






一、决策树简介
决策树是一种常用的机器学习算法,用于分类和回归任务。它通过一系列的决策节点将数据集划分成不同的子集,直到达到某个终止条件。每个决策节点代表一个属性测试,每个分支代表测试结果的一个可能取值,而每个叶子节点代表一个类别标签或回归值。决策树的构建过程通常采用递归分割,基于某些指标(如信息增益、基尼不纯度等)来选择最佳的属性进行分割。决策树易于理解和解释,具有很好的可解释性,但可能会过拟合训练数据。为了减少过拟合,可以通过剪枝、设置树的最大深度、最小样本拆分等方式来调节决策树模型。下面通过一个简单的例子来阐述它的执行流程。 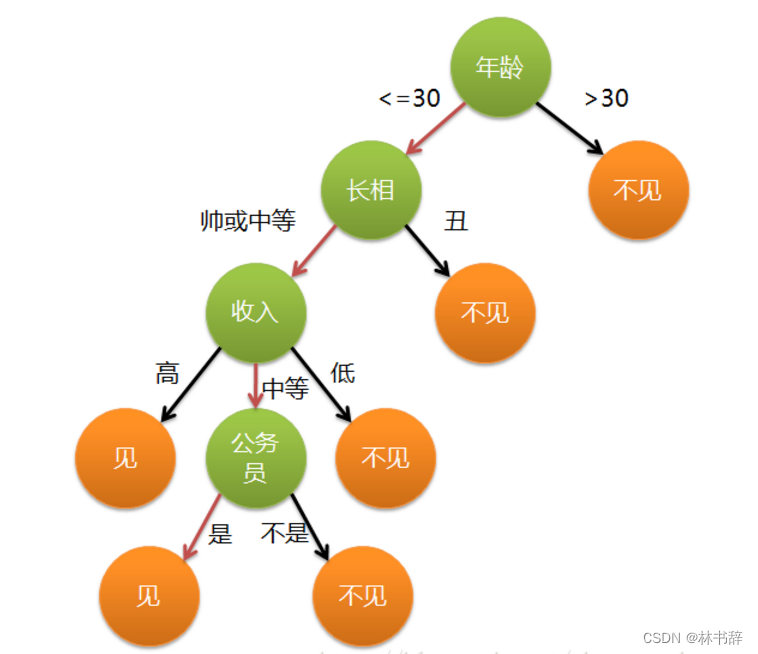
决策树的特点:
优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
缺点:可能会产生过度匹配的问题
适用数据类型:数值型和标称型
二、决策树的构造
决策树的构造过程主要包括以下几个步骤:
-
选择划分属性: 从训练数据集中选择一个属性作为当前节点的划分属性。选择划分属性的准则通常是根据某种指标(如信息增益、基尼不纯度)来衡量划分后数据集的纯度或不确定性减少程度。
-
划分数据集: 根据选定的划分属性将数据集划分成不同的子集,每个子集对应划分属性的一个取值。这一步将构造出当前节点的子节点,并将数据集按照划分属性的不同取值划分到相应的子节点中。
-
递归构建子树: 对每个子节点重复上述过程,选择划分属性、划分数据集,直到满足终止条件。终止条件可以是节点中样本的数量小于某个阈值、节点中样本的类别纯度达到某个阈值,或者达到了树的最大深度等。
-
剪枝: 为了避免过拟合,可以对构建好的决策树进行剪枝。剪枝的目的是去掉一些不必要的节点和分支,简化模型,提高泛化能力。常用的剪枝方法有预剪枝(在构建过程中就进行剪枝)和后剪枝(在构建完成后对决策树进行剪枝)两种。
-
生成决策规则: 最终得到的决策树可以转化为一系列的决策规则,这些规则可以被用来对新的数据进行分类或回归预测。
在构造决策树时,需要选择合适的划分属性、终止条件和剪枝策略,以达到构建出泛化能力强的模型的目的。同时,决策树的构造过程可以通过递归算法实现,也可以采用迭代的方式进行。
三、划分选择
1、熵与条件熵
熵(Entropy)是表示随机变量不确定性的度量。说简单点就是物体内部的混乱程度。
熵的定义如下:![]()
在决策树中,熵越高表示数据集的不确定性越大,即数据集中包含的不同类别的样本数量相对均衡,难以进行有效的划分;而熵越低表示数据集的纯度越高,即数据集中的样本大部分属于同一类别,易于进行划分。
条件熵是信息论中的一个概念,用于衡量在给定某个特征条件下的信息不确定性。在决策树算法中,条件熵通常用于衡量在某个特征的取值已知的情况下,对数据集进行分类所需要的信息量。
具体来说,假设我们有一个数据集,其中包含多个类别的样本,而我们想要根据某个特征来对这些样本进行分类。条件熵就是在已知该特征的取值情况下,对每个取值所对应的子集进行分类所需要的信息量的期望值。
条件熵的计算公式如下: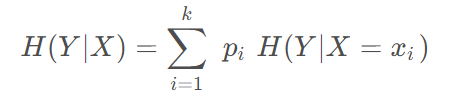
其中,(H(Y|X))表示在特征(X)已知的条件下,对目标变量(Y)的条件熵,(P(x,y))表示特征(X)取值为(x)且目标变量(Y)取值为(y)的样本的概率,(P(y|x))表示在特征(X)取值为(x)的条件下,目标变量(Y)取值为(y)的样本的概率。
通过计算条件熵,我们可以评估在特征已知的情况下,对数据集进行分类所需要的平均信息量。在决策树算法中,通常会选择能够使得条件熵最小化的特征作为划分标准,因为这样可以使得分类结果更加纯净。
2、ID3算法(信息增益)
信息增益 𝑔(𝐷, 𝑋) :表示某特征 𝑋 使得数据集 𝐷 的不确定性减少程度,定义为集合 𝐷 的熵与在给定特征 𝑋 的条件下 𝐷 的条件熵 𝐻(𝐷 | 𝑋) 之差,即![]()
信息熵减去条件熵,表示的含义是该属性a能够为分类系数带来多少信息,信息愈多,该特征就越重要,所以当信息增益越大时,则意味着使用属性a来进行划分所获得的纯度越大。
3、C4.5算法(信息增益率)
信息增益率 𝑔𝑅(𝐷, 𝑋) 定义为其信息增益 𝑔(𝐷, 𝑋) 与数据集 𝐷 在特征 𝑋 上值的熵 𝐻𝑋(𝐷) 之比,即: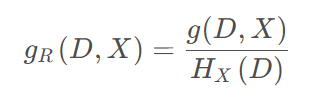 ,其中,
,其中,![]() 相当于是给定属性X下的信息增益与特特征个数的信息熵之间的比值。从上式可以看出,信息增益率考虑了特征本身的熵(此时,当某特征取值类别较多时,𝑔𝑅(𝐷, 𝑋) 式中的分母也会增大),从而降低了 “偏向取值较多的特征” 这一影响。
相当于是给定属性X下的信息增益与特特征个数的信息熵之间的比值。从上式可以看出,信息增益率考虑了特征本身的熵(此时,当某特征取值类别较多时,𝑔𝑅(𝐷, 𝑋) 式中的分母也会增大),从而降低了 “偏向取值较多的特征” 这一影响。
4、CART(基尼系数)
CART算法使用基尼系数(Gini Index)来选择特征进行划分。基尼系数衡量了数据集的纯度,值越小表示数据集的纯度越高。在每个节点上,CART算法尝试所有可能的特征和阈值组合,并选择使得基尼指数最小的特征和阈值作为划分依据。
分类问题中假设有K个类,样本点属于第k类的概率为 Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2
对于二分类问题,若样本点属于第1个类的概率为p,则概率分布的基尼指数为 Gini(p)=2p(1−p)
计算每一个特征的Gini指数
Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
显然,采用越好的特征进行划分,得到的基尼增益也越大。基于前面各特征对数据集的划分,可得到其对应的基尼增益。
四、剪枝处理
决策树的剪枝是为了减小模型复杂度,提高泛化能力而进行的一种优化方法。剪枝通过删去一些子树或叶节点,并将其父节点作为新的叶节点来实现。决策树的剪枝可以分为预剪枝(Pre-Pruning)和后剪枝(Post-Pruning)两种方式。
-
预剪枝:
预剪枝是在决策树生成过程中,在每个节点划分前先进行判断,若当前节点的划分不能带来泛化性能的提升,则停止划分,将当前节点标记为叶节点。预剪枝的优点是简单快速,能够避免过拟合,但可能会造成欠拟合。 -
后剪枝:
后剪枝是在决策树生成完毕后,自底向上地对决策树进行剪枝。具体步骤是对每个内部节点进行评估,若剪去该节点的子树能够提高验证集上的性能,则剪去该子树。后剪枝的优点是可以在生成完整决策树后进行全局优化,能够更好地提高泛化性能,但相对复杂且计算量较大。 -
剪枝策略:
剪枝策略通常使用交叉验证或者验证集来确定。对于后剪枝,可以通过比较剪枝前后模型在验证集上的性能来决定是否剪枝。常用的剪枝策略有最小误差剪枝(Minimum Error Pruning)和代价复杂度剪枝(Cost Complexity Pruning)等。 -
最小误差剪枝:
最小误差剪枝是一种简单的剪枝策略,它计算每个内部节点的剪枝后误差与不剪枝误差的差值,选择使得差值最小的节点进行剪枝。 -
代价复杂度剪枝:
代价复杂度剪枝考虑了剪枝后模型的复杂度和模型性能之间的权衡。它引入一个代价复杂度参数,通过最小化损失函数和复杂度参数的乘积来选择最优的剪枝方式。
五、实例
1.ID3
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
# 加载数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树模型
clf = DecisionTreeClassifier(criterion="entropy", random_state=42)
clf.fit(X_train, y_train)
# 可视化决策树
plt.figure(figsize=(20,10))
plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.show()
2.C4.5
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
# 加载数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建C4.5决策树模型
clf = DecisionTreeClassifier(criterion="entropy", random_state=42)
clf.fit(X_train, y_train)
# 可视化决策树
plt.figure(figsize=(20,10))
plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.show()















 5212
5212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









