






熵权法
评价类问题介绍
一般解决评价类问题:方法 层次分析法、Topsis
局限性:主观性太强、不确定指标的选取为多少适宜
评价类问题 目的:得知一组方案的好坏,对数据评优、排序、选择
最重要步骤:权重的选择、
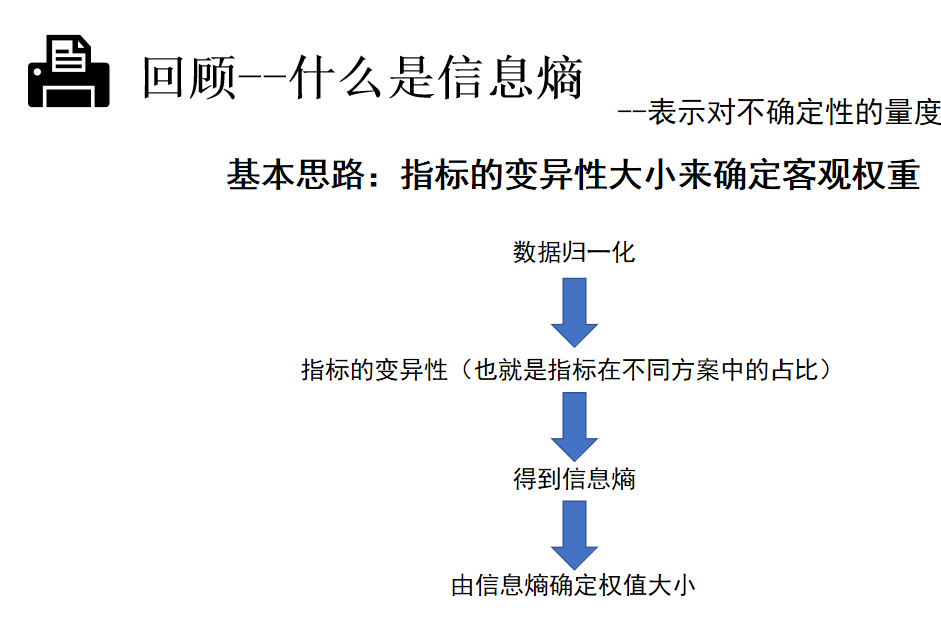
什么是熵权法
熵是对不确定信息的度量,熵与信息量成反比,熵值越小越好
比如犯人提供信息,提供的越多 信息量越多,越有序,熵值越小 信息熵小的,权重大
熵权法步骤
1)首先对数据进行归一化处理:

2)计算第j项指标下第i方案指标值的比重p^ij

3)计算第j项指标的信息熵值

4) 计算信息熵冗余度:

5) 计算各项指标权重:
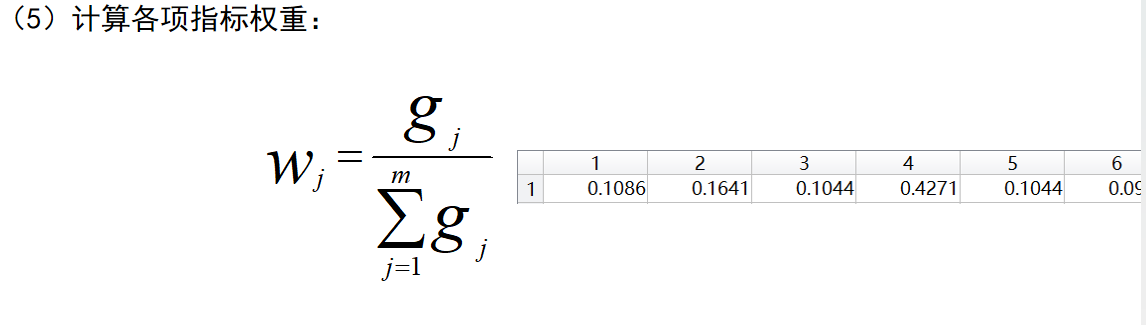
6)计算综合得分
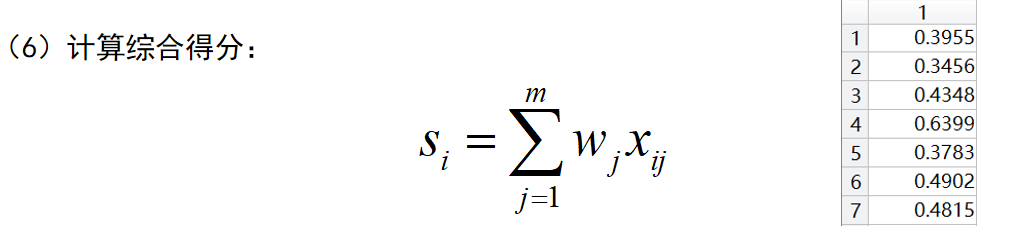
回顾
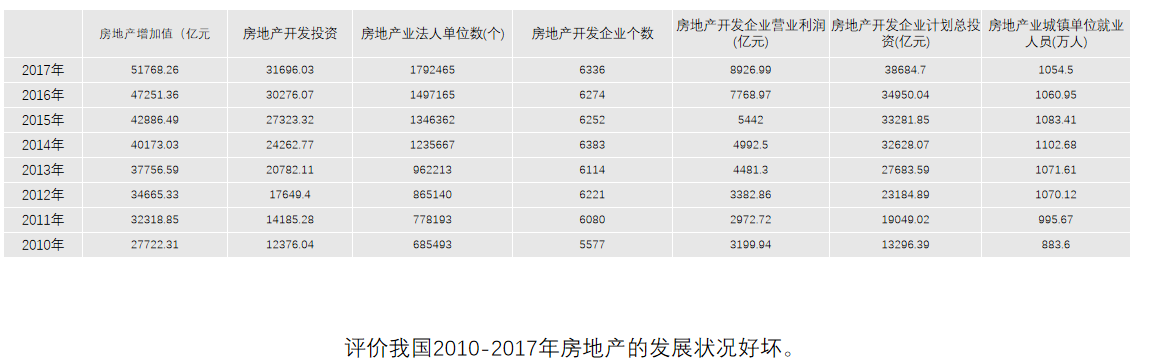
熵权法应用
tic; %检测时间
clear;
close;
clc;
x=xlsread('data-上课.xlsx'); %打开数据
[n,m]=size(x); %获取n行样本 m行指标
%% 1.每一个指标下面对样本进行归一化
for i=1:m
x(:,i)=GuiYiFa(x(:,i),1,0.002,1);
end
%% 2.计算比重
p=ones(n,m);
for i =1:n
for j=1:m
p(i,j)= x(i,j)/(sum(x(:,j)));
end
end
%% 3.计算每个数据的熵值
k=1/(log(n));
for i=1:m
e(i)=-k*sum(p(:,i).*log(p(:,i)));
end
%% 4.计算信息熵冗余度
d=ones(1,m);
d=1-e;
%% 5.计算各项权重指标
w=d./sum(d);
%% 6.计算综合得分 并画图
s=x*w';
plot(2017:-1:2010,s) %注意是哪一年在上
toc;% 检测时间
%封装归一化函数
function y=GuiYiFa(x,type,ymin,ymax)
%实现正向或负向指标归一化,返回归一化后的数据矩阵
%x为原始数据矩阵, 一行代表一个样本, 每列对应一个指标
%type设定正向指标1,负向指标2
%ymin,ymax为归一化的区间端点
[n,m]=size(x);
y=zeros(n,m);
xmin=min(x);
xmax=max(x);
switch type
case 1
for j=1:m
y(:,j)=(ymax-ymin)*(x(:,j)-xmin(j))/(xmax(j)-xmin(j))+ymin;
end
case 2
for j=1:m
y(:,j)=(ymax-ymin)*(xmax(j)-x(:,j))/(xmax(j)-xmin(j))+ymin;
end
end














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









