






原理就是用小数据集的yolo权重识别大数据集,并导出标注文件,用x-anylabeling进行检查和修改
1.下载X-anylabeling
在解压后文件夹打开终端,并安装所需的环境依赖:
pip install -r requirements.txt
如果下载速度缓慢,可以临时使用清华源下载
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
安装完成后在项目终端运行app.py
python anylabeling/app.py2. 在yolov5里使用小部分数据集训练模型,并将模型在更大的数据集里进行测试(关键)

此处我们根据几十张手动标注的少量数据集来训练好了 权重文件。并将source地址选为大量数据集的那个地址
将第十行参数修改为store_false,训练更大的数据集,得到的模型会生成标签文件和带有识别框的源文件。此处我们需要的是这个标签文件。
3.打开X-labeling进行标注
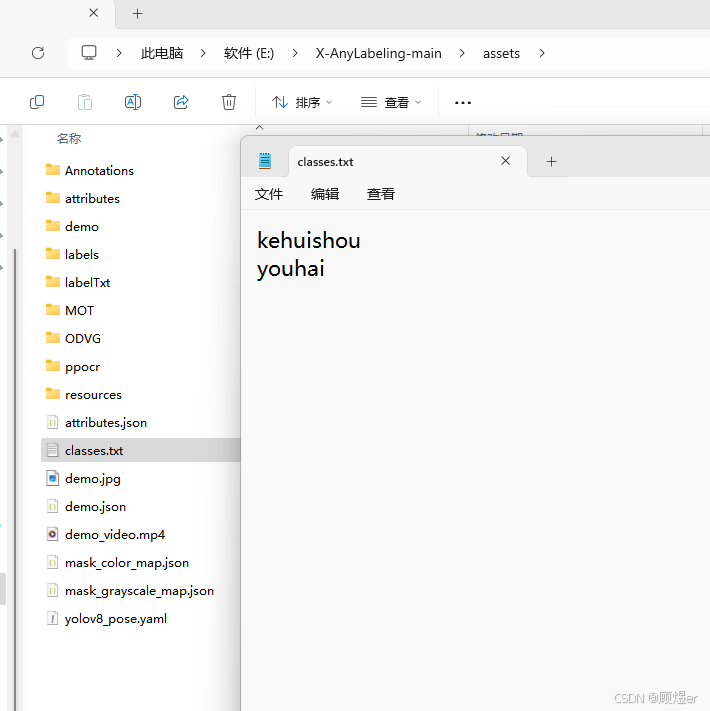
首先在X-AnyLabeling-main\assets文件夹下找到classes.txt文件,并将文件修改为自己的识别标签,注意顺序。(也可以自己创建一个classes.txt文件,按顺序输入标签名即可)
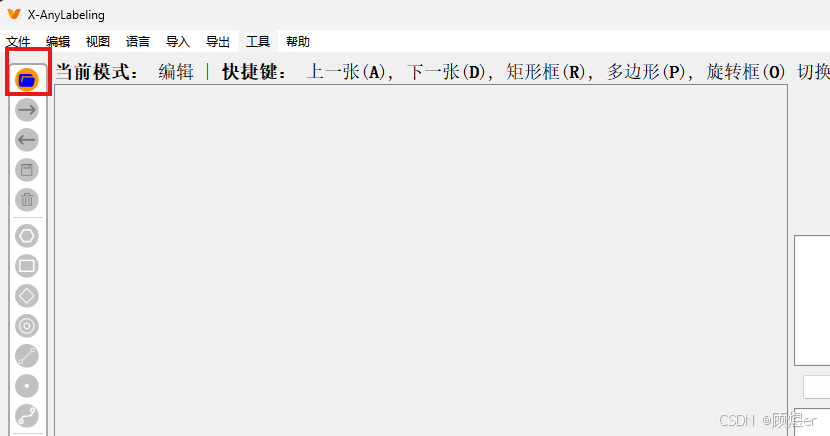
首先导入图片
选择刚才的yolov5测试集地址也就是大量数据集的那个地址(source地址)导入图片

选择输出目录
之后点击导入-导入yolo水平框标签,导入刚才的classes.txt文件和yolov5识别生成的标签文件
classes.txt
labels文件
选择覆盖。
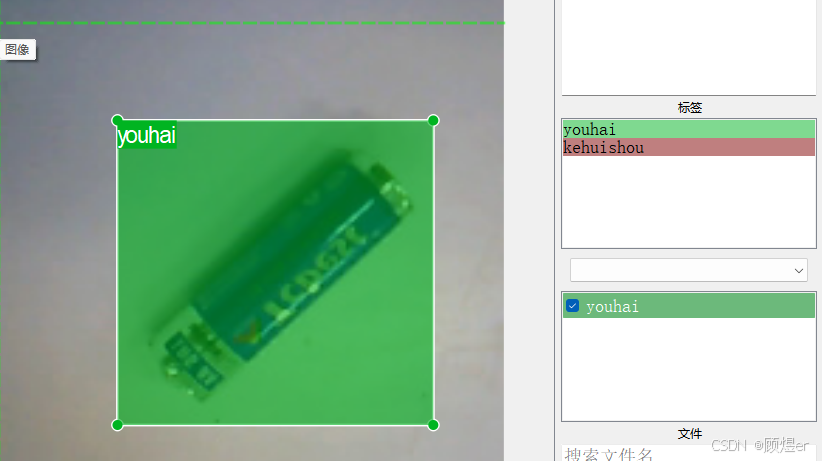
这样便由少数据集训练结果在大量数据集上打好了标签,之后查找标签错误的文件进行修改即可
导出标签:
点击导出yolo水平标签

同样选择classes.txt文件
导出标签文件即可



















 3378
3378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











