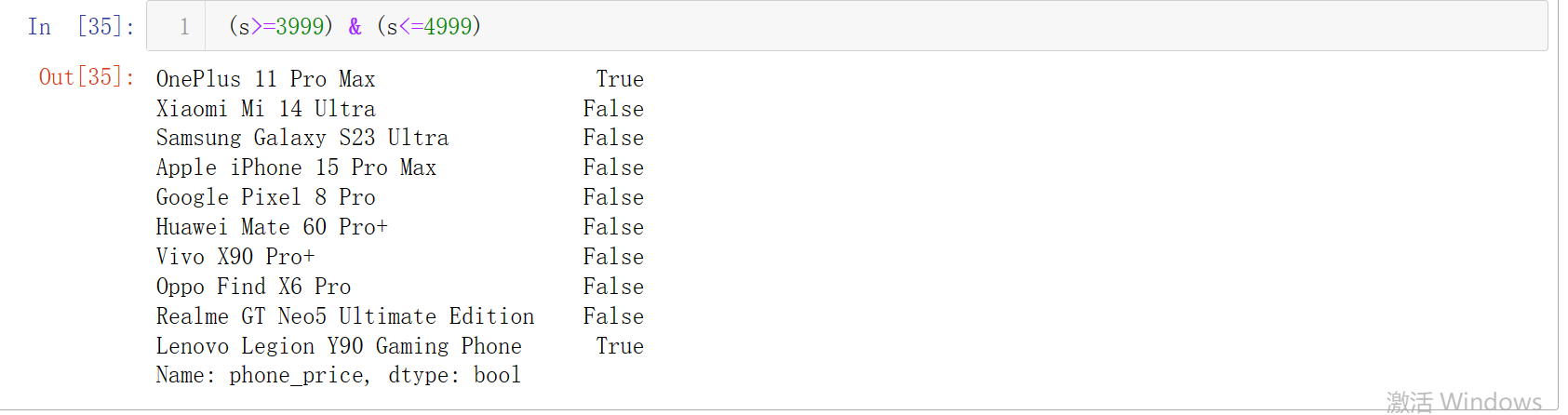
当然,从上面的列子我们亦可以看出,布尔运算也支持同时应用多个条件进行筛选,像我们上面的(s>=3999) & (s<=4999)就是用到了多条件筛选,但我们在使用多条件筛选时候也要注意一些小细节。
- 在使用布尔索引时,不建议直接使用Python的逻辑运算符
and和or。正确的做法是使用位运算符&和|。像我们上面如果使用and则会报语法错误 - 确保每个条件都放在括号内以明确优先级,因为在Python语法中,
&和|是位运算符,在没有括号的情况下会比比较运算符(如>=和<=)有更高的优先级。像上面的列子如果我们不加括号s>=3999 & s<=4999则会先计算3999 & s,当然就会报错了。
布尔索引常用条件过滤方式
直接比较操作:
可以直接使用比较运算符(如>、<、==、>=、<=等)来创建一个布尔Series,然后使用这个布尔Series作为索引来选择满足条件的元素。
我们上面的回答就使用了这种直接比较的方式。
isin()方法:
当需要根据Series中的值是否包含在某个列表或集合中进行筛选时,可以使用isin()函数。
比如,我们要筛选手机价格是3999、4999、5999、6999的手机有哪些?
s[s.isin([3999,4999,5999,6999])]

str.contains()方法:
如果Series的元素是字符串类型,我们也可以使用.str.contains()方法基于子串匹配进行筛选。
s2 = pd.Series(['apple pie', 'banana shake', 'cherry tart'])
# 筛选出值包含'apple'的元素
filtered_s = s2[s2.str.contains('apple')]
这儿我们重新定义了一个新的series对象s2
map()方法:
该方法主要应用于将Series中的每个元素映射到另一个值。它接受一个可调用对象(如函数或字典)作为参数。
比如:我们要筛选所有手机价格中能被3整除的有哪些?
s[s.map(lambda x:x%3==0)]

apply()方法:
对于更复杂的条件筛选,我们也可以自定义函数并结合.apply()方法。
比如,我们要把手机价格按照千位、百位、十位、个位拆开展示呢(假设我们手机的价格都是4位数的)?
def split_four_digit_number(number):
# 假设全是四位数
thousands = number // 1000 % 10
hundreds = number // 100 % 10
tens = number // 10 % 10
ones = number % 10
return {'thousands': thousands, 'hundreds': hundreds, 'tens': tens, 'ones': ones}
s.apply(split_four_digit_number)
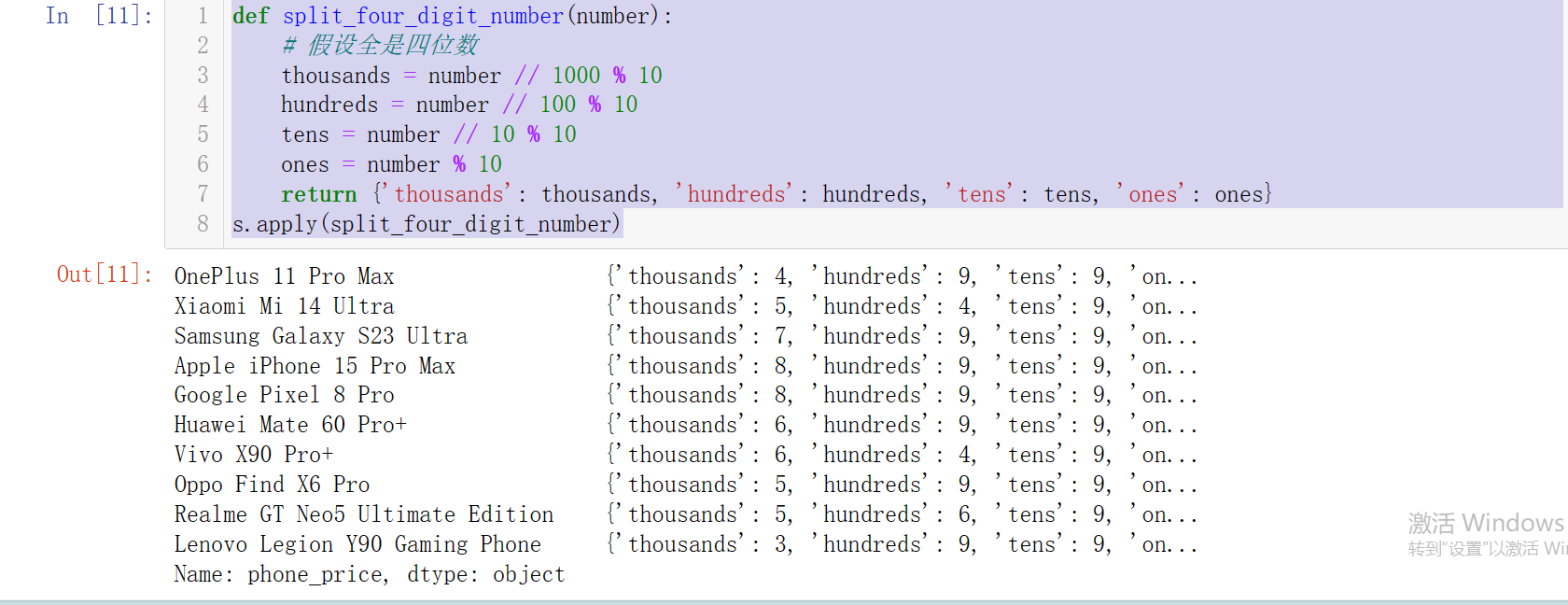
其实如果只是简单地想对Series中的每个元素执行一次简单的、返回单个值的操作,map方法能做到,用apply也都可以实现。但我们返回的是多个值的时候,那apply更加适合。














 1920
1920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









