







一,概念
所谓位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据存不存在的。
为了方便理解我们引入一道面试题,
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。
两个思路:
1.排序+二分
2.set+find
首先40亿个整数占用多少内存?
1G约等于10亿字节,40亿个整数有160亿字节,也就是大约16G左右,
16G是绝对会内存超限的,所以正常的方法我们都不可以使用。
这就要用到位图的思想,我们用比特位去存储数据,一个比特位就是一个数据
因为是存无符号整数,所以最大的数就是2^32,那我们就开这么大的范围。
2^32比特位是多大呢?
是512MB,变小了非常多。
例如50,就如下存储。

找位置
如何找到相应的位置?
还是以50为例。
1.先找到50在第几个整型中
50/32==1
2.50在这个整型的第几个比特位中
50%32==18
总结:
如何找到x对应的位置
- x在第i个整型中 i=x/32
- x在这个整型的第j个比特位中 j=x%32
二,模拟实现位图

这是库中给我们提供的位图,他有比较核心的三个函数组成分别是:set,reset,test。
1.set
set就是把x映射的位标记位1。
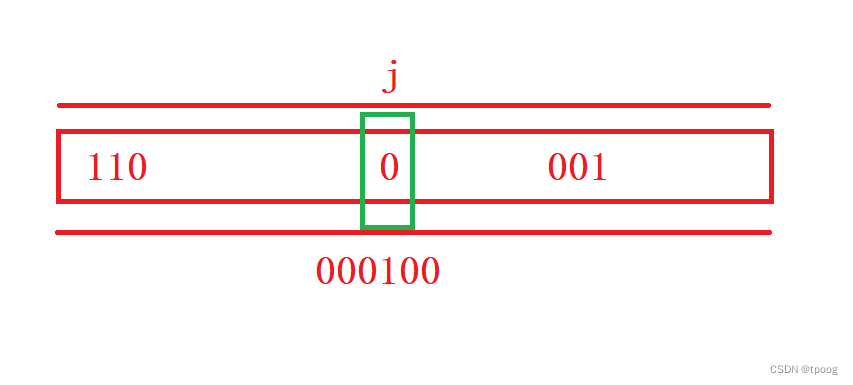
这里用到的位操作是:|
代码
//把x映射的位标记为1
void set(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
_bits[i] |= (1 << j);
}
2.reset
和set的作用相反reset是把x映射的位置标记位0
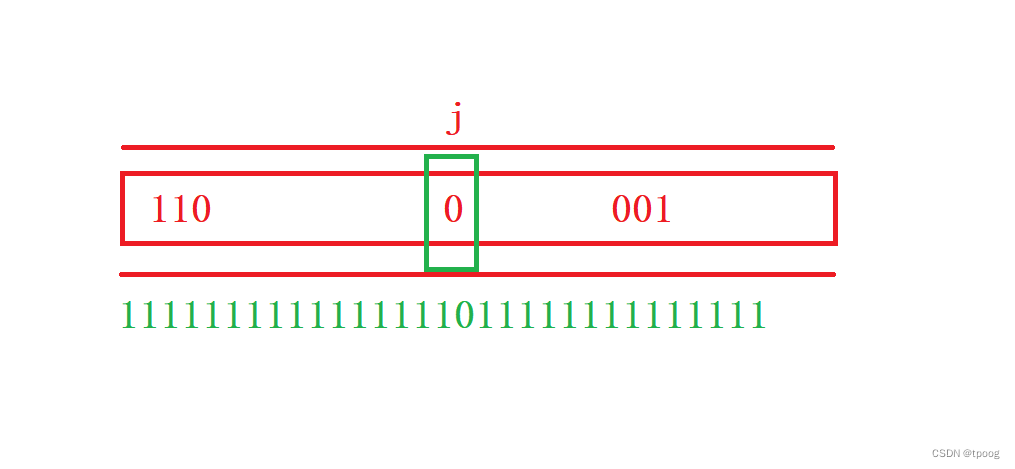
代码
//把x映射的位标记为0
void reset(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
_bits[i] &= ~(1 << j);
}
3.test
test查看指定位置是否为1
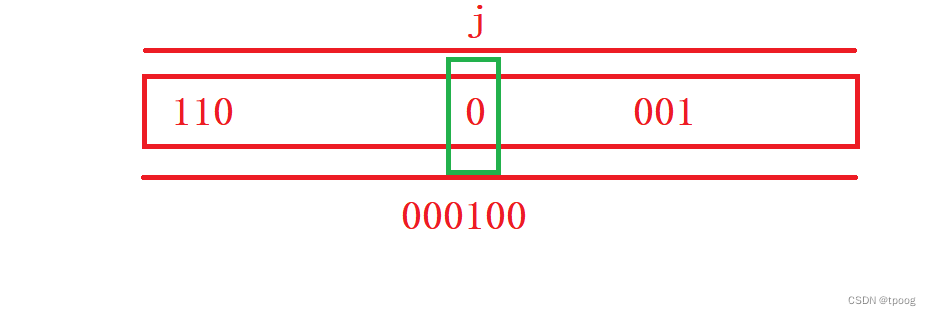
代码
//查看是否有值
bool test(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
return _bits[i]&(1 << j);//0为假,非0就是真
}
全代码
template<size_t N>
class bitset
{
public:
bitset()
{
_bits.resize(N / 32 + 1, 0);
//cout << N << endl;
}
//把x映射的位标记为1
void set(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
_bits[i] |= (1 << j);
}
//把x映射的位标记为0
void reset(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
_bits[i] &= ~(1 << j);
}
//查看是否有值
bool test(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
return _bits[i]&(1 << j);//0为假,非0就是真
}
private:
vector<int> _bits;
};
测试
void test_bitset()
{
bitset<100> bs1;
bs1.set(50);
bs1.set(30);
bs1.set(90);
for (size_t i = 0; i < 100; i++)
{
if (bs1.test(i))
{
cout << i << "->" << "在" << endl;
}
else
{
cout << i << "->" << "不在" << endl;
}
}
}
三,面试题(位图拓展)
1,给定100亿个整数,设计算法找到只出现一次的整数
还是先算100亿个整数占多少内存,
1G是10亿字节,100亿个整数大概40G内存
刚刚是统计在不在,而这里是统计次数,那我们的思路就是用两个位图来统计
00:表示出现0次
01:表示出现1次
10:表示2次及以上
实现
1.set
如果是00就把他变成01
如果是01就把他变成10
// 00 -> 01
// 01 -> 10
void set(size_t x)
{
// 00 -> 01
if (_bs1.test(x) == false && _bs2.test(x) == false)
{
_bs2.set(x);
}
// 01 -> 10
else if (_bs1.test(x) == false && _bs2.test(x) == true)
{
_bs1.set(x);
_bs2.reset(x);
}
}
2.test
这就是单纯的返回值就好了
int test(size_t x)
{
// 00 -> 01
if (_bs1.test(x) == false && _bs2.test(x) == false)
{
return 0;
}
// 01 -> 10
else if (_bs1.test(x) == false && _bs2.test(x) == true)
{
return 1;
}
else
{
return 2;
}
}
测试
void test_bitset2()
{
int a[] = { 5,7,9,2,5,99,5,5,7,5,3,9,2,55,1,5,6 };
two_bit_set<100> bs;
for (auto e : a)
{
bs.set(e);
}
for (size_t i = 0; i < 100; i++)
{
//cout << i << "->" << bs.test(i) << endl;
if (bs.test(i))
{
cout << i << endl;
}
}
}
完整代码
template<size_t N>
class two_bit_set
{
public:
// 00 -> 01
// 01 -> 10
void set(size_t x)
{
// 00 -> 01
if (_bs1.test(x) == false && _bs2.test(x) == false)
{
_bs2.set(x);
}
// 01 -> 10
else if (_bs1.test(x) == false && _bs2.test(x) == true)
{
_bs1.set(x);
_bs2.reset(x);
}
}
int test(size_t x)
{
// 00 -> 01
if (_bs1.test(x) == false && _bs2.test(x) == false)
{
return 0;
}
// 01 -> 10
else if (_bs1.test(x) == false && _bs2.test(x) == true)
{
return 1;
}
else
{
return 2;
}
}
private:
bitset<N> _bs1;
bitset<N> _bs2;
};
2.给定两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件的交集?
两个位图做相与操作
3. 一个文件有100亿个整数,1G内存,设计算法找到出现次数不超过2次的所有整数。
这个就是第一个的变形,我们增加一个11记录三次及以上的数,把1次和2次的整数找出来即可。
4.给定100亿个整数,设计算法找到只出现一次的整数(限制512MB内存)
这题难在限制了内存,100亿整数按照常规位图操作要1G的空间才行。
还是开两个位图,分两次统计,第一次只统计<2^31大小的值
第二次统计剩余的值即可。

















 3800
3800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











