







9、处理大数据集
9.1学习大数据集
采用大量数据训练得到的模型效果往往很好
但是,大数据集带来更大的计算问题,例如计算代价函数时的计算量会变得很大

同时,我们也知道大数据量对高方差的模型有效果,而对高偏差的模型效果不大
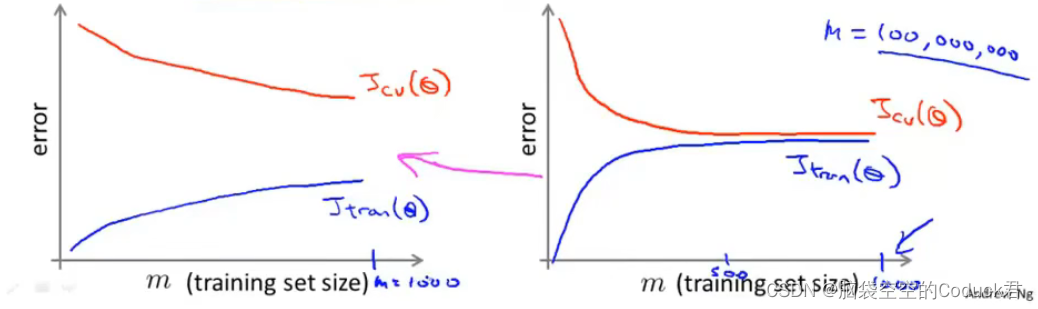
对于高方差模型,我们往往会增加基础结构,改变算法,利用更大的数据集
在大规模机器学习中,我们更偏向于找到合理或高效的计算方法
9.2随机梯度下降
批量梯度下降
虽然梯度下降较快,但梯度下降都是采用所有样本(尤其是大数据集时)来计算,这就导致计算量很大
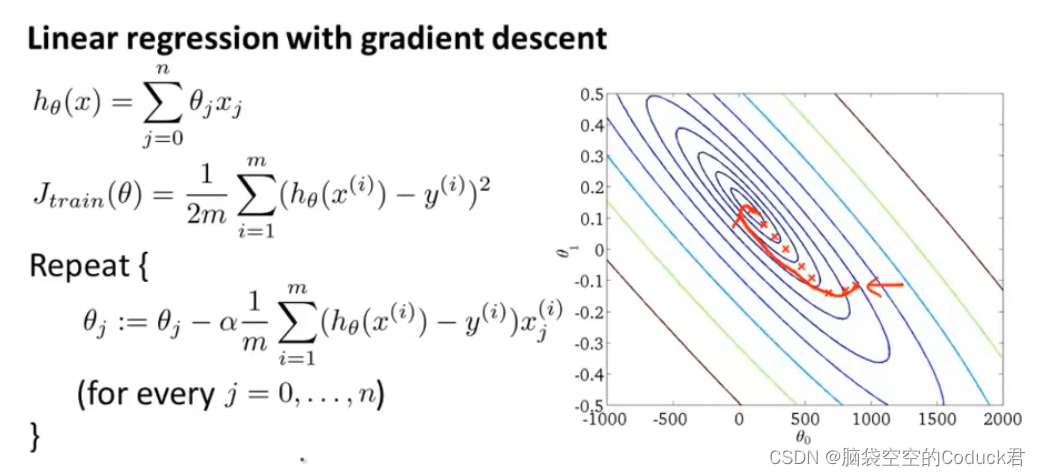
所以,随机梯度下降正是要优化计算梯度的问题
随机梯度下降的思想:每次只采用一个样本来更新梯度,减少计算量

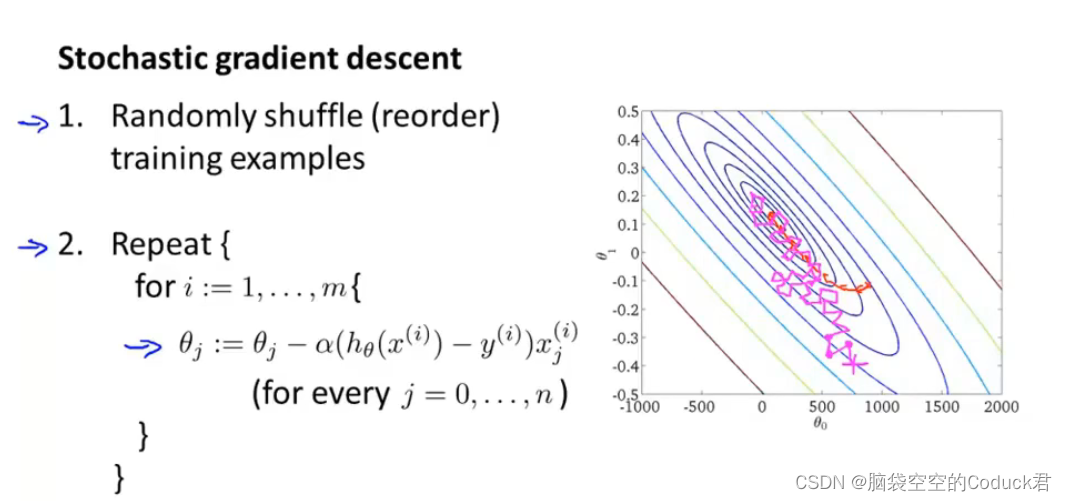
注意:
1、首先对数据要进行随机排序
2、虽然每次只采用一个样本去更新梯度,但是代价函数还是要计算所有样本的代价

3、随机梯度下降的时候,下降的路径可能会很曲折,不断波动,但是总体趋势还是会不断减小。但是最后可能不一定能够收敛到全局最小值,但是也会收敛到近似最小值
4、外循环Repeat次数按实际情况
9.3Mini-Batch梯度下降
Mini-Batch梯度下降介于批量梯度下降和随机梯度下降之间,采用b个样本来计算梯度

通常,取b的值为10,b的取值范围在2到100之间

当有合适的向量化方法时,多个样本并行计算梯度将比只取一个样本计算梯度的随机梯度下降要快
但缺点是要确定b的值
9.4随机梯度下降收敛
对于较小的数据集运行Batch梯度下降,我们通常会绘制代价函数的变化曲线来观察梯度下降是否收敛

而对于随机梯度下降来说,我们可以在更新梯度前计算当前样本代价函数值,然后每进行1000次迭代,绘制这1000个样本的代价函数的平均值变化曲线
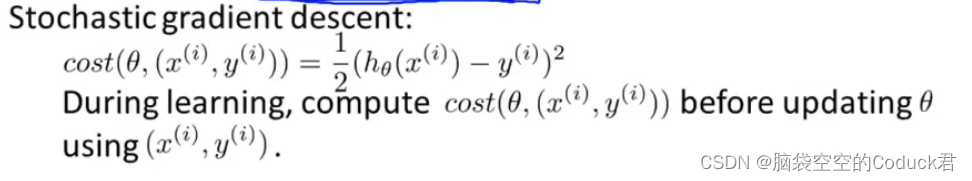

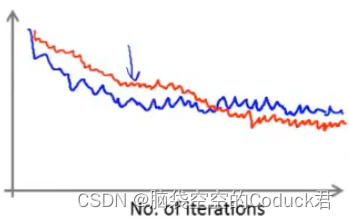
正常情况下我们是会得到下列曲线。蓝色代表α更小,橙色代表α更大,α更小的下降比较慢,但是一般会得到更好的参数值
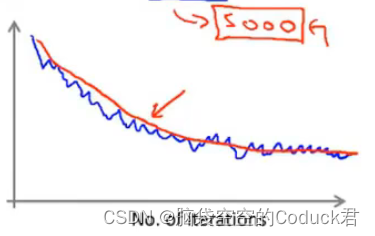
b越大,得到的曲线越光滑
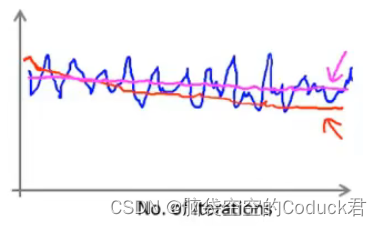
蓝色线是b太小的情况,橙色线是b较大时的情况,可以看出当曲线过于震荡时,可以采用更大的b值
当b足够大但仍出现粉色线平坦这种情况时,说明算法并没有进行学习,需要调整学习速率或调整特征
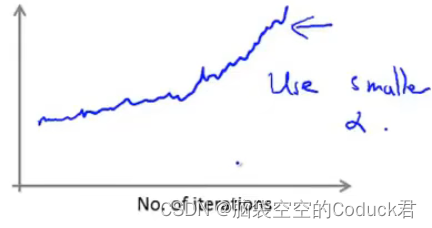
如果曲线出现上升,那么可能就是α太大了,这时需要调小α
随机梯度下降会出现波动,因此我们也可以在梯度下降过程中,逐渐减小学习率α,使得最终能更好地收敛到最小值。但是这种方法需要自己额外确定参数
α
=
c
o
n
s
t
1
i
t
e
r
a
t
i
o
n
N
u
m
b
e
r
+
c
o
n
s
t
2
\alpha = \frac{const1}{iterationNumber+const2}
α=iterationNumber+const2const1

9.5在线学习
当我们拥有连续的数据流的时候,我们可以考虑使用在线学习,不断优化决策
例如,一个物流网站,用户会登录进去查看我寄送这个包裹的价格,然后决定在这家物流网站寄送(y=1)或者不寄送(y=0)。因此,这个物流网站就可以采用用户源源不断的登录数据进行在线学习,利用用户的特征进行拟合,使得物流寄送包裹的价格随 着不同用户的变化而变化,能够使价格达到用户能够接受的最大价格
优点:不需要固定的数据集,只需要连续的数据流
模型可以随客户选择的变化而变化

每得到一个样本,就像随机梯度下降那样更新参数,然后样本即可丢弃
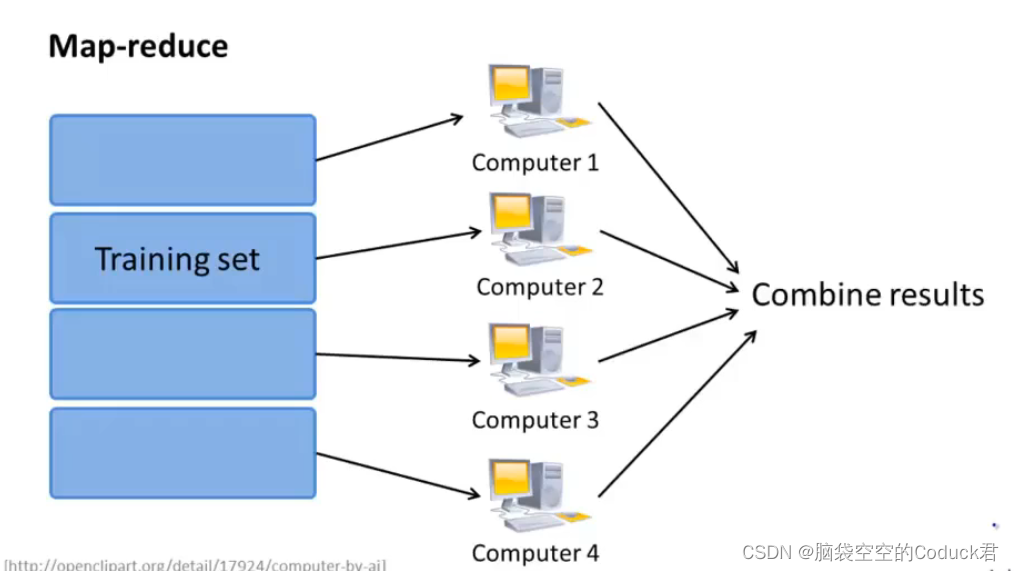
9.6减少映射与数据并行
我们在进行梯度更新的时候,需要更新所有参数,但是当数据量很大的时候,在一台计算机上计算的时间会很长。
因此,我们就可以将任务分配到多个计算机上进行计算,最后使用一个服务器来进行汇总,这样就可以实现并行计算,大大提高计算效率

Map-reduce
将数据集分成几部分,每部分在不同的电脑上进行计算或在同一电脑的不同cpu上计算
适用于学习算法可以表示为对训练集的一种求和















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









