









概述
情感分类是自然语言处理中的经典任务,是典型的分类问题。本节使用MindSpore实现一个基于RNN网络的情感分类模型,实现如下的效果:
输入: This film is terrible
正确标签: Negative
预测标签: Negative
输入: This film is great
正确标签: Positive
预测标签: Positive数据准备
| Review 回顾 | Label 标签 |
|---|---|
| "Quitting" may be as much about exiting a pre-ordained identity as about drug withdrawal. As a rural guy coming to Beijing, class and success must have struck this young artist face on as an appeal to separate from his roots and far surpass his peasant parents' acting success. Troubles arise, however, when the new man is too new, when it demands too big a departure from family, history, nature, and personal identity. The ensuing splits, and confusion between the imaginary and the real and the dissonance between the ordinary and the heroic are the stuff of a gut check on the one hand or a complete escape from self on the other. “戒烟”可能与戒毒一样,意味着退出预先设定的身份。作为一个来到北京的农村人,阶级和成功一定让这位年轻的艺术家直面,这是对他脱离根源的呼吁,远远超过了他农民父母的表演成功。然而,当新人太新时,当它要求与家庭、历史、自然和个人身份背离太大时,麻烦就出现了。随之而来的分裂,虚构与真实之间的混乱,平凡与英雄之间的不和谐,一方面是直觉检查的东西,另一方面是彻底逃避自我的东西。 | Negative 阴性 |
| This movie is amazing because the fact that the real people portray themselves and their real life experience and do such a good job it's like they're almost living the past over again. Jia Hongsheng plays himself an actor who quit everything except music and drugs struggling with depression and searching for the meaning of life while being angry at everyone especially the people who care for him most. 这部电影令人惊叹,因为真实的人描绘了自己和他们的真实生活经历,并且做得如此出色,就像他们几乎要重新活过去一样。贾洪生饰演的自己,一个除了音乐和毒品之外,什么都放弃了,与抑郁症作斗争,寻找生命的意义,同时对每个人,尤其是最关心他的人感到愤怒。 | Positive 阳性 |
此外,需要使用预训练词向量对自然语言单词进行编码,以获取文本的语义特征,本节选取Glove词向量作为Embedding。
数据下载模块
import os
import shutil
import requests
import tempfile
from tqdm import tqdm
from typing import IO
from pathlib import Path
# 指定保存路径为 `home_path/.mindspore_examples`
cache_dir = Path.home() / '.mindspore_examples'
def http_get(url: str, temp_file: IO):
"""使用requests库下载数据,并使用tqdm库进行流程可视化"""
req = requests.get(url, stream=True)
content_length = req.headers.get('Content-Length')
total = int(content_length) if content_length is not None else None
progress = tqdm(unit='B', total=total)
for chunk in req.iter_content(chunk_size=1024):
if chunk:
progress.update(len(chunk))
temp_file.write(chunk)
progress.close()
def download(file_name: str, url: str):
"""下载数据并存为指定名称"""
if not os.path.exists(cache_dir):
os.makedirs(cache_dir)
cache_path = os.path.join(cache_dir, file_name)
cache_exist = os.path.exists(cache_path)
if not cache_exist:
with tempfile.NamedTemporaryFile() as temp_file:
http_get(url, temp_file)
temp_file.flush()
temp_file.seek(0)
with open(cache_path, 'wb') as cache_file:
shutil.copyfileobj(temp_file, cache_file)
return cache_pathimdb_path = download('aclImdb_v1.tar.gz', 'https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/aclImdb_v1.tar.gz')
imdb_path加载IMDB数据集
下载好的IMDB数据集为tar.gz文件,我们使用Python的tarfile库对其进行读取,并将所有数据和标签分别进行存放。原始的IMDB数据集解压目录如下:
├── aclImdb
│ ├── imdbEr.txt
│ ├── imdb.vocab
│ ├── README
│ ├── test
│ └── train
│ ├── neg
│ ├── pos
...
数据集已分割为train和test两部分,且每部分包含neg和pos两个分类的文件夹,因此需分别train和test进行读取并处理数据和标签。
import re
import six
import string
import tarfile
class IMDBData():
"""IMDB数据集加载器
加载IMDB数据集并处理为一个Python迭代对象。
"""
label_map = {
"pos": 1,
"neg": 0
}
def __init__(self, path, mode="train"):
self.mode = mode
self.path = path
self.docs, self.labels = [], []
self._load("pos")
self._load("neg")
def _load(self, label):
pattern = re.compile(r"aclImdb/{}/{}/.*\.txt$".format(self.mode, label))
# 将数据加载至内存
with tarfile.open(self.path) as tarf:
tf = tarf.next()
while tf is not None:
if bool(pattern.match(tf.name)):
# 对文本进行分词、去除标点和特殊字符、小写处理
self.docs.append(str(tarf.extractfile(tf).read().rstrip(six.b("\n\r"))
.translate(None, six.b(string.punctuation)).lower()).split())
self.labels.append([self.label_map[label]])
tf = tarf.next()
def __getitem__(self, idx):
return self.docs[idx], self.labels[idx]
def __len__(self):
return len(self.docs)完成IMDB数据加载器后,加载训练数据集进行测试,输出数据集数量:
imdb_train = IMDBData(imdb_path, 'train')
len(imdb_train)将IMDB数据集加载至内存并构造为迭代对象后,可以使用mindspore.dataset提供的Generatordataset接口加载数据集迭代对象,并进行下一步的数据处理,下面封装一个函数将train和test分别使用Generatordataset进行加载,并指定数据集中文本和标签的column_name分别为text和label:
import mindspore.dataset as ds
def load_imdb(imdb_path):
imdb_train = ds.GeneratorDataset(IMDBData(imdb_path, "train"), column_names=["text", "label"], shuffle=True, num_samples=10000)
imdb_test = ds.GeneratorDataset(IMDBData(imdb_path, "test"), column_names=["text", "label"], shuffle=False)
return imdb_train, imdb_test
imdb_train, imdb_test = load_imdb(imdb_path)
imdb_train加载预训练词向量
预训练词向量是对输入单词的数值化表示,通过nn.Embedding层,采用查表的方式,输入单词对应词表中的index,获得对应的表达向量。 因此进行模型构造前,需要将Embedding层所需的词向量和词表进行构造。这里我们使用Glove(Global Vectors for Word Representation)这种经典的预训练词向量, 其数据格式如下:
| Word 词 | Vector 向量 |
|---|---|
| the 这 | 0.418 0.24968 -0.41242 0.1217 0.34527 -0.044457 -0.49688 -0.17862 -0.00066023 ... |
| , | 0.013441 0.23682 -0.16899 0.40951 0.63812 0.47709 -0.42852 -0.55641 -0.364 ... |
我们直接使用第一列的单词作为词表,使用dataset.text.Vocab将其按顺序加载;同时读取每一行的Vector并转为numpy.array,用于nn.Embedding加载权重使用。具体实现如下:
import zipfile
import numpy as np
def load_glove(glove_path):
glove_100d_path = os.path.join(cache_dir, 'glove.6B.100d.txt')
if not os.path.exists(glove_100d_path):
glove_zip = zipfile.ZipFile(glove_path)
glove_zip.extractall(cache_dir)
embeddings = []
tokens = []
with open(glove_100d_path, encoding='utf-8') as gf:
for glove in gf:
word, embedding = glove.split(maxsplit=1)
tokens.append(word)
embeddings.append(np.fromstring(embedding, dtype=np.float32, sep=' '))
# 添加 <unk>, <pad> 两个特殊占位符对应的embedding
embeddings.append(np.random.rand(100))
embeddings.append(np.zeros((100,), np.float32))
vocab = ds.text.Vocab.from_list(tokens, special_tokens=["<unk>", "<pad>"], special_first=False)
embeddings = np.array(embeddings).astype(np.float32)
return vocab, embeddings
glove_path = download('glove.6B.zip', 'https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/glove.6B.zip')
vocab, embeddings = load_glove(glove_path)
len(vocab.vocab())
idx = vocab.tokens_to_ids('the')
embedding = embeddings[idx]
idx, embedding
数据集预处理
通过加载器加载的IMDB数据集进行了分词处理,但不满足构造训练数据的需要,因此要对其进行额外的预处理。其中包含的预处理如下:
- 通过Vocab将所有的Token处理为index id。
- 将文本序列统一长度,不足的使用
<pad>补齐,超出的进行截断。
这里我们使用mindspore.dataset中提供的接口进行预处理操作。这里使用到的接口均为MindSpore的高性能数据引擎设计,每个接口对应操作视作数据流水线的一部分,详情请参考MindSpore数据引擎。 首先针对token到index id的查表操作,使用text.Lookup接口,将前文构造的词表加载,并指定unknown_token。其次为文本序列统一长度操作,使用PadEnd接口,此接口定义最大长度和补齐值(pad_value),这里我们取最大长度为500,填充值对应词表中<pad>的index id。
除了对数据集中
text进行预处理外,由于后续模型训练的需要,要将label数据转为float32格式。
import mindspore as ms
lookup_op = ds.text.Lookup(vocab, unknown_token='<unk>')
pad_op = ds.transforms.PadEnd([500], pad_value=vocab.tokens_to_ids('<pad>'))
type_cast_op = ds.transforms.TypeCast(ms.float32)
imdb_train = imdb_train.map(operations=[lookup_op, pad_op], input_columns=['text'])
imdb_train = imdb_train.map(operations=[type_cast_op], input_columns=['label'])
imdb_test = imdb_test.map(operations=[lookup_op, pad_op], input_columns=['text'])
imdb_test = imdb_test.map(operations=[type_cast_op], input_columns=['label'])
imdb_train, imdb_valid = imdb_train.split([0.7, 0.3])
模型构建
完成数据集的处理后,我们设计用于情感分类的模型结构。首先需要将输入文本(即序列化后的index id列表)通过查表转为向量化表示,此时需要使用nn.Embedding层加载Glove词向量;然后使用RNN循环神经网络做特征提取;最后将RNN连接至一个全连接层,即nn.Dense,将特征转化为与分类数量相同的size,用于后续进行模型优化训练。整体模型结构如下:
nn.Embedding -> nn.RNN -> nn.Dense
这里我们使用能够一定程度规避RNN梯度消失问题的变种LSTM(Long short-term memory)做特征提取层。下面对模型进行详解:
Embedding 嵌入 ¶
Embedding层又可称为EmbeddingLookup层,其作用是使用index id对权重矩阵对应id的向量进行查找,当输入为一个由index id组成的序列时,则查找并返回一个相同长度的矩阵,例如:
embedding = nn.Embedding(1000, 100) # 词表大小(index的取值范围)为1000,表示向量的size为100
input shape: (1, 16) # 序列长度为16
output shape: (1, 16, 100)
这里我们使用前文处理好的Glove词向量矩阵,设置nn.Embedding的embedding_table为预训练词向量矩阵。对应的vocab_size为词表大小400002,embedding_size为选用的glove.6B.100d向量大小,即100。
RNN(循环神经网络)
循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的神经网络。下图为RNN的一般结构:
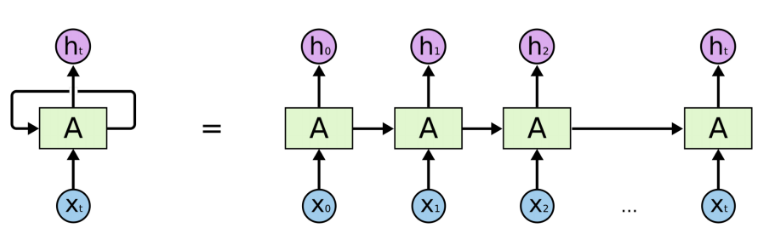
图示左侧为一个RNN Cell循环,右侧为RNN的链式连接平铺。实际上不管是单个RNN Cell还是一个RNN网络,都只有一个Cell的参数,在不断进行循环计算中更新。
由于RNN的循环特性,和自然语言文本的序列特性(句子是由单词组成的序列)十分匹配,因此被大量应用于自然语言处理研究中。下图为RNN的结构拆解:
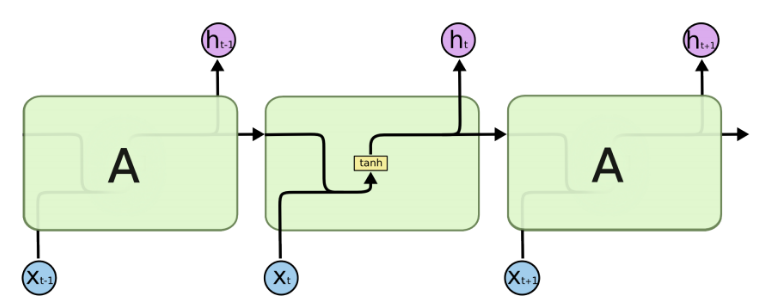
RNN单个Cell的结构简单,因此也造成了梯度消失(Gradient Vanishing)问题,具体表现为RNN网络在序列较长时,在序列尾部已经基本丢失了序列首部的信息。为了克服这一问题,LSTM(Long short-term memory)被提出,通过门控机制(Gating Mechanism)来控制信息流在每个循环步中的留存和丢弃。下图为LSTM的结构拆解:
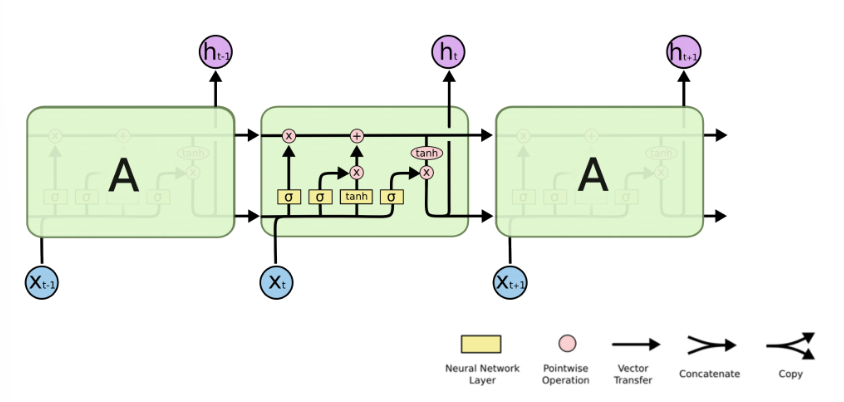
本节我们选择LSTM变种而不是经典的RNN做特征提取,来规避梯度消失问题,并获得更好的模型效果。下面来看MindSpore中nn.LSTM对应的公式:
这里nn.LSTM隐藏了整个循环神经网络在序列时间步(Time step)上的循环,送入输入序列、初始状态,即可获得每个时间步的隐状态(hidden state)拼接而成的矩阵,以及最后一个时间步对应的隐状态。我们使用最后的一个时间步的隐状态作为输入句子的编码特征,送入下一层。
Time step:在循环神经网络计算的每一次循环,成为一个Time step。在送入文本序列时,一个Time step对应一个单词。因此在本例中,LSTM的输出ℎ0:𝑡ℎ0:𝑡对应每个单词的隐状态集合,ℎ𝑡ℎ𝑡和𝑐𝑡𝑐𝑡对应最后一个单词对应的隐状态。
Dense 密集
在经过LSTM编码获取句子特征后,将其送入一个全连接层,即nn.Dense,将特征维度变换为二分类所需的维度1,经过Dense层后的输出即为模型预测结果。
有了准确率计算函数后,类似于训练逻辑,对评估逻辑进行设计, 分别为以下步骤:
- 读取一个Batch的数据;
- 送入网络,进行正向计算,获得预测结果;
- 计算准确率。
同训练逻辑一样,使用tqdm进行loss和过程的可视化。此外返回评估loss至供保存模型时作为模型优劣的判断依据。
在进行evaluate时,使用的模型是不包含损失函数和优化器的网络主体; 在进行evaluate前,需要通过
model.set_train(False)将模型置为评估状态,此时Dropout不生效。
模型训练与保存
前序完成了模型构建和训练、评估逻辑的设计,下面进行模型训练。这里我们设置训练轮数为5轮。同时维护一个用于保存最优模型的变量best_valid_loss,根据每一轮评估的loss值,取loss值最小的轮次,将模型进行保存。为节省用例运行时长,此处num_epochs设置为2,可根据需要自行修改。




RNN实现情感分类小结:
利用序列数据的时间动态特性来捕捉词与词之间的关系,从而实现对文本情感的识别。
原始文本转换为模型可以理解的格式,包括分词(Tokenization)、去除停用词(Stopwords Removal)、词干提取(Stemming)或词形还原(Lemmatization)等。
通过训练数据构建一个词汇表,将所有单词映射到唯一的整数索引。
将文本中的每个单词转换为向量形式。这可以通过 one-hot 编码、词嵌入(Word Embedding)如 Word2Vec 或 GloVe 来实现。
因为 RNN 需要固定长度的输入,所以需要将所有文本序列调整到相同的长度,这可以通过填充(Padding)或截断(Truncation)实现。
RNN 的隐藏状态可以表示整个序列的情感倾向,通过最后一个时间步的隐藏状态来进行分类。















 912
912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









