






1.安装labelimg,使用labelimg工具对图片进行标注
安装:
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
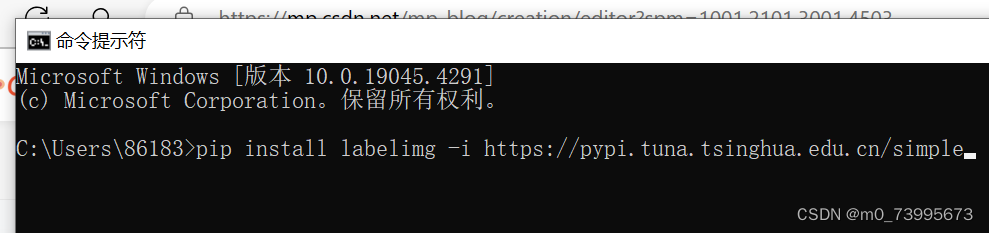
运行:
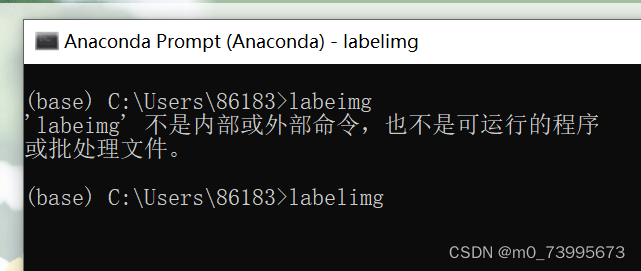
2.数据集处理
将训练数据集准备的图片放入yolov4-pytorch-master\VOCdevkit\VOC2007\JPEGImages中后,在labelimg中打开JPEGImages目录,对图片进行标注。本次我标注的图片共100张。
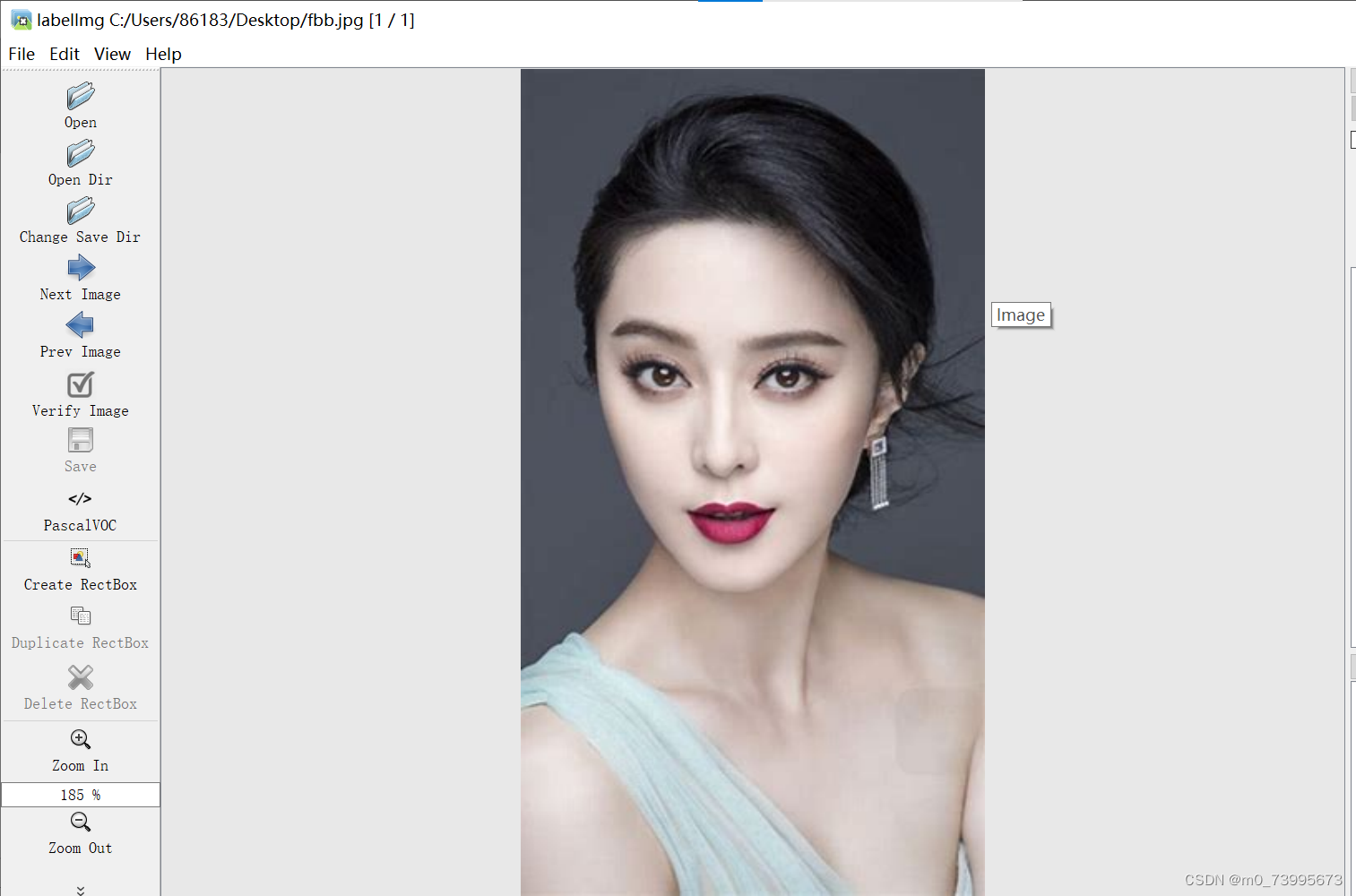
标注好后将标签放入目录yolov4-pytorch-master\VOCdevkit\VOC2007\Annotations中
训练自己的数据集,可以自己建立一个face_classes.txt,里面写自己所需要区分的类别。
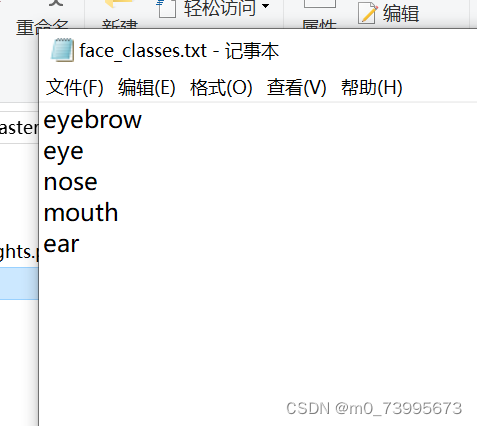
比如我model_data/face_classes.txt文件的内容为:
修改voc_annotation.py中的classes_path,使其对应cls_classes.txt,并运行voc_annotation.py。
3. 开始网络训练
去train.py中修改classes_path,classes_path用于指向检测类别所对应的txt,这个txt和voc_annotation.py里面的txt一样!
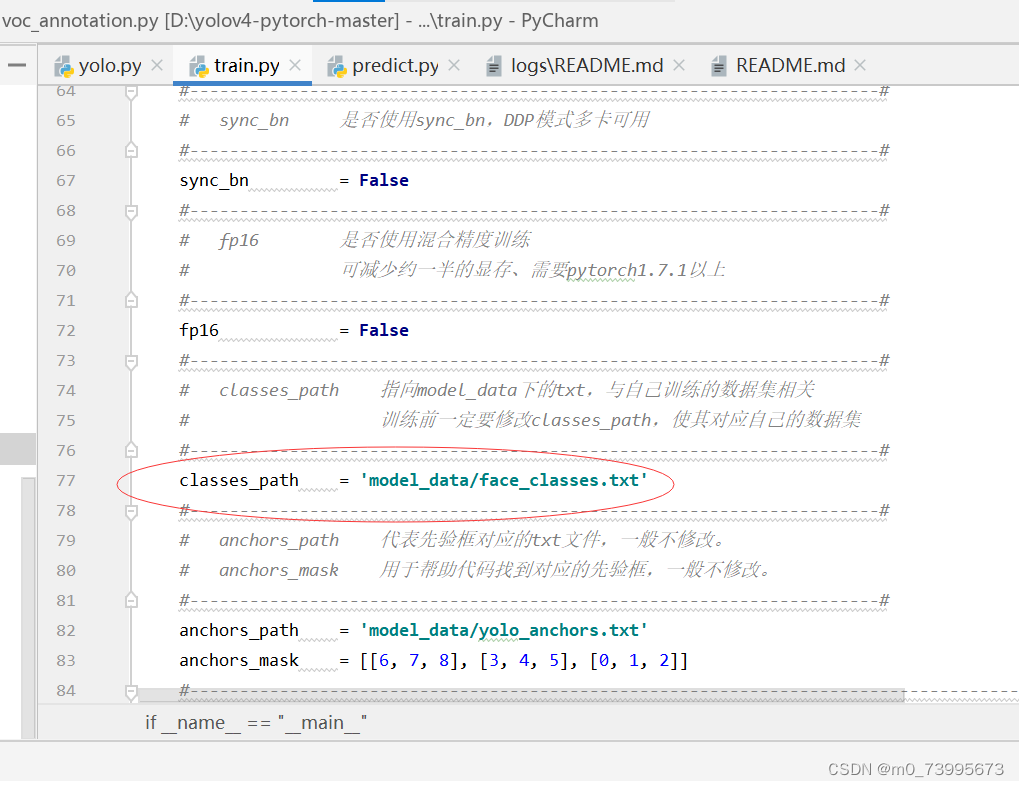 修改完classes_path后就可以运行train.py开始训练了,在训练多个epoch后,权值会生成在logs文件夹中。
修改完classes_path后就可以运行train.py开始训练了,在训练多个epoch后,权值会生成在logs文件夹中。
4. 训练结果预测
训练结果预测需要用到两个文件,分别是yolo.py和predict.py。在yolo.py里面修改model_path以及classes_path。model_path指向训练好的权值文件,在logs文件夹里。 classes_path指向检测类别所对应的txt。
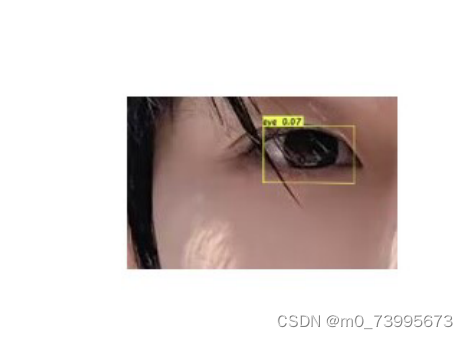
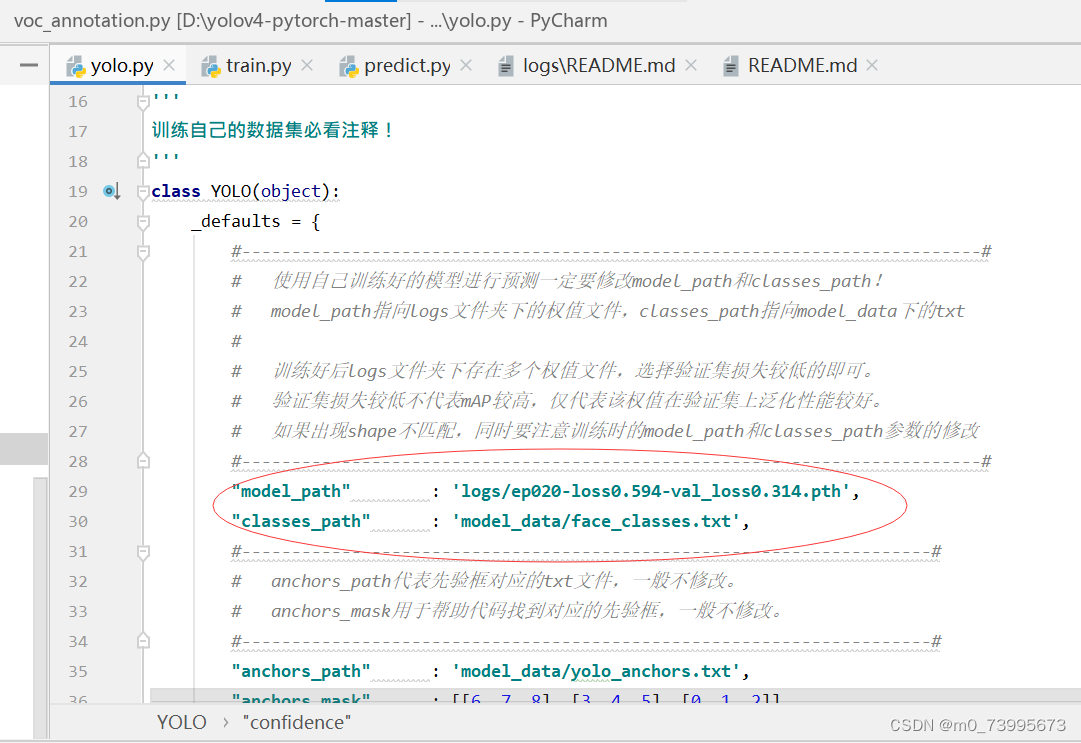 完成修改后就可以运行predict.py进行检测了。运行后输入图片路径即可检测。
完成修改后就可以运行predict.py进行检测了。运行后输入图片路径即可检测。
















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









