






一、逻辑回归概述
逻辑回归是一种用于解决分类问题的统计学习方法,尤其适用于二元分类(即预测结果为两个类别中的一个)的情况。尽管名字中带有“回归”,但逻辑回归实际上是一种分类算法而非回归算法。
逻辑回归的思想是基于对事件发生概率的估计进行分类。它使用一种称为Sigmoid函数的特殊函数来将输入特征的线性组合转换成介于0和1之间的概率值。从而将观测样本划分到两个类别中的一个。
二、Sigmoid函数
Sigmoid函数(也称为逻辑函数)是一种特殊的数学函数,它具有将实数映射到区间(0, 1)上的性质。在逻辑回归中,sigmoid函数被用来将输入特征的线性组合转换成表示概率的数值。其数学形式通常写作: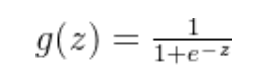
Sigmoid函数的图像呈S形曲线,如下图所示::
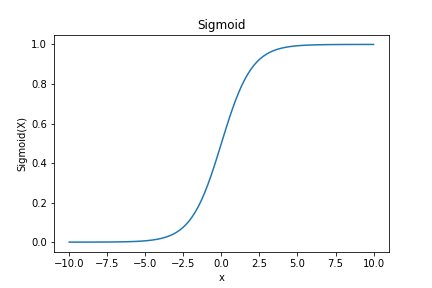
Sigmoid函数在逻辑回归中扮演着重要的角色,它将输入的线性组合映射到一个介于0和1之间的概率值,以便进行二元分类预测。通过Sigmoid函数的映射,逻辑回归模型可以输出观测样本属于某个类别的概率,然后根据设定的阈值进行最终的分类决策。
三、梯度下降法
梯度下降法是一种常用的优化算法,用于最小化损失函数或目标函数。在逻辑回归中,我们希望找到使得损失函数(通常是对数似然损失函数)最小的模型参数,以便使模型能够更好地拟合训练数据和进行准确的预测。梯度下降法是一种迭代的优化方法,它利用损失函数关于模型参数的梯度信息来不断更新参数值,直到达到损失函数的局部最小值或全局最小值。
梯度下降法的基本思想是沿着损失函数梯度的反方向更新参数值,以减小损失函数的值。具体而言,梯度下降法的步骤如下:
- 初始化模型参数:随机初始化模型参数的数值。
- 计算损失函数的梯度:计算当前模型参数下损失函数对各个参数的偏导数,得到梯度。
- 更新模型参数:沿着梯度的反方向,按照一定的学习率(学习率决定了每次参数更新的大小)更新模型参数。
- 重复步骤2和步骤3,直到满足停止条件(如达到最大迭代次数或损失函数收敛)。
四、代码实现
案例:基于逻辑回归模型的鸢尾花分类预测,并可视化预测结果的散点图。
鸢尾花训练数据:
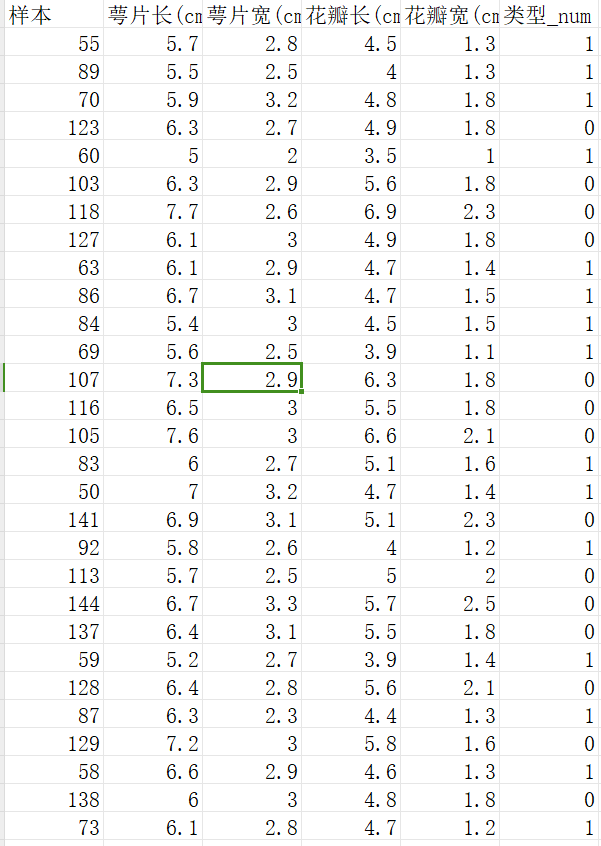
鸢尾花测试数据: 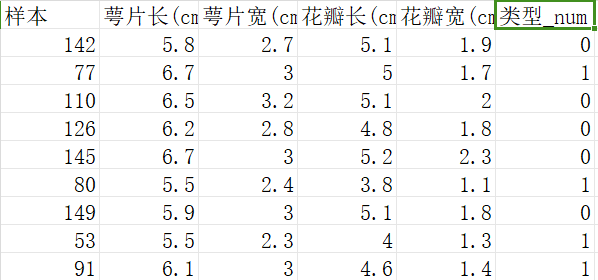
代码部分:
import pandas as pd
# 读取鸢尾花训练数据
train_data = pd.read_excel('鸢尾花训练数据.xlsx')
# 读取鸢尾花测试数据
test_data = pd.read_excel('鸢尾花测试数据.xlsx')
# 提取训练、测试数据的特征列
train_X = train_data[['萼片长(cm)', '萼片宽(cm)', '花瓣长(cm)', '花瓣宽(cm)']]
test_X = test_data[['萼片长(cm)', '萼片宽(cm)', '花瓣长(cm)', '花瓣宽(cm)']]
# 提取训练数据的目标列
train_Y = train_data[['类型_num']]
from sklearn.linear_model import LogisticRegression
# 创建逻辑回归模型
model = LogisticRegression()
# 使用训练数据拟合模型,即进行训练
model.fit(train_X, train_Y)
# 对测试数据进行预测
train_predictions = model.predict(test_X)
# 打印训练数据的预测结果
print(train_predictions)
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] # 指定默认字体为中文字体
plt.rcParams['axes.unicode_minus']=False # 解决负号'-'显示为方块的问题
# 创建散点图,横坐标为训练数据的"萼片长(cm)",纵坐标为训练数据的"萼片宽(cm)",颜色由预测结果决定
plt.scatter(train_X['萼片长(cm)'], train_X['萼片宽(cm)'], c=train_predictions)
# 添加横坐标标签
plt.xlabel('萼片长(cm)')
# 添加纵坐标标签
plt.ylabel('萼片宽(cm)')
# 添加图表标题
plt.title('鸢尾花分类结果')
# 显示图表
plt.show() 输出结果: ![]()
与测试数据对比,预测结果大致符合,训练效果不错。
五 、优缺点
优点:
(1)训练速度较快,分类的时候,计算量仅仅只和特征的数目相关
(2)简单易理解,模型的可解释性非常好,从特征的权重可以看到不同的特征对最后结果的影响
(3)适合二分类问题,不需要缩放输入特征
(4)内存资源占用小,因为只需要存储各个维度的特征值
缺点:
(1)不能用Logistic回归去解决非线性问题,因为Logistic的决策面试线性的
(2)对多重共线性数据较为敏感
(3)很难处理数据不平衡的问题
(4)准确率并不是很高,因为形式非常的简单(非常类似线性模型),很难去拟合数据的真实分布















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









