






参数初始化

激活函数(激活的本质就是进行非线性操作,挖掘出有用的潜在特征)
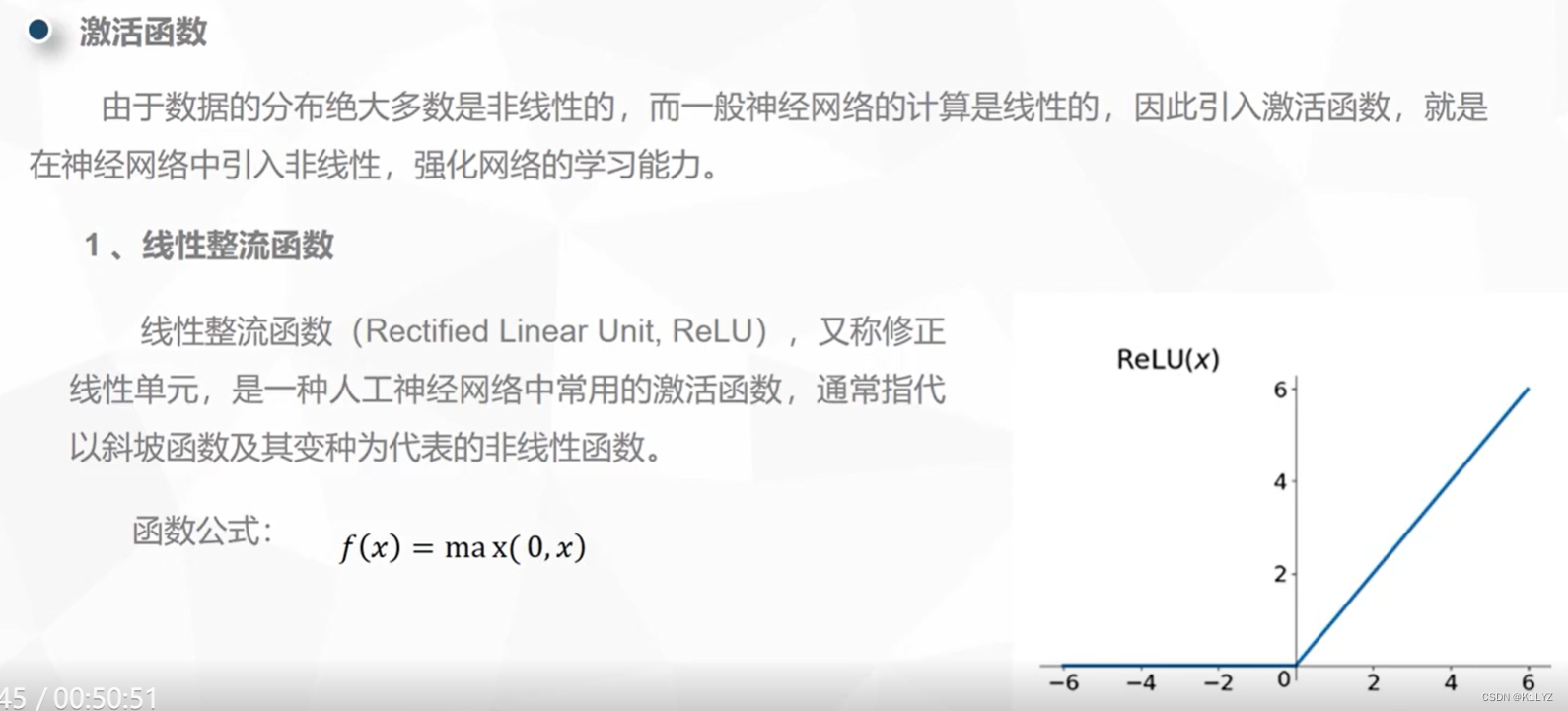
ReLU 具有以下特点:
非线性: 尽管 ReLU 函数看起来很简单,但它是一种非线性函数,因为其输出值在输入为负数时为 0,而在输入为正数时线性地增加。
计算高效: ReLU 的计算非常简单,只需要一个比较操作和一个数值赋值操作,因此在前向传播过程中计算效率高。
克服梯度消失问题: 与 Sigmoid 和 Tanh 等激活函数相比,ReLU 具有更大的梯度。这有助于缓解梯度消失问题,使得在深层网络中更容易传播梯度,从而促进训练。
稀疏激活性: 由于 ReLU 在输入小于 0 时输出为 0,它可以使一部分神经元变得不活跃,这有助于网络自动学习到稀疏的表示,从而提高网络的泛化能力。
然而,ReLU 也存在一些问题,如 "Dead ReLU" 问题,即某些神经元在训练过程中可能始终保持不活跃,以及 "Exploding Gradient" 问题,即在某些情况下可能会导致梯度爆炸。为了解决这些问题,出现了一些 ReLU 的变体,如 Leaky ReLU、Parametric ReLU、Exponential Linear Unit(ELU)等。
relu虽简单但是效果不俗,而且计算非常快(因为小于0的通通为零)
如果relu不理想,可以尝试用prelu或者elu

Sigmoid 函数具有以下特点:
取值范围: Sigmoid 函数的输出范围在 0 到 1 之间,这使其特别适用于表示概率或将输出映射到一个概率分布上。
平滑性: Sigmoid 函数是连续的、光滑的曲线,这使得它在计算梯度和反向传播时相对容易处理。
非线性: Sigmoid 函数是非线性的,这使得神经网络可以引入非线性变换,从而能够捕获复杂的数据关系。
中心化输出: Sigmoid 函数的输出以 0.5 为中心,即当输入接近 0 时,输出接近 0.5。这在某些情况下可能对网络的训练有所帮助。
梯度消失: 尽管 Sigmoid 函数是非线性的,但在输入值非常大或非常小的情况下,它的梯度会趋近于零,可能导致梯度消失问题。(倒数接近0时)
输出饱和: 当输入较大或较小时,Sigmoid 函数的输出会趋向于饱和状态,即接近于 0 或 1,这可能导致梯度消失和训练困难。
计算量大
尽管 Sigmoid 函数在某些场景中仍然有用,但由于其梯度消失问题和输出饱和问题,它在深度神经网络中的使用逐渐受到限制。在一些情况下,更现代的激活函数如 ReLU(Rectified Linear Unit)、Leaky ReLU、ELU(Exponential Linear Unit)等可能更常见,因为它们能够在更好地解决梯度消失问题的同时提供更快的收敛速度。
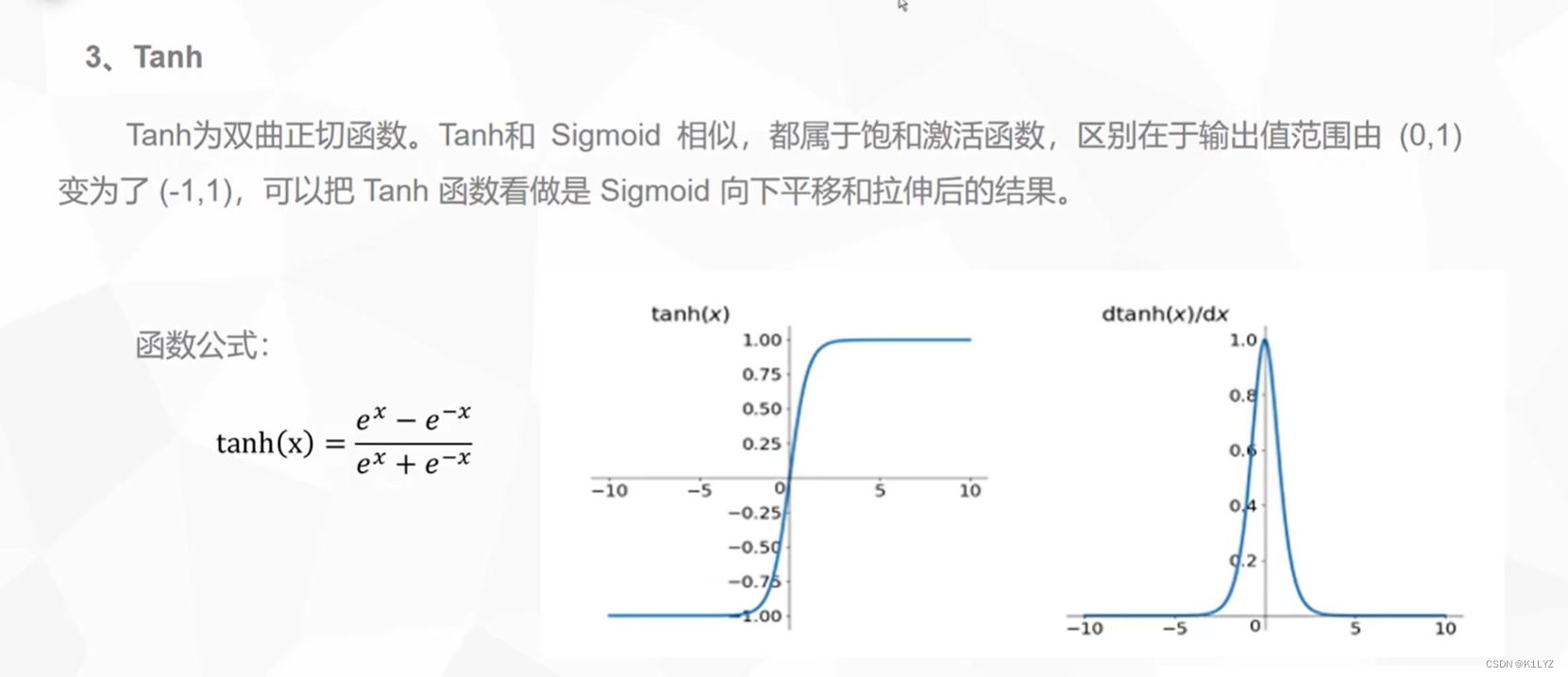
Tanh 函数在数学形式上类似于 Sigmoid 函数,但其输出范围在 -1 到 1 之间,因此可以说是 Sigmoid 函数的“零中心”版本。Tanh 函数具有以下特点:
非线性: 与 Sigmoid 函数一样,Tanh 函数是一种非线性函数,可以引入非线性变换,从而提高神经网络的表达能力。
零中心: 与 ReLU 函数不同,Tanh 函数在输入为 0 时输出也接近于 0,这有助于使激活值在正负方向上均匀分布。
范围限制: Tanh 函数的输出范围在 -1 到 1 之间,这使得它对于一些问题比 Sigmoid 函数更适用,如将输出映射到一个有界的范围。
梯度消失: 与 Sigmoid 函数类似,当输入值非常大或非常小时,Tanh 函数的梯度会趋近于零,可能导致梯度消失问题。
损失函数


















 1524
1524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









