






一、定义
非极大值抑制(NMS),顾名思义就是抑制不是最大值的元素,在目标检测当中,就是提取置信度高的目标检测框,而抑制置信度低的框。一般来说,在模型输出到目标框的时候,目标框会非常多,其中有很多重复的框会定位到同一个目标上,NMS用来筛选掉多余的框,来获得真正的目标框。
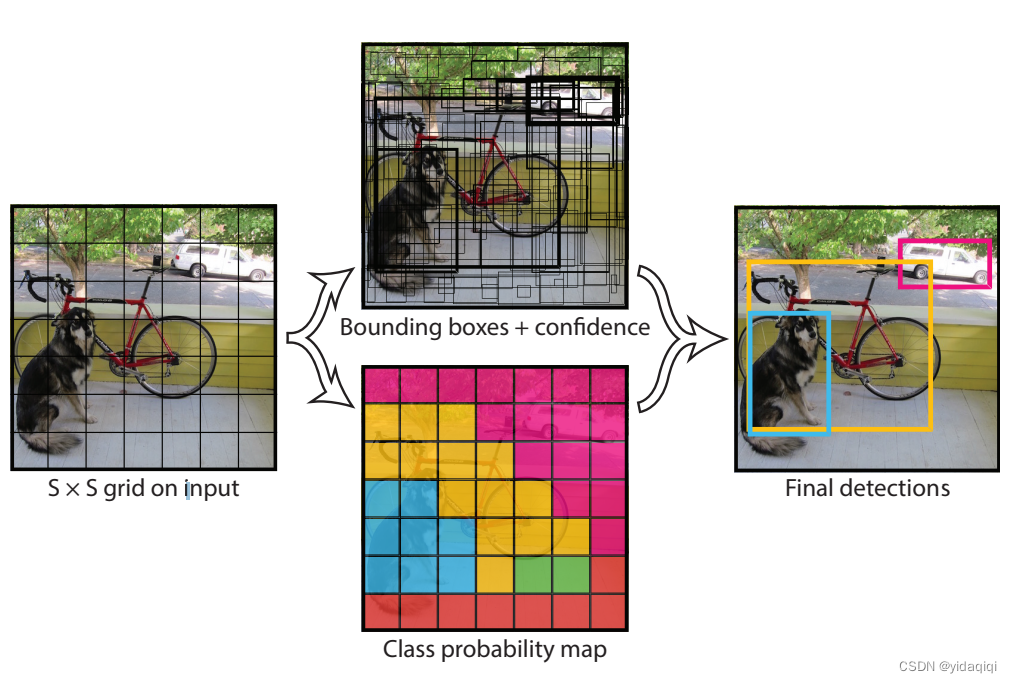
如下图,YOLOv1中使用到的NMS的过程,在模型预测后,会产生很多的框,经过NMS的处理,最后显示出的效果就非常的好。
该算法的作用就是要去除冗余的检测框,保留最好的一个。该算法在计算机视觉领域有着十分重要的作用。
二、NMS算法原理
NMS算法的核心思想是保留每个目标的最高置信度的边界框,同时去除其他与之高度重叠边界框。这里的重叠通常用交并比IOU来量化。
具体步骤如下:
算法分割
-
排序: 首先,根据每个边界框的置信度(通常是分类概率与定位准确度的综合指标)进行降序排列。置信度最高的边界框被认为是最有可能正确检测到目标的。
-
选择: 从排序后的列表中选择置信度最高的边界框,标记为已选,并将其添加到最终的检测结果列表中。
-
计算IOU: 对于剩余的每个边界框,计算它与已选边界框的IOU。
-
比较与剔除: 如果某个边界框与已选框的IOU超过了预设的阈值(例如0.5或0.7),则认为这两个框表示的是同一个目标,于是根据置信度较低的原则,剔除这个低置信度的边界框。
-
重复步骤2-4: 继续选择剩余边界框中置信度最高的,重复计算IOU和剔除过程,直到所有边界框都被检查过。
-
结束: 最终,剩下的边界框集合即为经过NMS处理后的检测结果,每个目标对应一个最优的边界框。
参数调整
IOU阈值:这是决定边界框是否重叠过多的关键参数,常见的取值范围在0.3到0.7之间,具体值需根据应用场景调整。
置信度阈值:在某些实现中,会预先根据置信度过滤掉一部分低质量的预测框,以减少后续NMS处理的负担。
算法不足之处:
NMS算法虽然简单有效,但也存在一定的局限性,比如在处理极度密集的目标或者形状不规则目标时可能会误删一些有效的检测结果。因此,近年来也有一些改进版本的NMS算法被提出,如Soft-NMS、IoU-Net等,旨在提高检测性能和准确性。
三、代码实现
下边利用numpy举了一个很简单的例子。
import numpy as np
def intersection_over_union(boxA, boxB):
# 计算两个边界框的交并比(IOU)
xA = max(boxA[0], boxB[0])
yA = max(boxA[1], boxB[1])
xB = min(boxA[2], boxB[2])
yB = min(boxA[3], boxB[3])
interArea = max(0, xB - xA + 1) * max(0, yB - yA + 1)
boxAArea = (boxA[2] - boxA[0] + 1) * (boxA[3] - boxA[1] + 1)
boxBArea = (boxB[2] - boxB[0] + 1) * (boxB[3] - boxB[1] + 1)
iou = interArea / float(boxAArea + boxBArea - interArea)
return iou
def non_max_suppression(boxes, scores, iou_threshold=0.5):
"""
实现非极大值抑制(NMS),输入是边界框和对应的分数,
返回经过NMS处理后的边界框列表。
"""
# 根据分数排序
sorted_indices = np.argsort(scores)[::-1]
keep_boxes = []
while sorted_indices.size > 0:
# 选择当前最高分的框
idx = sorted_indices[0]
keep_boxes.append(idx)
# 计算当前框与其他所有框的IOU
ious = np.array([intersection_over_union(boxes[idx], boxes[i]) for i in sorted_indices[1:]])
# 删除与当前框IOU大于阈值的框
remove_indices = np.where(ious > iou_threshold)[0] + 1 # +1是因为我们忽略了第一个元素(当前最高分的框)
sorted_indices = np.delete(sorted_indices, remove_indices)
sorted_indices = np.delete(sorted_indices, 0) # 移除已经处理过的最高分框的索引
return keep_boxes
# 示例用法
if __name__ == "__main__":
# 单类别应用NMS
# np.array() 创建numpy数组
boxes = np.array([[10, 10, 40, 40], [11, 12, 43, 43], [9, 9, 39, 38]]) # [xmin, ymin, xmax, ymax]
scores = np.array([0.9, 0.8, 0.7]) # 每个框的置信度
iou_thresh = 0.1 # iou阈值
# 应用NMS
indices_to_keep = non_max_suppression(boxes, scores, iou_threshold=iou_thresh)
print("保留的边界框索引:", indices_to_keep)简单总结一下,大家有需要的可以看,有错误的地方,希望大家可以指正。

















 6843
6843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









