







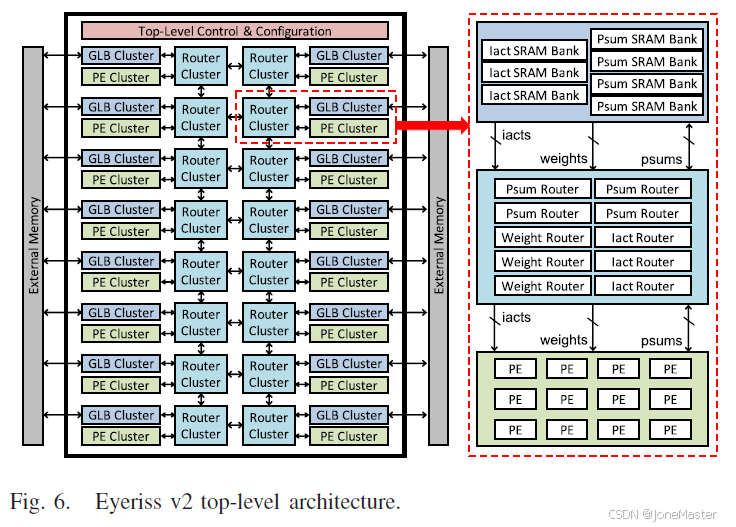
本章节我们继续接着上一章的内容讲解具体的模块和片上网络分析。
灵活的分层片上网络
支持紧凑dnn所需的关键特性之一是一个灵活高效的片上网络(NoC)。本节会提供并描述了如何配置NoC用于各种用例。
作者提出NoC是神经网络加速器中重要的一部分,需要考虑如下几个设计原则:
(1)支持高并行性的处理通过在存储和数据路径之间有效地传递数据
(2)利用数据复用来降低带宽需求并提高能源效率
(3)可以调整的规模以控制性能与成本。
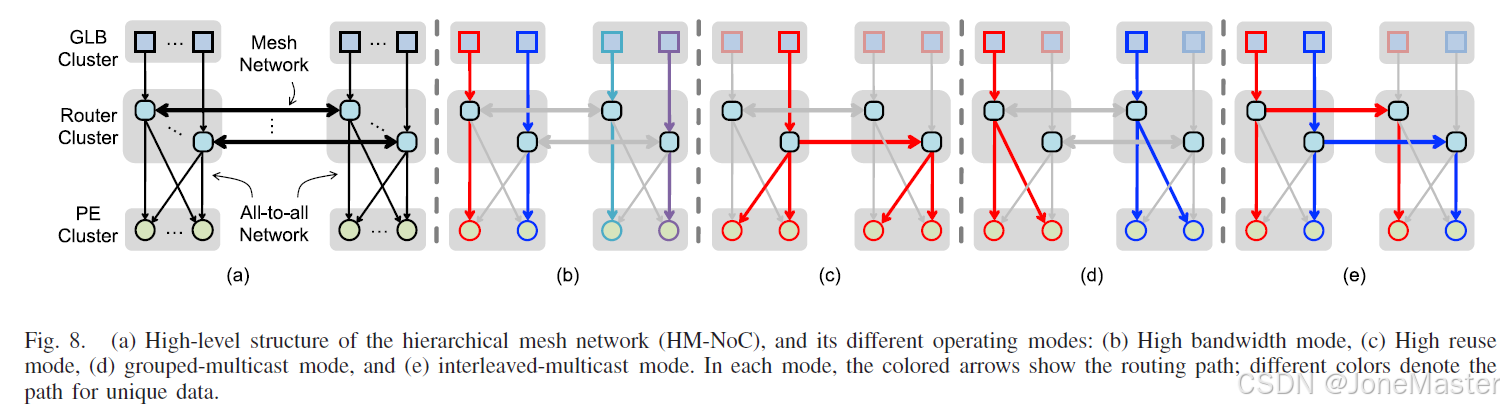
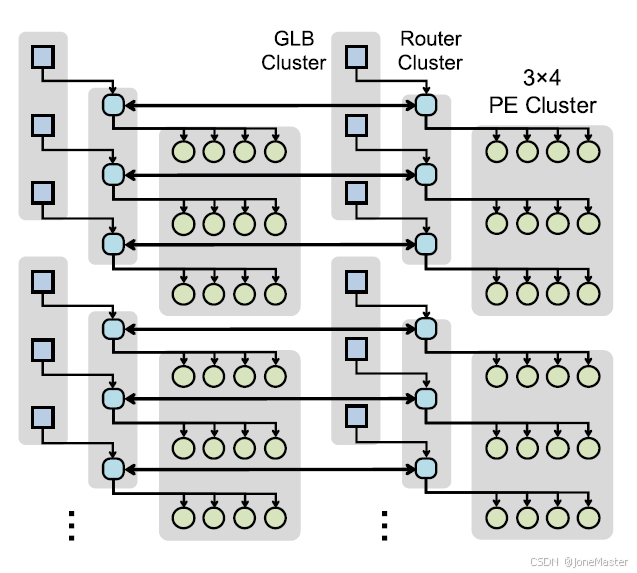
图中展示的是本文中所设计的片上网络,称为HM-NoC。 根据作者的描述,对于神经网络加速器来说,数据复用有很多困难,尤其是对于稀疏型数据。因为在复用时必须考虑到数据长宽是否符合,这让很多时候数据重用是很困难的。针对这个问题,作者提出的层次结构网状网络(HM-NoC)在网络的低层级使用全对全网络(All-to-All)在高层级使用单向连接,保证了网络的灵活性和在拓展网络时资源消耗较少(线性增加)。
具体来说,我们看上图最左边的(a),可以看出只有Router Cluster和PE Cluster之间的连接使用了全对全连接,而在GLB Cluster 和Router Cluster之间、以及两组Router Cluster之间(不同计算阵列之间只通过Router Cluster连接,这在上面的顶层图可以看出来,方便数据复用)使用的是单对单连接。当需要拓展网络时,只需要把这个最小单元复制一份连接起来即可,新增的连线是线性的,而不是指数级的。注意在这里为了简化,PE Cluster中只画了2个PE单元,但实际上在这篇文章的设计中是3×4=12个PE单元,这在上一章中已经介绍了。
上图中(b)(c)(d)(e)介绍了4种方式下的网络连接方式。
•在高带宽模式下(图b),每个GLB bank或片外数据I/O可以独立地将数据发送到集群中的pe,实现单播。
•在高重用模式下(图c),来自相同的数据source可以路由到不同集群的所有pe
实现了广播。
•用于数据重用不能充分利用的情况整个PE阵列广播,不同的多播模式,特别是分组组播(图d)和交错组播(图e),可根据所需的多播模式。
要理解这样的复用方式,我们先要理解在计算过程中有两个瓶颈,分别是计算瓶颈和内存瓶颈,实际上在实际应用中内存瓶颈带来的数据流速度过慢已经远超计算瓶颈成为制约计算速度的最关键因素。每一次从内存中取出数据都需要一定的周期,我们举例来说:
假设我们现在输入特征图为28×28,每个像素点数据是8bit,我们使用数据位宽为8的带宽取出数据,也就是说每次可以取出一个数据。当我们需要使用5×5的卷积核进行卷积计算时,我们至少需要先得到前4行的数据。这意味着我们需要把这些数据从内存中取出来至少需要112个周期,这远超计算所需的周期,而这个情况会随着输入特征图变大而加剧。同样的,从内存中反复读取也会导致更高的能耗。
如果我们能够从内存中读取一次数据后进行多次计算,这可以有效避免内存瓶颈,这就是我们提到的数据复用。以上图中(c)为例,可以看到1个GLB中的数据发给了4个PE(它通过Router Cluster同时发给了旁边另一个计算阵列的PE)这意味着减少了至少3次内存读写。而随着PE和发送的阵列增加,复用程度也会进一步增加。
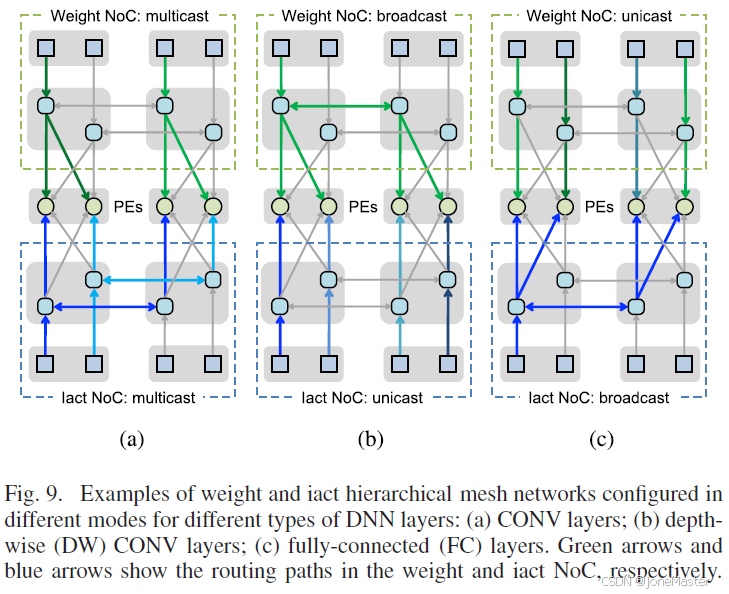
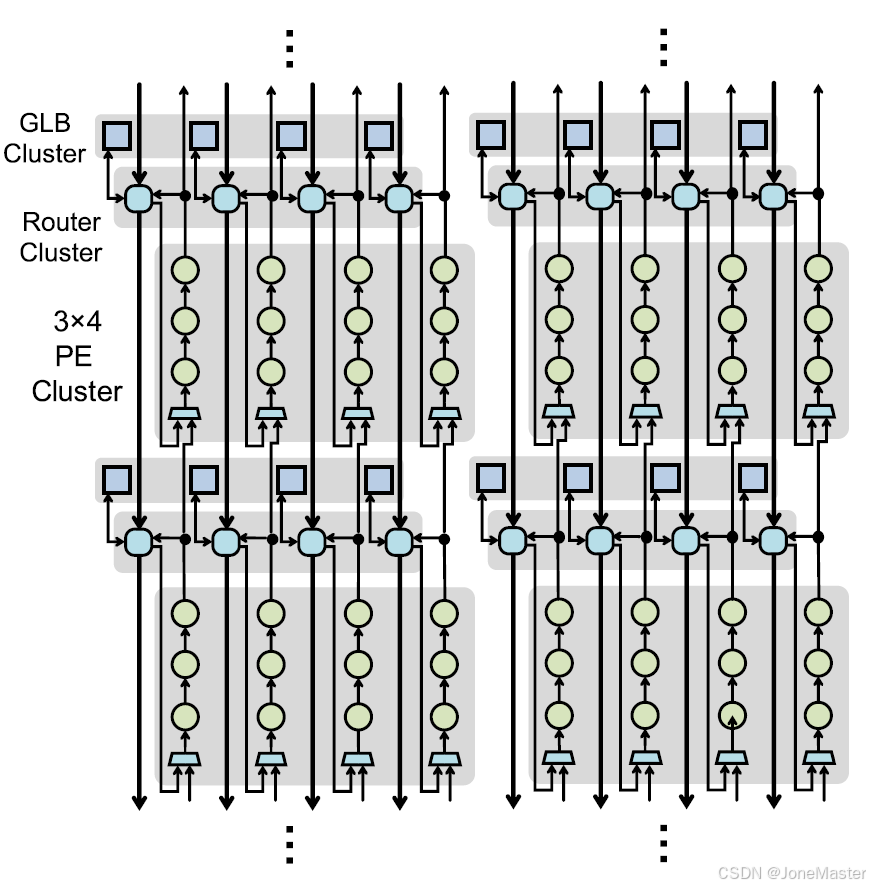
这张图展示了在具体的神经网络的某一层中如何进行数据复用。 回顾一下,GLB Cluster中对应于Weight并没有实际的存储空间,相当于仅仅是数据流动经过,而Iact是有独立的存储空间的。GLB Cluster的数据都发送给Router,这是数据复用主要起到作用的模块。
图(a)是常规卷积层,权重被配置成单组组播(在一个计算阵列内,权重相同;在相邻的计算阵列内,权重不同)而输入被配置成跨组组播(将2组输入分配在相邻的两个计算阵列内,每组输入都与两组权重相乘)
图(b)是深度卷积层,由于DP层难以进行输入数据重用,但权重数据可以重用。所以对于每个PE都有独立的输入和相同的权重,权重网络被配置为广播,输入网络被配置为单播。
图(c)是全连接层,全连接层几乎不会重用权重,但会重用输入数据。这时权重被配置为单播,输入数据被配置为广播。
接下来我们回顾一下前面的表格,以进一步介绍针对Iact,Weight和Psum的网络结构。

注意观察,PE阵列是3×4排列的,而Router Cluster中包含3个Iact Router,每个Iact Router包含4对输入/输出端口,也是3×4的。每个端口位宽是24位,允许输入3个8位数据或2个12位数据。Weight Router有3个,每个包含2对输入输出端口,每个端口也是24位。Psum Router有4个,每个包含3对输入输出端口,每个端口是40位,每个周期可以接收2个psum(前文已经提到,psum是20位的) 。
针对输入数据的HM-NoC
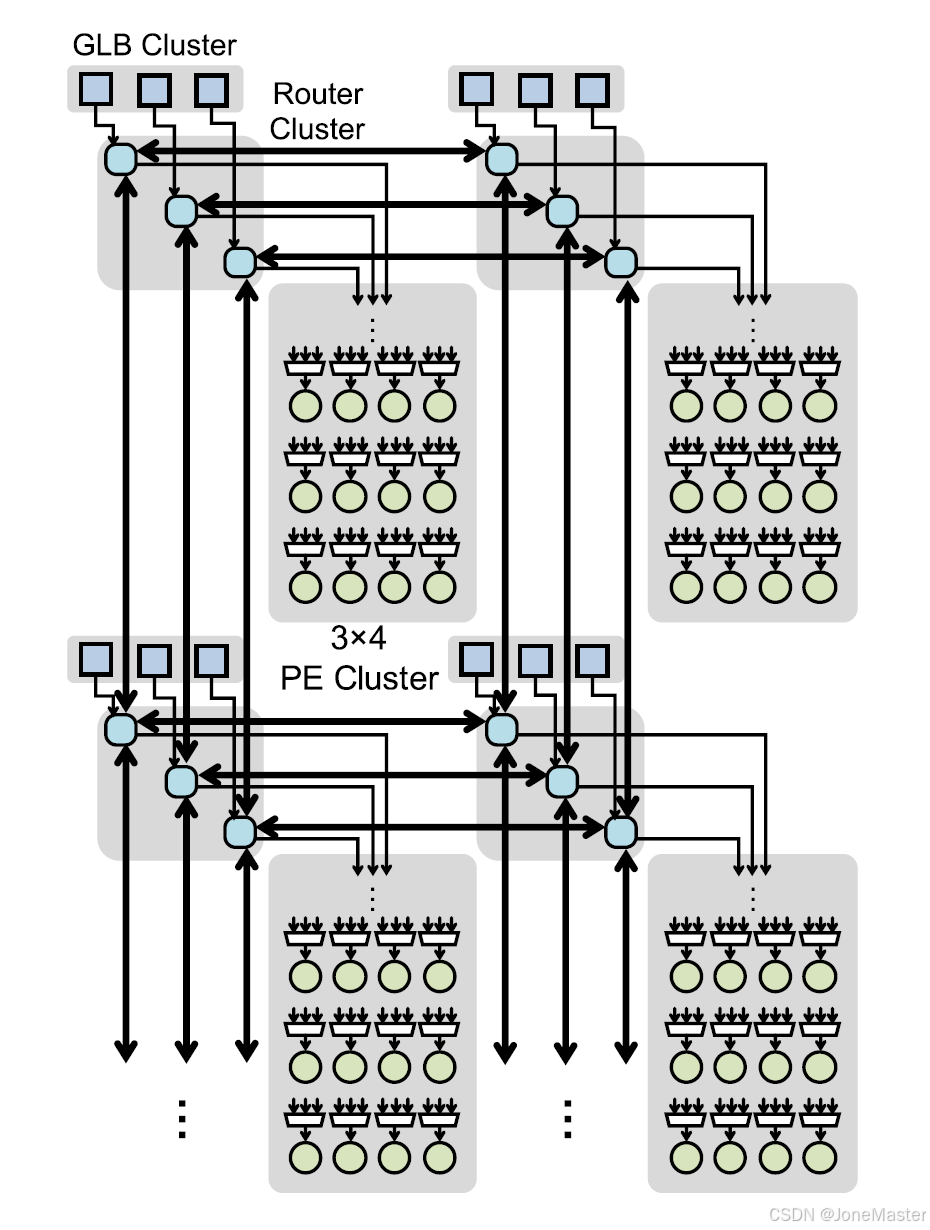
在上图中,中间的三个代表Router Cluster中的3个Iact Router,它有4对输入输出端口。其中3对端口与其他阵列的Router相连,如图中粗的黑线所示。另外一对输入输出端口,输入端口分配给GLB Cluster接收外界的输入数据,输出端口使用全对全连接至PE Cluster(每个Iact Router都与所有PE相连,每个PE有3个输入来源,进行仲裁选择后接收数据输入)。由此看出,Iact Router有4个数据来源,分别是GLB、上方阵列、水平方阵列、下方阵列;有4个输出方向,分别是PE、上方阵列、下方阵列、水平阵列。
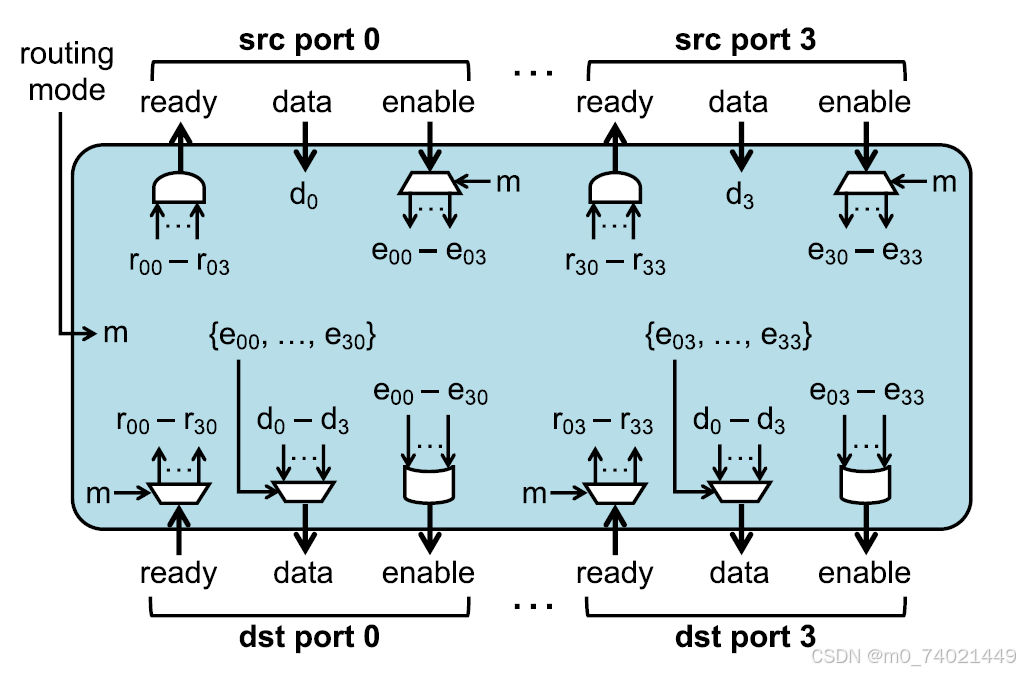
Iact Router的电路硬件示意图如上,4对输入输出端口,每个端口包含ready、enable握手信号和data数据信号。m信号是routing mode控制信号,它操控输入端的enable信号和输出端的ready信号,以控制从哪里获得源数据,将其发送到哪里。
注意观察:先从输入端口来看,看到输入端口0,e00-e03信号(第一个0是输入端口值,第二个0-3是输出端口值,如果是第二个端口则是e10-e13)受到外部enable信号和m信号控制,输入一个4位握手信号,如使能2号输出端口,则此端口信号是0100。每个输入端口都有一个4位enable信号,表示希望使能的输出端口。每次只有1个输入端口可以接收数据,因此如输出端口0,控制它的信号是e00-e30(代表输入端口0-3对输出端口0的控制信号),用它作为输出多路选择器的控制信号(控制d0-d3输出哪路数据),输出enable信号是e00-e30的或,只要有一个输入端口希望激活这个输出端口,这个输出端口就会被激活。相反地,由输出端口接收的外界ready信号,也会提供给每个输入端口,但在输入端口输出ready信号时做的是与操作,必须所有输出端口全部准备好,输入端口才能与外界握手。
针对权重的HM-NoC
相比Iact Router,Weight Router提供了组播,而非像输入激活一样的全对全连接。也就是说,PE阵列中一行的权重是一致的,每行之间的权重通过跨组复用控制。这对应于Weight Router有2对输入输出端口,一对用于跨组交换数据,一对输入分配给GLB,输出分配给PE。
针对Psum的HM-NoC
Psum的Router采取的是每一列PE对应一个单元。注意看图中,外界的Psum输入到PE阵列的最下方一个PE,在这里有一个多路选择器,控制接收Psum Router的数据还是下面一组PE向上传输的数据。Psum是部分和,是不断累加的过程。从最下方输入,累加一列中逐个PE的计算结果,循着路线向上流动,直到计算完成一列的部分和。分为两条路,一份传回给Psum Router,存入GLB Cluster中,一份继续向上流动到上方阵列。注意,只有Psum Router和GLB Cluster的交互是双向的,Iact和Weight都只会从GLB读入数据,而不会写入它。
可拓展性性能分析:
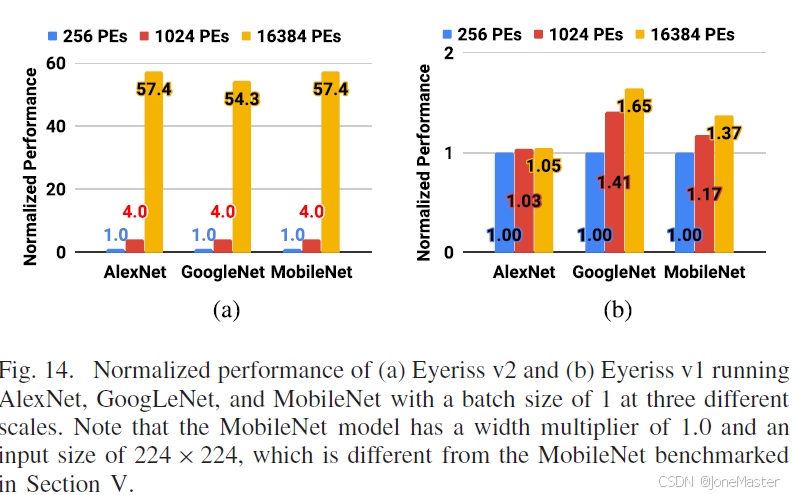
相比于Eyerissv1(图b),Eyerissv2获得了很好的线性拓展效果,PE阵列数目越多,计算表现越好。 作者表示,NoC网络带来了良好的可拓展性的同时,只有很少的资源消耗和能耗占比,资源消耗约占3%,能耗占比6%~10%。
本章内容就是这样啦,主要分析了Eyerissv2的片上网络结构,在下一章将会继续分析其重要的卷积压缩编码是如何实现的。

















 4878
4878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









