






一、支持向量机原理
1.1概述
支持向量机(SVM)是一种监督学习算法,其基本原理在于寻找一个能够将不同类别的数据点有效分隔开的最优超平面。具体来说,SVM的目标是找到一个超平面,使得离该超平面最近的数据点(称为支持向量)到这个超平面的距离最大化。通过最大化分类间隔,SVM能够提供更好的泛化性能,即对新样本的分类效果更可靠。在处理非线性分类问题时,SVM利用核技巧将输入数据映射到高维特征空间,使得原本非线性可分的问题变成线性可分的问题。这样,SVM可以在高维空间中找到一个最优超平面,从而实现对不同类别数据点的有效分隔。
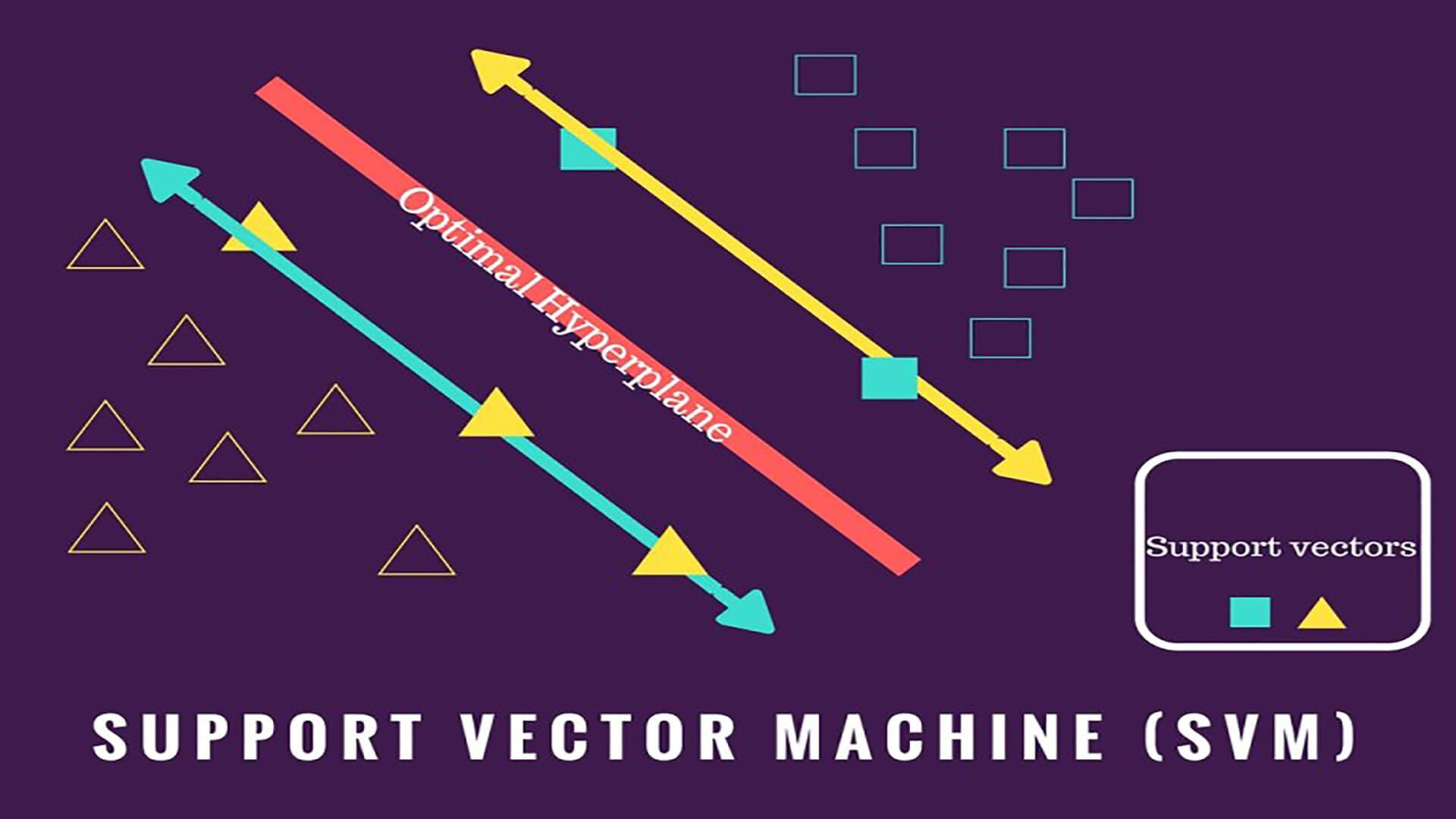
支持向量:在支持向量机(SVM)中,支持向量是指训练数据集中距离超平面最近的那些数据点。这些数据点对确定超平面具有重要影响,因为它们决定了超平面的位置和方向。换句话说,支持向量是决定分类器决策边界的关键要素。
超平面:
(w) 是超平面的法向量(也称为权重向量),它的方向与超平面的法线方向相同,长度表示超平面到原点的距离,(x) 是输入样本的特征向量,(b) 是偏置项。
这个方程描述了特征空间中的一个超平面,对于给定的输入样本 (x),当 时,样本被分类为一类;当
时,样本被分类为另一类。
定义了超平面本身。
1.2寻求最大间隔
1.定义问题
给定一个训练数据集
,其中
是特征向量,
是类别标签(1 或 -1),我们的目标是找到一个超平面
,使得对于所有的 i,都满足
。
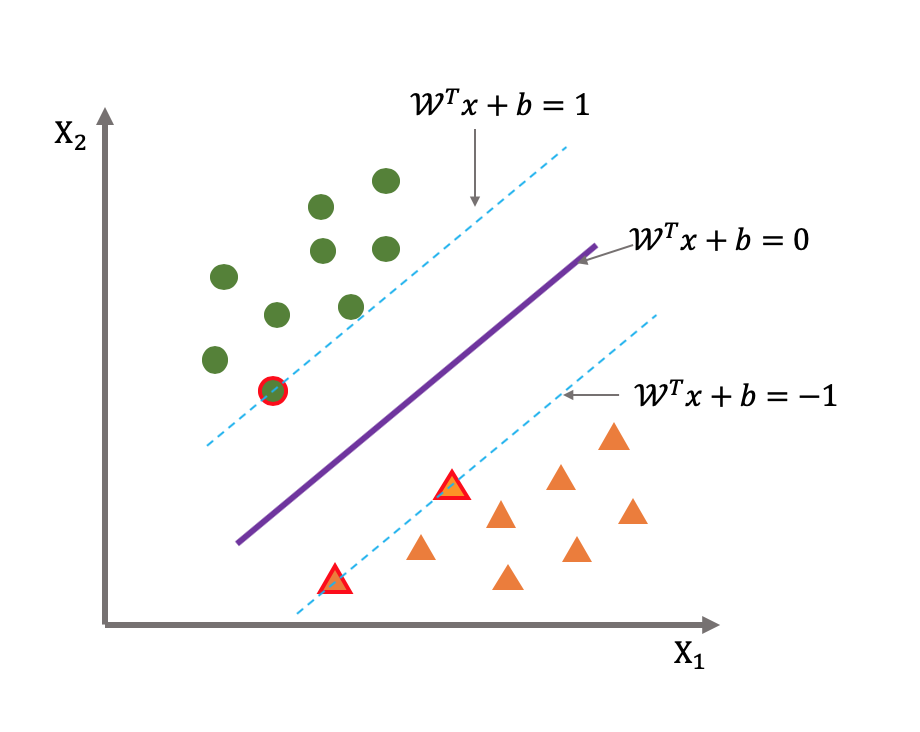
2.间隔
在支持向量机中,间隔是指超平面到最近的训练样本点的距离。对于线性可分的情况,最大间隔超平面的间隔是所有训练样本点到超平面的距离中的最小值。
为了求解最大间隔,我们可以考虑超平面上的两个支持向量,记为
和
,它们满足
和
。这两个方程的几何意义是超平面与支持向量的距离是相等的,且这个距离等于间隔的一半。因此,我们可以计算间隔为:
因此,最大间隔的问题可以转化为最小化
的问题,而约束条件为
3. 对偶问题
为了解决带约束的优化问题,我们引入拉格朗日乘子
来构建拉格朗日函数。拉格朗日函数如下:
接下来,我们要最小化
关于 (w) 和 (b) 的极小值,并最大化它关于
的极大值。
对
将上述结果代入拉格朗日函数后,我们得到对偶函数
:
其中,等式满足
和
这个问题可以通过一些优化算法(如SMO)来求解。通过找到最大化
,我们可以得到最优的拉格朗日乘子。
4.最大间隔
一旦我们求解出最优的拉格朗日乘子
其中,(j) 是任何一个支持向量的索引。
通过计算权重向量 (w) 和偏置项 (b),我们可以得到最大间隔超平面的参数。这个超平面可以通过支持向量决定,它们对应于满足 的训练样本。最终,我们可以使用这个超平面来进行分类。
1.3软间隔
概念
软间隔是支持向量机(SVM)中的概念,它允许在训练数据中存在一些噪声或异常值的情况下,仍然能够有效地进行分类。软间隔的引入使得支持向量机对于非线性可分的数据集也能有很好的泛化能力。
在介绍软间隔之前,让我们先来回顾一下硬间隔。在硬间隔支持向量机中,假设训练数据是线性可分的,即存在一个超平面能够将正负样本完全分开。这时,支持向量机的目标是找到能够最大化类别间隔(即两个类别样本点到超平面的最小距禿)的超平面。
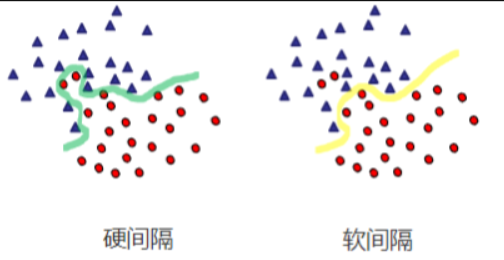
然而,在现实应用中,训练数据往往不是完全线性可分的,可能存在一些噪声或异常值。这时候就引入了软间隔的概念。软间隔允许一些样本点位于超平面的错误一侧,但是通过引入惩罚项来平衡分类间隔和误分类点的数量。
原理
软间隔支持向量机通过引入惩罚项 (C) 来控制间隔的大小和误分类点的数量。这个惩罚项可以被看作是对误分类点的成本,它决定了对误分类的容忍程度。参数 (C) 越大,意味着对误分类的惩罚越严厉,模型会更倾向于选择更小的间隔以减少误分类点的数量;参数 (C) 越小,意味着对误分类的惩罚越宽松,模型会更倾向于选择更大的间隔而容忍更多的误分类点。
软间隔支持向量机的优化问题包括最小化间隔大小和最小化误分类点数两个方面。其目标函数可以表示为:
其中,
代表第 (i) 个样本点的误分类程度,(C) 是惩罚参数。该优化问题是一个凸优化问题,可以通过拉格朗日对偶问题和SMO算法来求解。
总结来说,软间隔支持向量机通过引入惩罚项来平衡间隔的大小和误分类点的数量,使得支持向量机能够更好地适应现实中的复杂数据集,并具有更好的泛化能力。
1.4核函数
概念
核函数是支持向量机(SVM)中的一个重要概念,它可以将输入空间中的非线性问题映射到高维特征空间中的线性问题,从而使得原本线性不可分的问题变得线性可分。这样一来,支持向量机就可以在高维特征空间中找到一个最优的超平面来进行分类。
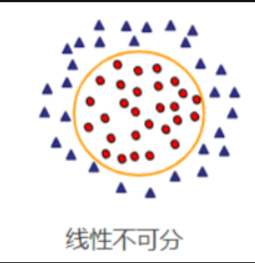
核函数实际上是一个函数,它可以计算两个向量之间的内积。在支持向量机中,核函数的作用是隐式地将数据映射到一个更高维的特征空间,而无需显式地计算出映射后的特征向量。这样做的好处是可以避免在高维空间中进行昂贵的特征映射操作,同时有效地利用内积计算来实现对应的非线性分类和回归任务。
常见核函数
线性核函数(Linear Kernel):
。线性核函数对应于原始输入空间,适用于线性可分的情况。
多项式核函数(Polynomial Kernel):
。多项式核函数引入了多项式项,其中 (c) 是常数项,(d) 是多项式的次数。
高斯核函数(Gaussian Kernel/RBF Kernel):
。高斯核函数通过指数映射将数据映射到无穷维的特征空间,可以处理非线性可分的情况。
Sigmoid核函数(Sigmoid Kernel):
。Sigmoid核函数可以实现数据的非线性映射。
优势和应用
处理非线性问题:核函数可以很好地处理非线性问题,将数据映射到高维空间中进行线性划分。
节省计算成本:通过核函数,可以避免直接计算高维空间的内积,节省了计算成本。
适用性广泛:核函数不仅可以应用于支持向量机,还可以应用于其他机器学习算法中,如核主成分分析(Kernel PCA)等。
二、代码实现
基于datasets.make_classification 函数生成的一个简单二维数据集使用svm对其进行分类
2.1代码
# 导入所需的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 创建一个简单的二维数据集
X, y = datasets.make_classification(n_samples=300, n_features=2, n_classes=2, n_clusters_per_class=1, n_redundant=0, random_state=42)
# 数据预处理
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
# 创建 SVM 模型并进行训练
svm_model = SVC(kernel='linear', random_state=42)
svm_model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = svm_model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
# 绘制决策边界
def plot_decision_boundary(X, y, model, title):
h = .02 # 网格中的步长
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k')
plt.title(title)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
# 绘制决策边界
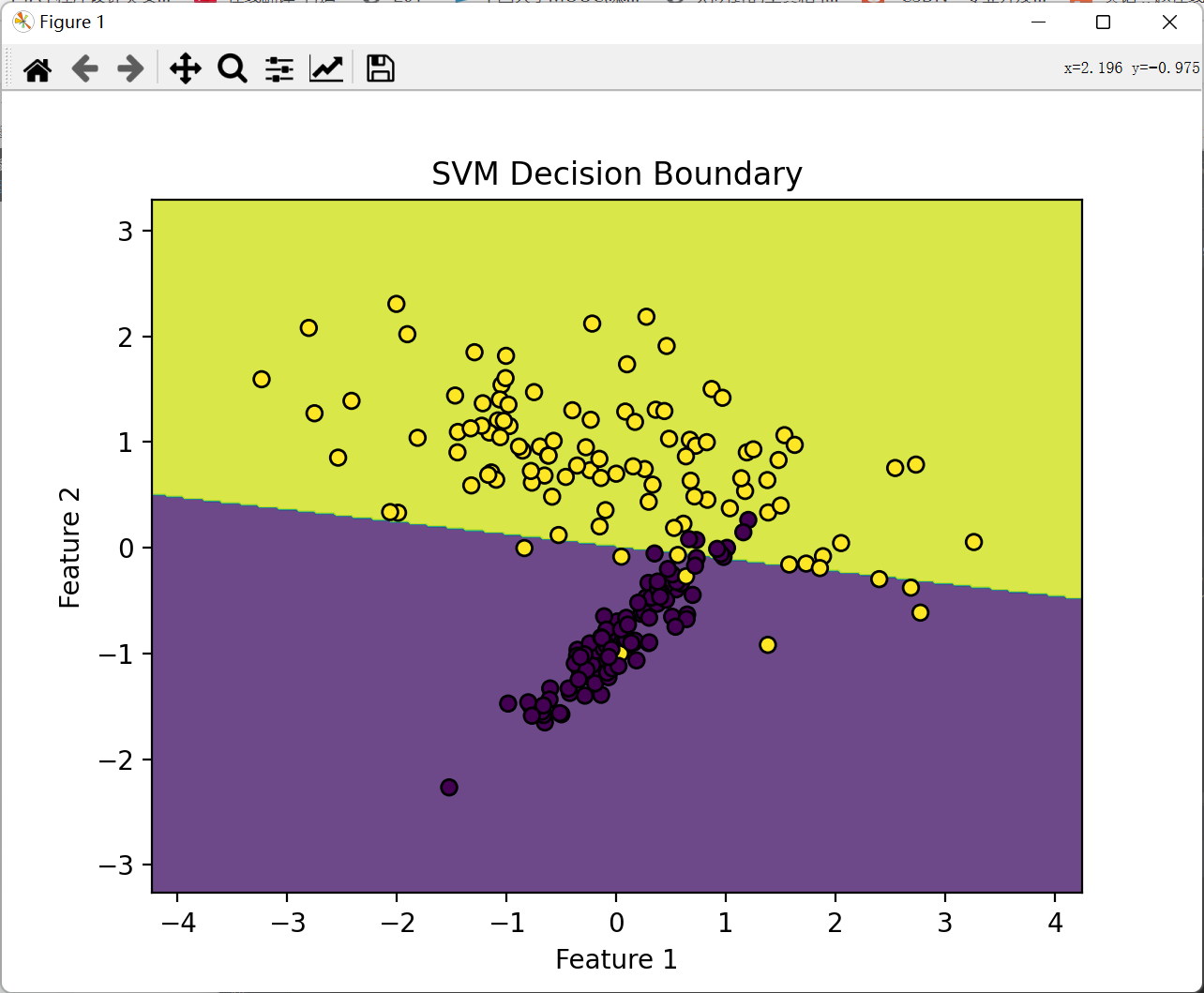
plot_decision_boundary(X_train, y_train, svm_model, "SVM Decision Boundary")
2.2运行结果
![]()
三、优缺点
3.1优点
- 有效处理高维数据:SVM 在高维空间中表现出色,适用于特征维度较高的数据集,比如文本分类、图像识别等领域。
- 可有效处理非线性问题:通过选择合适的核函数(如多项式核、高斯核等),SVM 能够很好地处理非线性分类问题。
- 泛化能力强:SVM 在面对小样本数据集时仍然具有较好的泛化能力,能够避免过拟合的问题。
- 最大化间隔:SVM 通过寻找最大间隔超平面来进行分类,具有较好的稳健性,能够更好地适应新样本的分类。
3.2缺点
- 对大规模数据集计算开销较大:SVM 在处理大规模数据集时需要大量的计算时间和内存空间。
- 需要选择合适的核函数和参数:选择不合适的核函数或参数可能导致分类性能下降,需要进行反复调参。
- 对缺失数据敏感:SVM 对缺失数据较为敏感,需要对数据进行充分处理确保数据的完整性。
- 难以解释模型结果:SVM 生成的模型比较复杂,难以直观解释其分类决策的依据。















 3393
3393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









