






C++STL学习(算法与数据结构)
1基本概念
为了建立数据结构和算法的一套标准,诞生了STL
stl即标准库模板,广义上分为容器,算法,迭代器。
容器和算法之间通过迭代器无缝衔接。
STL的技术大多用的是模板类和模板函数。
STL六大组件:
容器,算法,迭代器,仿函数,适配器,空间配置器。
适配器:一种用来修饰容器或者仿函数或迭代器接口的东西。
空间配置器:负责空间的配置与管理。
2容器
容器指各种数据结构,用来存放数据,可以将运用最广泛的数据结构实现,分为序列式容器(有明显的顺序关系)和关联式容器(没有严格物理上的顺序关系),在使用每种容器时必须包含其头文件#include。
2.1 vector容器
#include<vector>
vector<int> v;
v.push_back(n)//尾插法插入数据
//通过迭代器访问容器中的数据
vector<int>::iterator itBegin=v.begin();//起始迭代器,指向第一个数据,可以将迭代器当作一个指针,那么itBegin是指向第一个元素的指针
vector<int>::iterator intEnd=v.end();//指向最后一个数据的下一个数据,同理,itEnd为指向最有一个元素的下一个元素的指针。
//遍历数组的实现:
1
while(itBegin!=itEnd)
{
cout<<*itBegin<<endl;
itBegin++;//起始迭代器向后偏移。
}
也可以:
2
for(vector<int> iterator::kaishi=v.begin();kaishi!=v.end();kaishi++)
{
cout<<*kaishi<<endl;
}
3利用STL中的算法for_each;
#include<algorithm>
void myprint(int val)
{
cout<<val<<endl;
}
for_each(v.begin(),v.end(),myprint);
//for_each有三个参数,起始迭代器,结束迭代器,函数名。
vector存放自定义数据类型。
则可以打印((*it).age)来打印自定义类型的成员。
若存放了指针,则可以(*it)->age;
vector 容器嵌套容器。
vector<vector>
可以通过二次for循环遍历。
进一步学习vector:
概念:

动态扩展机制:
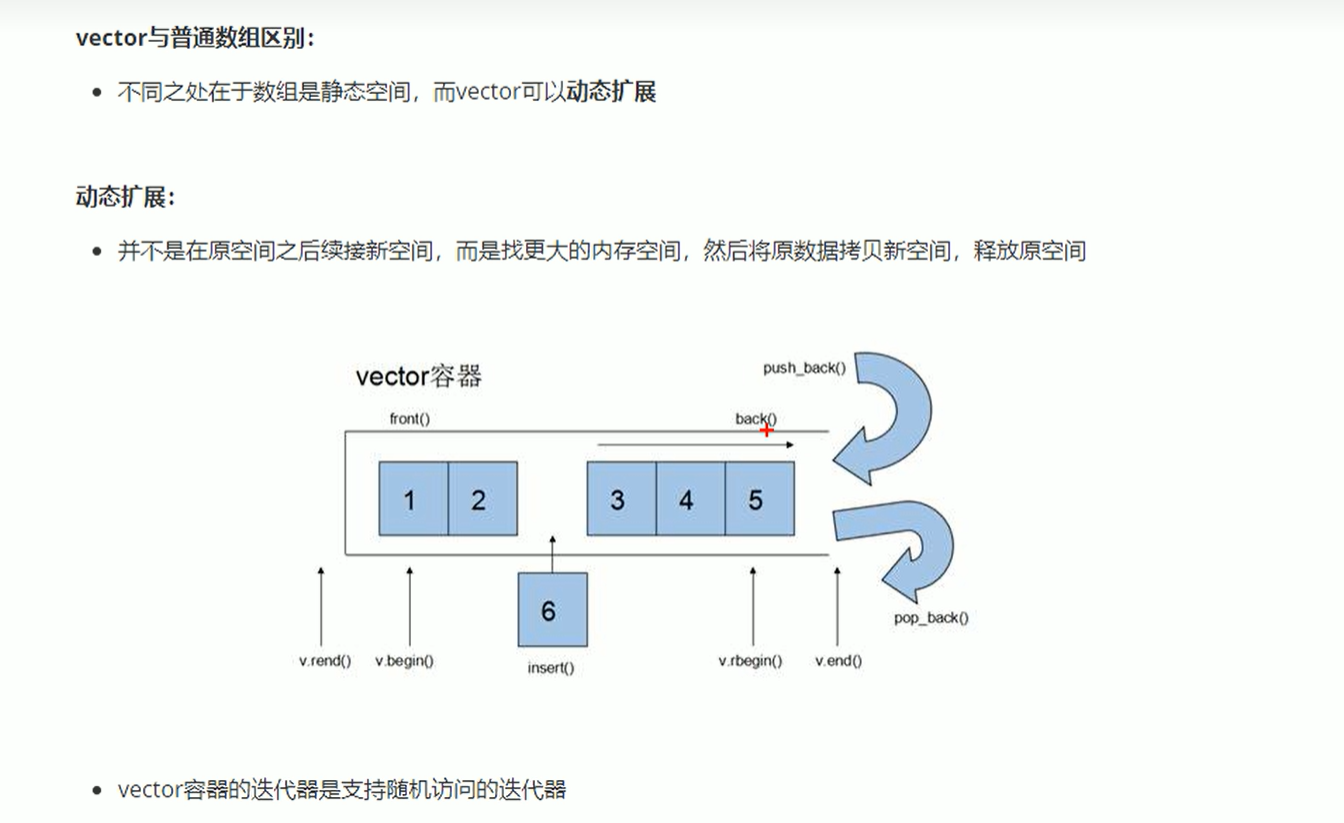
vector迭代器是支持随机访问的迭代器。
vector构造函数:

vector赋值操作:

vector的容量:

vector插入:

vector数据存取:

vector容器交换:

利用swap函数可以达到收缩内存的作用:

匿名对象内存系统自动释放。
vector预留:

如果一开始vec中数据量过大,可以提前用reserve函数预留空间,减少动态扩展次数。
2.2 string容器
string是c++风格字符串,而string本质是一个类。
string内部封装了char*,管理这个字符串,是一个char*型的容器。
string类内有很多成员方法如:fing,copy,delete,replace,insert。
string的构造函数:

赋值操作:

字符串拼接:

字符串查找和替换:


字符串比较:
一般是逐个比较字符对应的ASCII码,主要用于比较两个字符串是否相等。

字符串存取:

字符串的插入和删除:

字符串截取(求子串):


查找与截取组合使用:


deque容器
概念:
deque是双端数组,可以对头部进行插入删除操作。

构造函数:

若要限制容器为只读状态,可以利用const修饰迭代器:

deq赋值:

deq大小操作:

注:deq没有容量概念。
deq插入删除:

deq数据存取:

deque排序:

使用sort算法时必须包含算法的头文件#include。

stack(栈)容器
只有一个对外接口:

先进后出。
不允许有遍历行为,只有栈底元素可以被读取
stack对外接口:

queue队列容器

queue的进出顺序与stack相反,现进先出。
queue接口:

queue和stack常用while(!q.empty())将元素全部取出。
链表

优点:可以在任意位置快速插入删除元素,
缺点:容器的遍历速度没有数组快。
stl中的list是一个双向循环链表,支持头插和尾插。

list构造:

list赋值和交换:

list大小操作:

list插入和删除:

list数据存取:

list本质链表,不是线性空间存储数据,不支持随机访问,只能it++。
list中的反转和连续:

反转:l.reverse(),所有不支持随机访问的容器不支持算法。
不支持随机访问迭代器的容器内部会提供算法。
排序:
bool mycompare(int a,int b)
{
return a>b;
}
int main()
{
list z;
z.sort(mycompare)
实现z的降序排列。
}
set,multiset容器(使用时只需包含一个set的头文件)

set的构造和赋值操作:
set自动排序:按照ASCII码排序。
set大小和交换:

set的插入和删除:

set的查找与统计:

set查找的是迭代器,若没找到,返回a.end()。
统计返回的是int数,对于set而言,返回的是0或1,不可重复插入相同元素,但multiset可以。
set与multiset区别:

对组:
创建:

使用:

set排序:



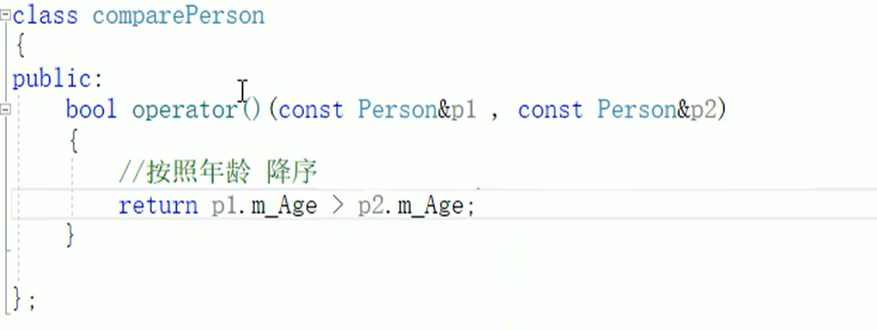
set存放自定义数据类型:
set存放自定义数据类型时需要指定排序规则。
map和multimap容器
map容器中的系统会自动按照key来自动排序。

map的构造与赋值:

map中所有元素都是成对出现的,插入元素时要使用对组,对组与map中的基本数据类型必须一致。
map容器的大小和交换操作:

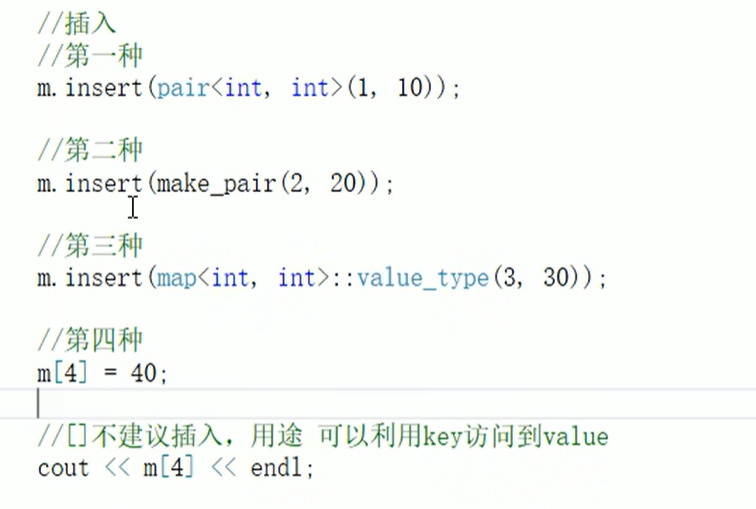
map中的插入和删除:

插入:
删除:

map中的查找和统计:

注:查找和统计的为key。
查找返回的是迭代器。
统计:

map排序操作:
map默认按照key的大小从小到大排序,但可以利用仿函数改变排序规则。
在创建的map的value值后添加一个模板参数,在创建迭代器等时也需要多加一个模板参数。


函数对象

谓词:
调用模板库中参数列表中有:pr_pred就是谓词,可以利用谓词改变函数算法策略。
概念:

一元谓词:

二元谓词:

内置函数对象

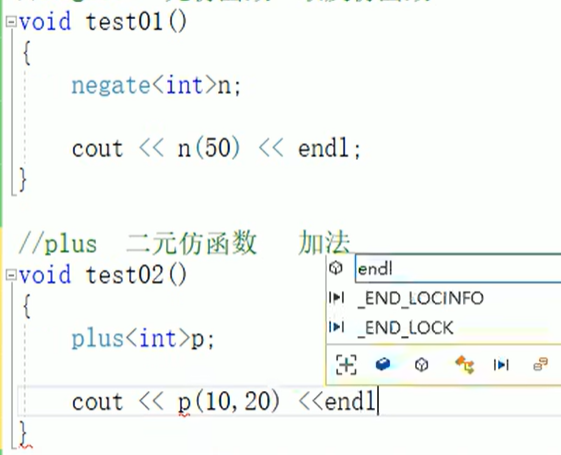
算数仿函数:

具体用法:
关系仿函数:

可以利用内建仿函数作谓词改变算法规则。
逻辑仿函数:
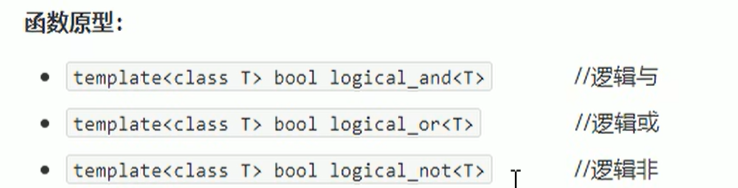
逻辑仿函数一般不常用。
3算法
各种常用的算法,有限的步骤,解决逻辑数学问题。
分为质变算法(改变容器内容)和非质变算法(不改变容器内容)。
概念

常用的遍历算法

for_each()

对容器内迭代器之间的每一个元素执行函数操作,每一个元素作为参数传入函数或仿函数中。
若用的为函数,则传入函数名,若为仿函数,则需要放入函数对象包含“()”。
transform

_func的作用:可以对原容器的数据做一些操作后再搬运到新容器。
注意:目标容器需要提前用resize开辟空间。
常用的查找算法
算法简介:

find

若要使用find查找自定义数据类型,那么要在类内重载“”(返回值为bool类型),因为底层没有定义自定义数据类型的’‘。
find_if

adjacent——find

binary_search(二分查找法)

返回的bool类型,效率很高。
count

统计自定义数据类型时:与find同理:要在类内重载“”(返回值为bool类型),因为底层没有定义自定义数据类型的’‘。
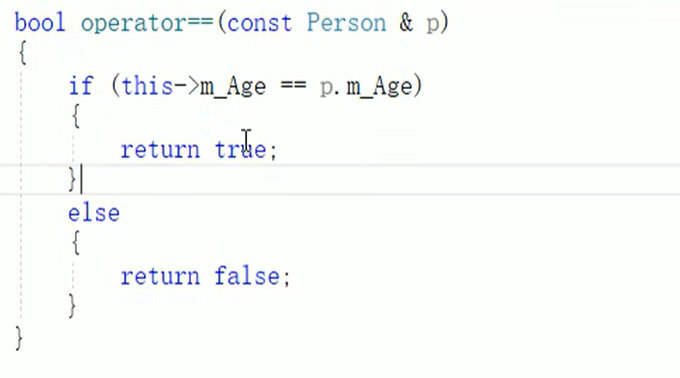
加入const防止数据修改(底层需求)
count_if:

常用的排序算法

sort

谓词可以不填,默认从小到大排序。
random_shuffle
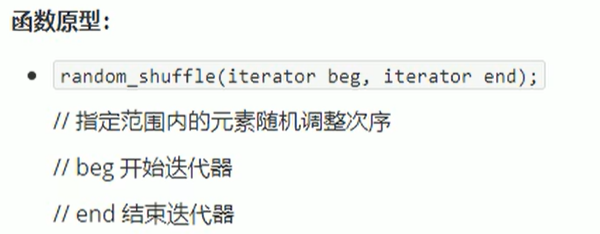
使用时记得加随机数种子。
merge
可以将两个容器合并储存到一个新的容器内。

记得提前给目标容器分配空间。
reverse

常用的拷贝和构造算法

copy

注:不要可以使用copy算法,实际开发中有更简单的容器内置函数或重载运算符,优先使用容器内置函数。
replace

replace会替换区间所有满足条件的元素。
replace_if

swap

注:必须是两个类型相同的容器。
常用的算术生成算法

accumulate

fill

将容器某个区间的元素填充成你想要的元素。
常用集合算法

set_intersection(求交集)

注:原容器必须是有序序列,交集元素容器的大小取两个容器中容器大小最小的那个,返回值是交集元素最后一个元素的迭代器。
set_union(求并集)

原容器必须是有序序列,交集元素容器的大小取两个容器中容器大小两个容器大小和,返回值是并集元素最后一个元素的迭代器。
如图求得v1对v2的差集,v1相对于v2多的元素(v1有而v2没有的)
set_difference(求差集)

原容器必须是有序序列,交集元素容器的大小取两个容器中容器大小最大的那个,返回值是差集元素最后一个元素的迭代器。
寄存器:
扮演容器与算法之间的粘合剂。每个容器都有自己专属的迭代器。
分为输入,输出,前向,双向,随机访问迭代器。















 1167
1167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









