






第一步:标记数据
下载labelImg
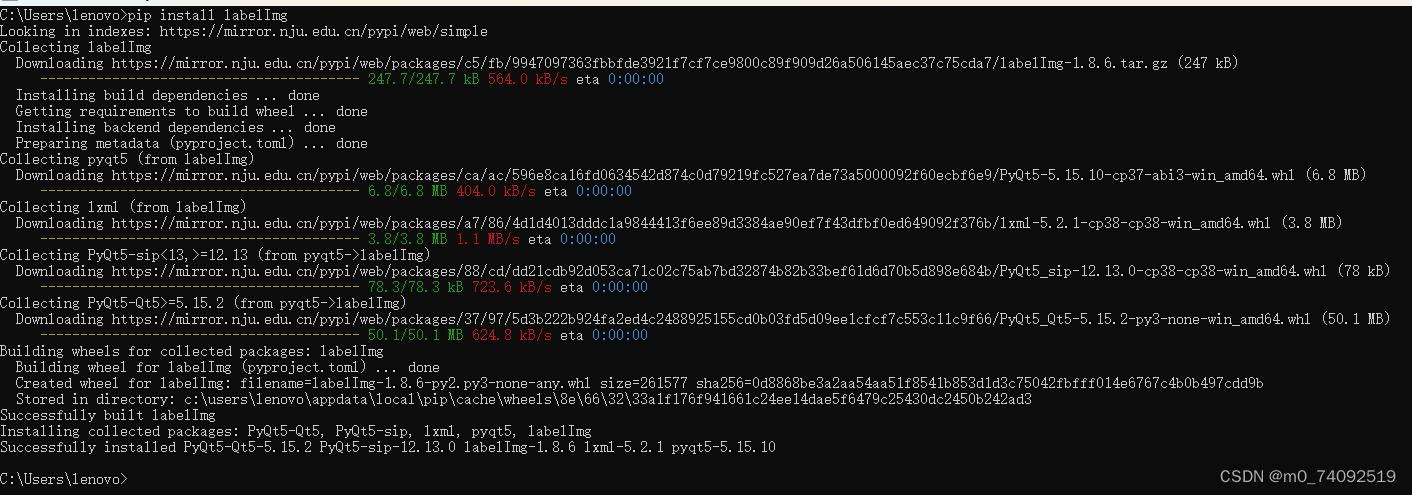
win+R打开cmd,输入pip install labelImg
启动labelImg
输入labelImg,进入labelImg

打开labelImg,界面如下。
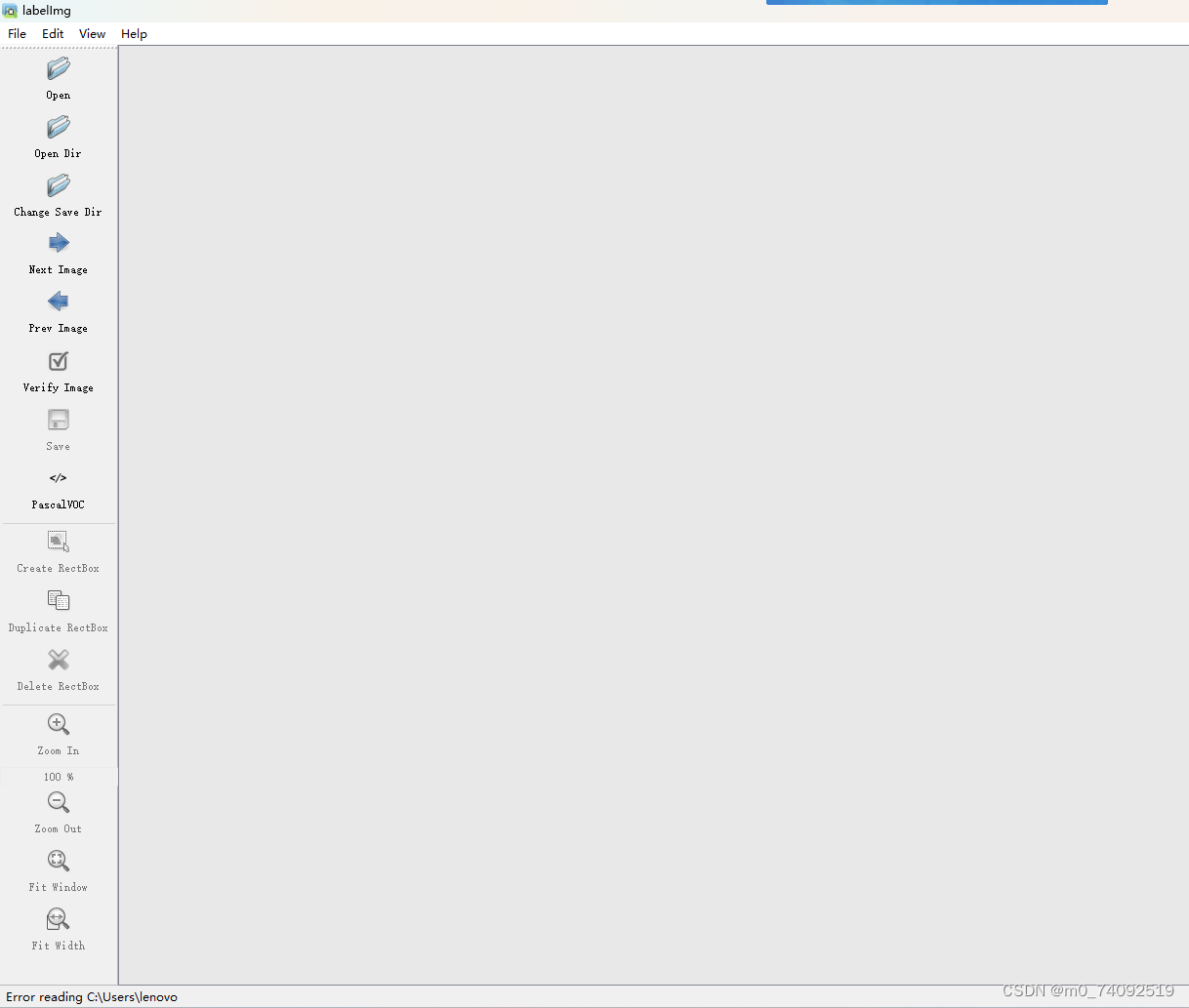
labelImg相应的功能
其中Open是打开相应的图片,Open Dir是打开对应的照片路径,如果需要使用下面的Next Imge和Prev Image这两个功能,就可以使用打开这个Open Dir这个功能,然后Next Image功能是下一张图片,Prev Image是上一张图片。Change Save Dir 是我们标记图片后需要保存的路径(这个文件夹需要自己建立),Save是保存标记后的图片,则在文件夹中生成相应的.xml文件。
标记数据
标记数据使用Creates RectBox这个功能,然后框出自己需要标记的数据,如下:
松开鼠标后会出现下面这个图片:
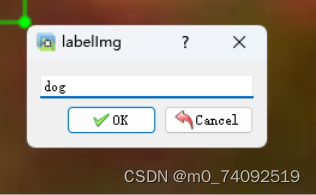
这个可输入自己需要的标签,比如我要识别这个狗,把标签写出dog,然后点击ok这个按钮就好了,如果框到的区域不满意,可以点击Cancel取消,重新点击Creates RectBox这个功能,重新标记。
第二步:把图片和生成的xml文件放入相应的文件夹中
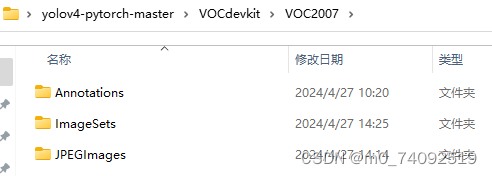
把图片放在yolov4-pytorch-master\VOCdevkit\VOC2007\JPEGImages文件夹中,把标记后生成的.xml文件放在yolov4-pytorch-master\VOCdevkit\VOC2007\Annotations文件夹中。
第三步:打开yolov4-pytorch-master这个项目
使用pycharm打开yolov4-pytorch-master这个项目
第四步:在yolov4-pytorch-master\model_data\voc_classes.txt和coco_classes.txt中加入自己所需要识别的标签,比如上面所弄的dog标签。
第五步:生成相应的text.txt等文件
修改生成文件保存的路径
首先在这个目录yolov4-pytorch-master\VOCdevkit\VOC2007下建立ImageSets文件,再建立子文件Main,然后打开voc_annotation.py这个文件,把相应的路径改成图片和.xml文件,以及生成的text.txt等文件放在这个yolov4-pytorch-master\VOCdevkit\VOC2007\ImageSets\Main路径下。

运行voc_annotation.py文件
然后运行voc_annotation.py文件,结果如下:
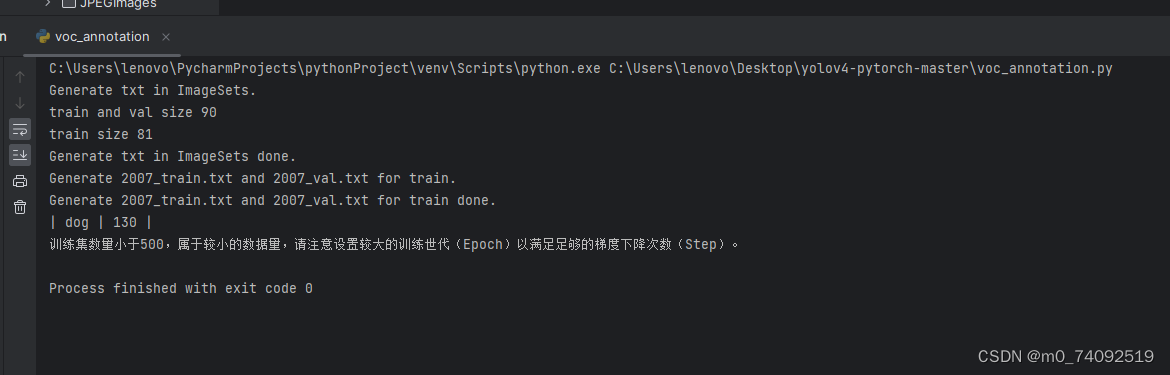
如果图片数量少于500张,会出现下面的结果(但是不重要,100张也可以的,只是设定的代码有,可以删掉)。
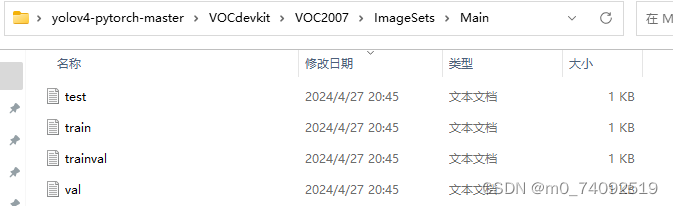
检查生成文件
然后检查一下是否有生成test.txt,train.txt,trainval.txt,val.txt这几个文件,以及2007_train.txt,2007_val.txt这两个有没有生成,如下图所示:
如果2007_train.txt,2007_val.txt这两个文件没有生成,则下面运行train.py文件就会出现错误,报错找不到文件。
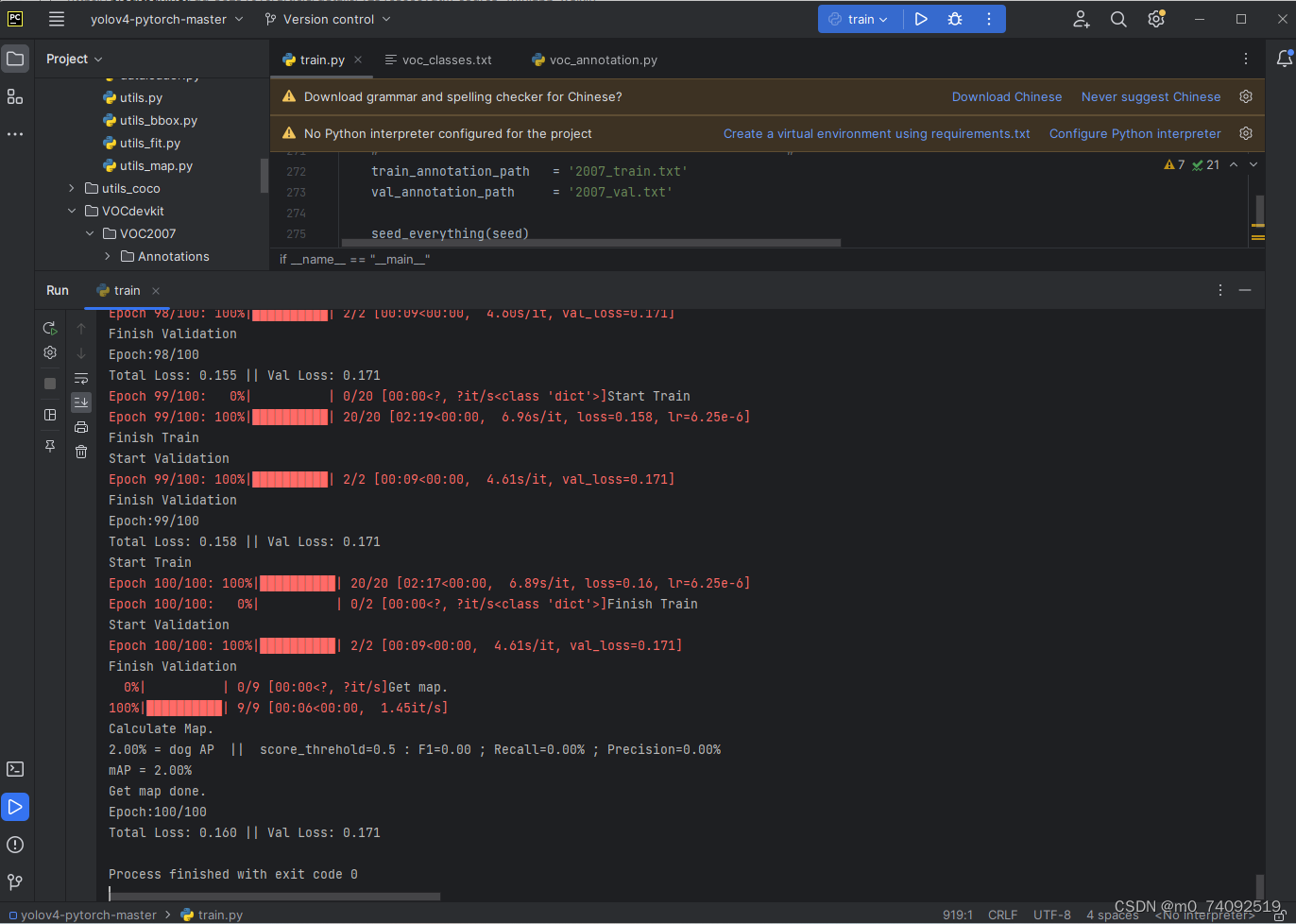
第六步:运行train.py文件
运行成功后如图所示:
第七步:修改predict.py文件
首先在yolov4-pytorch-master\img文件夹中保存一张我们需要预测的图片,后缀名为.jpg。然后在predict.py文件修改图片路径,如下图:

第八步:运行predict.py文件
运行predict.py文件后,然后在下面的Input image filename:输入我们需要预测图片的路径,比如:./img/101.jpg,运行结果如下图所示:
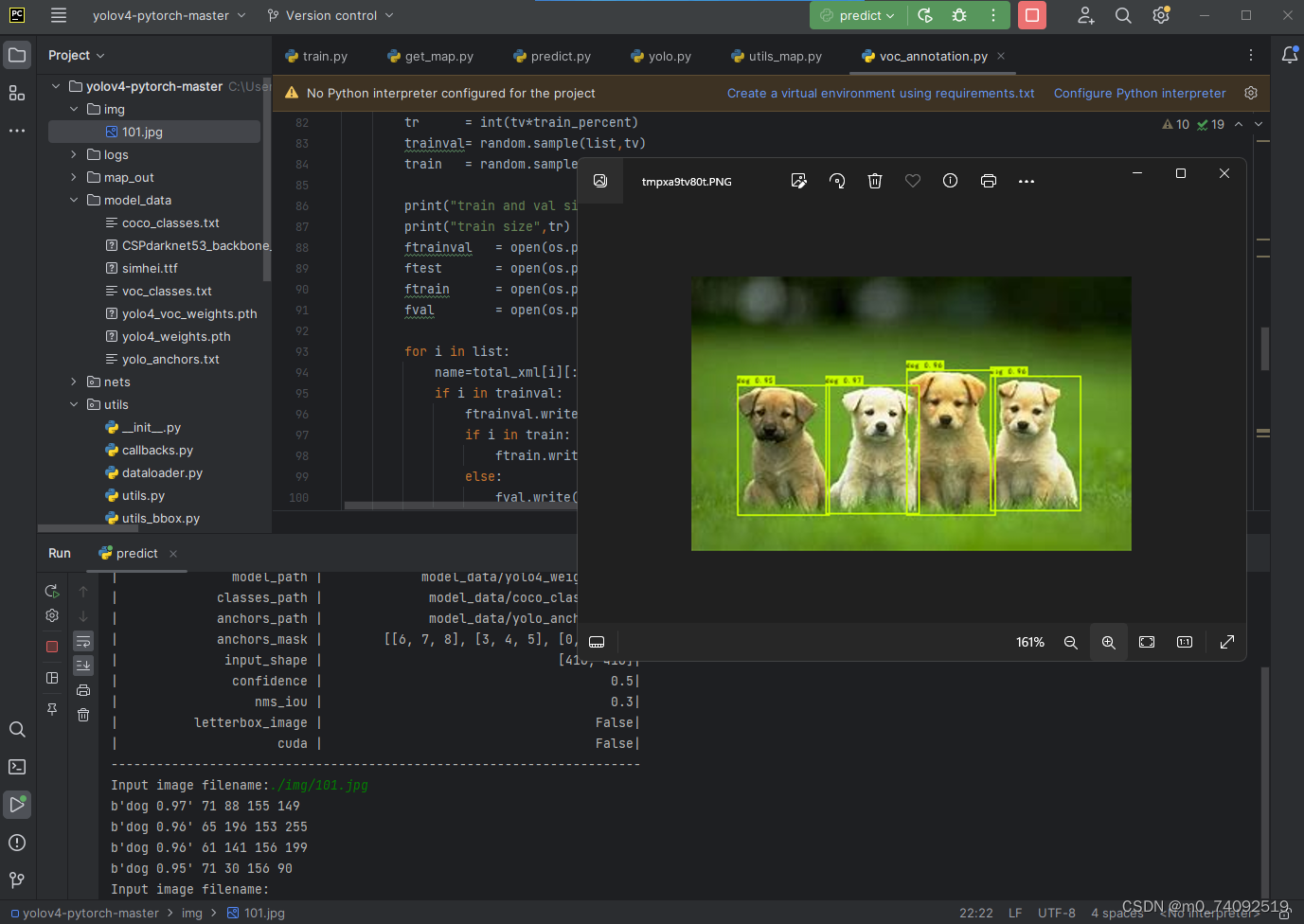
这就完成了。
注意事项:
1、训练前仔细检查自己的格式是否满足要求,该库要求数据集格式为VOC格式,需要准备好的内容有输入图片和标签
输入图片为.jpg图片,无需固定大小,传入训练前会自动进行resize。
灰度图会自动转成RGB图片进行训练,无需自己修改。
输入图片如果后缀非jpg,需要自己批量转成jpg后再开始训练。
标签为.xml格式,文件中会有需要检测的目标信息,标签文件和输入图片文件相对应。
2、损失值的大小用于判断是否收敛,比较重要的是有收敛的趋势,即验证集损失不断下降,如果验证集损失基本上不改变的话,模型基本上就收敛了。
损失值的具体大小并没有什么意义,大和小只在于损失的计算方式,并不是接近于0才好。如果想要让损失好看点,可以直接到对应的损失函数里面除上10000。
训练过程中的损失值会保存在logs文件夹下的loss_%Y_%m_%d_%H_%M_%S文件夹中
3、训练好的权值文件保存在logs文件夹中,每个训练世代(Epoch)包含若干训练步长(Step),每个训练步长(Step)进行一次梯度下降。
如果只是训练了几个Step是不会保存的,Epoch和Step的概念要捋清楚一下。
可能会出现的错误:
- 没有安装好需要的包。解决办法:pip install+安装包名字。
- 运行train.py文件出现这个错误:FileNotFoundError: [Errno 2] No such file or directory: '2007_train.txt'。解决办法:检查voc_annotation.py文件运行是否有错误。















 1277
1277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









