






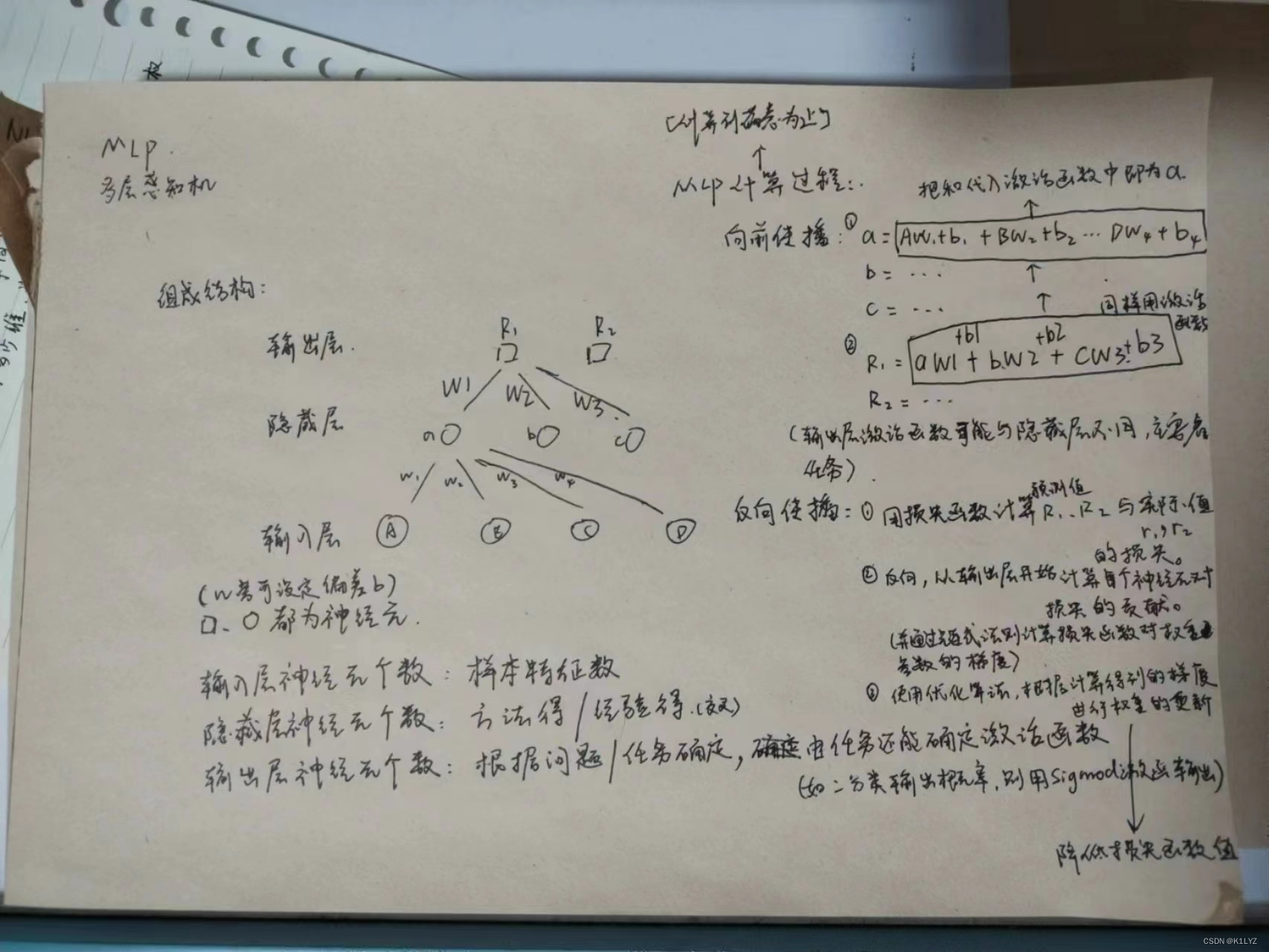



反向传播的一般推导过程:
假设我们有一个网络的输出为 y,真实标签为 t,损失函数为 L(y, t)。我们希望计算损失函数对于网络中某个参数 W 的梯度 ∂L/∂W。
使用链式法则,我们可以将梯度 ∂L/∂W 分解为多个小步骤的梯度相乘:
∂L/∂W = ∂L/∂y * ∂y/∂z * ∂z/∂W其中,z 是连接到参数 W 的输入,y 是经过激活函数后的输出。
依次计算上述三个项的梯度:
- ∂L/∂y:根据损失函数的形式计算损失相对于预测输出 y 的梯度。
- ∂y/∂z:根据激活函数的导数计算输出 y 相对于输入 z 的梯度。
- ∂z/∂W:根据网络结构计算输入 z 相对于参数 W 的梯度。
将这些项相乘,就可以得到参数 W 相对于损失函数的梯度 ∂L/∂W。
反向传播会沿着网络层层传递,计算每个参数的梯度。这些梯度将用于更新参数,以便最小化损失函数。
需要注意的是,不同的激活函数、损失函数和网络结构会导致不同的梯度计算方法。上述是一个简化的示例,实际中会更加复杂,但基本思想是通过链式法则将梯度从输出层向输入层传播,计算参数的梯度以进行优化。

1.梯度爆炸: 当权重值过大时,反向传播计算梯度时会涉及连乘操作,导致梯度值变得 非常大。这会导致权重更新的步幅过大,从而导致模型在训练中发散,无法收敛到合 适的解。梯度爆炸可能导致数值不稳定的情况,甚至使模型的权重变得无限大,从而失 去可用性。
2.梯度消失: 当权重值过小时,反向传播计算梯度时会涉及连乘操作,导致梯度值变得 非常小。这会使梯度在网络的较早层中逐渐减小,从而导致较早层的权重更新变得微 不足道,甚至趋近于零。这会导致模型在训练过程中无法对较早层进行有效的更新, 影响模型的训练效果,甚至导致模型无法学习到复杂的特征。
这些问题都会对模型的训练和性能产生严重影响。为了解决这些问题,常见的方法包括:
- 使用权重初始化方法,如 Xavier 初始化或 He 初始化,以确保权重在适当的范围内。
- 使用梯度裁剪技术,限制梯度的范围,防止梯度爆炸。
- 使用合适的激活函数,例如 ReLU 激活函数可以一定程度上缓解梯度消失问题。
- 使用批归一化等正则化技术,帮助稳定模型训练过程。
这些方法有助于防止梯度爆炸和梯度消失,从而使神经网络的训练过程更加稳定和可靠。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









