







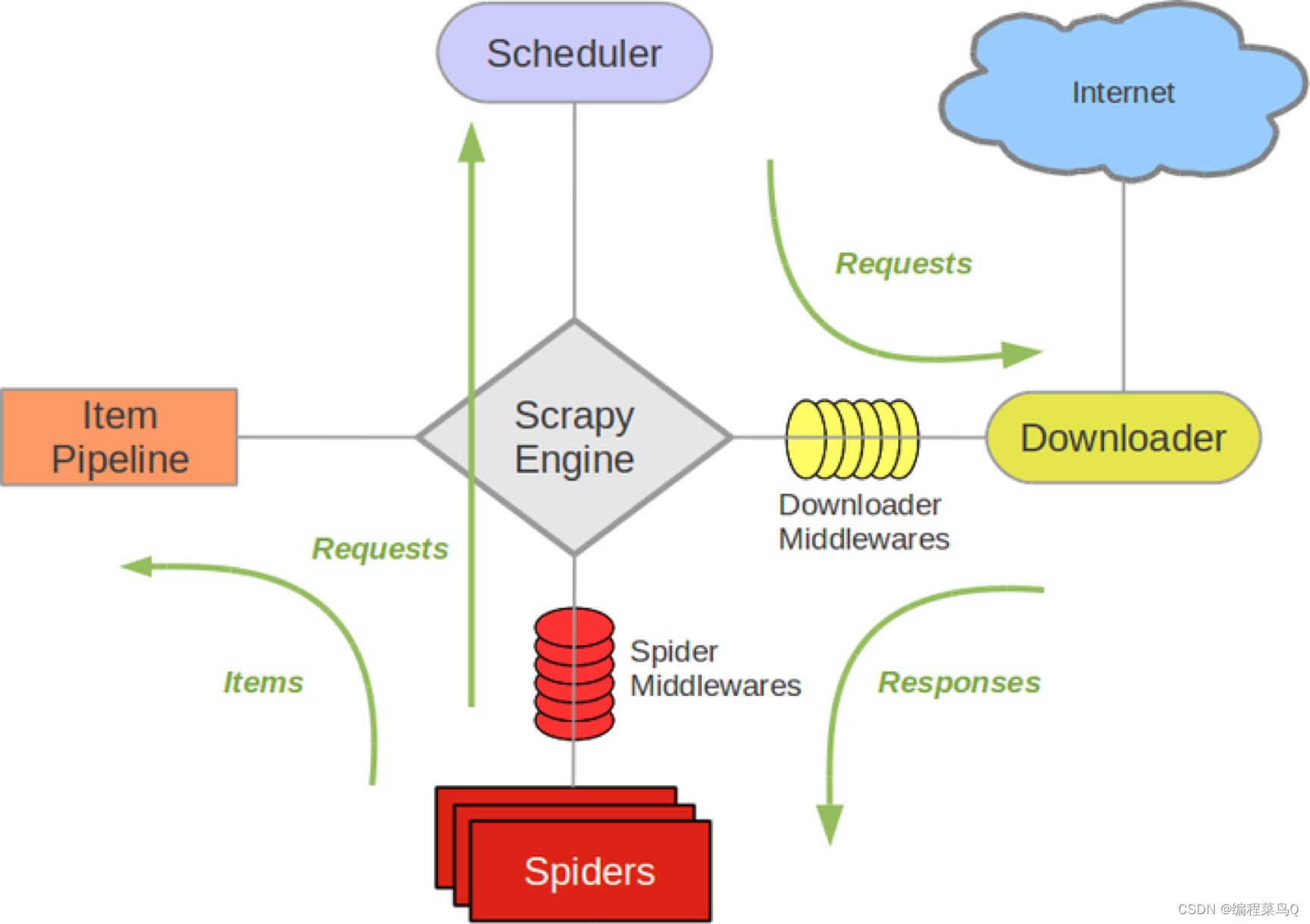
工作原理:
spiders--(发送请求url)--引擎---调度器--(请求)--下载器---互联网--(下载数据)
--下载器--(数据response)--(通过xpath解析数据)--spiders--(解析结果)
1--(数据)--管道(存放数据、数据库)
2--(url)--重复上述操作
案例:爬取汽车之家宝马汽车品牌和价格(xpath)
import scrapy
class CarSpider(scrapy.Spider):
name = "car"
allowed_domains = ["car.autohome.com.cn"]
#如果请求接口是以html为结尾的,不需要加 / 会报错
start_urls = ["https://car.autohome.com.cn/price/brand-15.html"]
def parse(self, response):
name_list = response.xpath('//div[@class="main-title"]/a/text()')
price_list = response.xpath('//span[@class="lever-price red"]/span/text()')[0]
for i in range(len(name_list)):
name = name_list[i]
price = price_list[i]
print(name,price)
结果图:
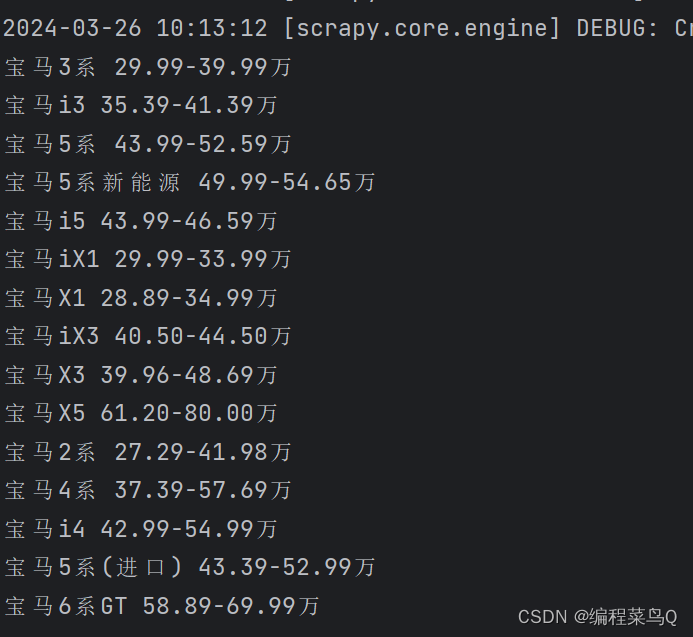
运行步骤:
D:\PycharmFile\爬虫学习> cd scrapy_093_carhomes\scrapy_093_carhomes\spiders
D:\PycharmFile\爬虫学习\scrapy_093_carhomes\scrapy_093_carhomes\spiders> scrapy crawl car















 803
803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









