






一、朴素贝叶斯介绍
1.介绍
贝叶斯公式又被称为贝叶斯规则,是概率统计中的应用所观察到的现象对有关概率分布的主观判断(先验概率)进行修正的标准方法,即在已知相关条件的情况下,一个事件的概率如何被计算。
朴素贝叶斯算法是建立在贝叶斯定理的基础上的一种分类算法。朴素贝叶斯算法使用贝叶斯定理来计算给定某一类别的情况下,每个特征的条件概率,并将这些条件概率相乘得到属于某一类别的后验概率。然后,选择具有最高后验概率的类别作为预测结果。
朴素贝叶斯算法中的“朴素”指的是对每个特征之间的条件独立性做出的假设。这个假设是指在给定类别的情况下,每个特征之间都是相互独立的,即一个特征的出现与其他特征的出现无关。
2.计算
先验概率:先验概率是指在没有任何其他信息的情况下,我们对某个事件的概率的初始估计。如: P(A)是A的先验概率,P(B)是B的先验概率。
后验概率:后验概率是指在考虑了新的信息或证据之后,对某个事件的概率进行更新或修正的概率。如:P(A|B)是A的后验概率,P(B|A)是B的后验概率。
条件概率: 在概率论中,条件概率是指在给定另一个事件已经发生的条件下,某一事件发生的概率。如P(A|B)为已知B成立/发生时,A成立/发生的概率。
贝叶斯公式:基于条件概率的定义和乘法规则,提供了一种从后验概率反推先验概率的方法。如下
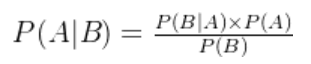
也可以是这种形式

朴素贝叶斯:朴素贝叶斯算法假设所有的特征都是相互独立的。这意味着给定类别的情况下,每个特征对于分类的贡献是独立的。所以一个类别的条件概率为多个特征下这个类别的条件概率的乘积,即![]()
而朴素贝叶斯算法:![]() 会计算该样本属于每个类别的后验概率,并选择具有最高后验概率的类别作为分类结果。
会计算该样本属于每个类别的后验概率,并选择具有最高后验概率的类别作为分类结果。
二、代码实例
根据颜值(A),身材(B),性格(C),收入(D),学历(E)判断相亲的两人是否交往(R)。
import math
class NaiveBayesClassifier:
def __init__(self):
self.probabilities = None
def train(self, data):
# 计算先验概率
success_count = sum(1 for item in data if item[-1] == '成功')
failure_count = sum(1 for item in data if item[-1] == '失败')
total_count = len(data)
success_prob = success_count / total_count
failure_prob = failure_count / total_count
self.probabilities = {'success': success_prob, 'failure': failure_prob}
# 计算每个特征的后验概率
features_count = len(data[0]) - 1
for i in range(features_count):
feature_prob = {'success': {}, 'failure': {}}
feature_values = set(item[i] for item in data)
for value in feature_values:
success_value_count = sum(1 for item in data if item[i] == value and item[-1] == '成功')
failure_value_count = sum(1 for item in data if item[i] == value and item[-1] == '失败')
feature_prob['success'][value] = success_value_count / success_count
feature_prob['failure'][value] = failure_value_count / failure_count
self.probabilities[chr(ord('A') + i)] = feature_prob
def predict(self, features):
if self.probabilities is None:
print("请先训练模型")
return
success_prob = self.probabilities['success']
failure_prob = self.probabilities['failure']
for feature, value in features.items():
# 获取当前特征值对应的后验概率,如果特征值不存在,则采用拉普拉斯平滑
success_prob *= self.probabilities[feature]['success'].get(value, 0.01)
failure_prob *= self.probabilities[feature]['failure'].get(value, 0.01)
# 加上对数概率,避免数值下溢
success_prob = math.log(success_prob)
failure_prob = math.log(failure_prob)
if success_prob > failure_prob:
return "成功"
else:
return "失败"
def main():
# 数据集
data = [
['不错', '一般', '不错', '不错', '不错', '成功'],
['一般', '不错', '不错', '不错', '不错', '成功'],
['不错', '一般', '不错', '不错', '一般', '成功'],
['不错', '不错', '一般', '不错', '不错', '成功'],
['不错', '不错', '不错', '一般', '一般', '成功'],
['一般', '一般', '一般', '不错', '不错', '成功'],
['一般', '一般', '一般', '不错', '不错', '失败'],
['一般', '一般', '不错', '不错', '不错', '失败'],
['一般', '一般', '一般', '一般', '一般', '失败'],
['不错', '一般', '一般', '一般', '不错', '失败'],
['一般', '一般', '不错', '不错', '不错', '失败'],
['一般', '不错', '一般', '不错', '不错', '失败'],
['不错', '不错', '不错', '不错', '一般', '失败'],
['不错', '不错', '不错', '一般', '一般', '失败'],
['不错', '不错', '不错', '不错', '不错', '失败']
]
# 创建朴素贝叶斯分类器
classifier = NaiveBayesClassifier()
# 训练模型
classifier.train(data)
# 要测试的特征
test_features = {
'A': '不错',
'B': '一般',
'C': '不错',
'D': '不错',
'E': '不错'
}
# 输出预测结果
prediction = classifier.predict(test_features)
print("根据特征预测的结果是:", prediction)
if __name__ == "__main__":
main()
三、总结
1.优点
- 简单有效: 朴素贝叶斯算法实现简单,易于理解和实现。
- 高效性: 计算速度快,适用于大规模数据集。
- 适用性广泛: 在实践中表现良好,适用于文本分类、垃圾邮件过滤、情感分析等多个领域。
2.缺点
- 假设独立性: 朴素贝叶斯算法假设所有特征之间相互独立,但在实际问题中很少有特征是完全独立的,这可能导致模型偏差。
- 对数据分布敏感: 当数据的分布偏离朴素贝叶斯的假设时,分类器的性能可能会受到影响。
- 处理连续数据不佳: 对于连续型数据,朴素贝叶斯假设特征的概率分布为离散型,这可能导致信息损失。
3.应用场景
- 文本分类: 朴素贝叶斯在文本分类领域表现出色,如垃圾邮件过滤、情感分析等。
- 推荐系统: 可用于个性化推荐系统中,对用户喜好进行建模和预测。
- 医学诊断: 朴素贝叶斯在医学领域中用于疾病诊断和预测患者风险。
- 金融风控: 可用于信用评分、欺诈检测等领域,对风险进行建模和预测。















 825
825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









