






在Datawhale X 李宏毅苹果书 AI夏令营的深度学习入门任务中,我们通过一个具体的例子来深入了解机器学习的基础概念。这个任务不仅帮助我们理解了机器学习的工作原理,还让我们实际操作了如何通过机器学习解决实际问题。
首先,我们了解到机器学习的核心是找到一个合适的函数(模型),让机器能够根据输入自动解决问题。例如,在语音识别、图片识别或围棋游戏中,机器学习模型能够将输入(语音、图片、棋盘状态)转换为输出(文字、图片内容、下一步棋)。
在这个过程中,我们学习了几种不同类型的函数,包括回归和分类:
1.回归:当模型需要预测一个数值时,如预测未来的PM2.5值。
2.分类:当模型需要在几个预设选项中选择一个时,如判断邮件是否为垃圾邮件。
此外,我们还了解了机器学习中的一些关键概念,如权重(weight)、偏置(bias)、学习率(learning rate)、超参数(hyperparameters)、全局最小值和局部最小值等。这些概念帮助我们更深入地理解了如何调整和优化我们的模型。
通过李宏毅教授的案例,我们学习了如何使用梯度下降这一优化技术来找到最佳的模型参数。梯度下降通过反复迭代,逐步调整参数以最小化损失函数的值,从而找到最合适的模型参数。
总之,通过完成这个任务,我们不仅掌握了机器学习的基本概念和应用,也对如何在实际问题中应用机器学习有了更深的理解。这对于任何希望在AI领域深入学习的人来说,都是非常宝贵的经验。
在未来的学习中,我期待能够继续探索更多关于机器学习的高级主题,并尝试将这些知识应用于解决现实世界的问题。机器学习作为人工智能的一个重要分支,正在不断发展和进步,我相信通过不断学习和实践,我们可以更好地利用这些强大的工具,创造出更多有价值的应用。
问题简述:机器学习的视频被放到youtub中,需要学习的同学就要去看这个视频,从而产生播放量,那么能不能根据已有的数据预测未来的播放量是我们需要解决的问题
1.首先设一个函数
y=w*x+b
y是需要预测的数值(这里假设为需要预测这个频道今天的观看总次数),x是昨天这个频道的观看总次数
w,b都是未知参数
2.定义损失函数loss
简单说就是用来衡量预测值和真实值之间差值的一个数值,根据损失值可以评估假设出来的模型的好坏
这个函数的输入是模型里面的参数,模型是 y = b + w ∗ x1,而 b 跟 w 是未知的,损失是函数 L(b, w),其输入是模型参数 b 跟w。损失函数输出的值代表,现在如果把这一组未知的参数,设定某一个数值的时候,这笔数值好还是不好。举一个具体的例子,假设未知的参数的设定是 b = 500,w = 1,预测未来的观看次数的函数就变成 y = 500 + x1。要从训练数据来进行计算损失,在这个问题里面,训练数据是这一个频道过去的观看次数。
举个例子,从 2017 年 1 月 1 日到 2020 年 12 月 31 日的观看次数(此处的数字是随意生成的)接下来就可以计算损失。

把 2017 年 1 月 1 日的观看次数,代入这一个函数里面yˆ = 500 + 1x1 可以判断 b = 500,w = 1 ,x1 代入 4800,预测隔天实际上的观看次数结果为 yˆ = 5300,但是真正的结果是 4900,真实的值称为标签(label),它高估了这个频道可能的点击次数
也可以计算一下估测的值 yˆ 跟真实值 y 的差距 e。e1 = |y − yˆ| = 400
我们可以算过这 3 年来,每一天的预测的误差,这 3 年来每一天的误差,通通都可以算出来,每一天的误差都可以得到 e。接下来把每一天的误差,通通加起来取得平均,得到损失L=
N代表训练数据的个数 L越大,那么训练出来的这个参数越不好,L越小训练出来的参数越好
计算误差的其他方法:
估测的值跟实际的值之间的差距,其实有不同的计算方法
计算 y 与 yˆ 之间绝对值的差距,称为平均绝对误差(Mean Absolute Error,MAE)。
e =
计算 y 与 yˆ 之间平方的差距,则称为均方误差(Mean SquaredError,MSE)。
e =
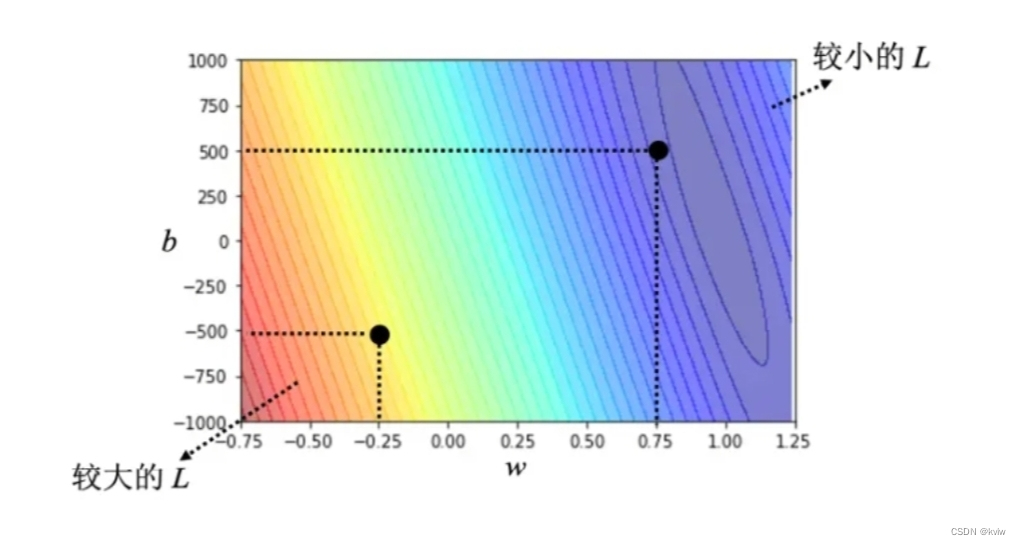
下面我们用一些真实数据来演示一下这个过程:下图是这个频道真实的后台的数据,所计算出来的结果。可以调整不同的 w 和不同的 b,求取各种w 和各种 b,组合起来以后,我们可以为不同的 w 跟 b 的组合,都去计算它的损失,就可以画出如下图所示的等高线图。在这个等高线图上面,越偏红色系,代表计算出来的损失越大,就代表这一组 w 跟 b 越差。如果越偏蓝色系,就代表损失越小,就代表这一组 w 跟 b 越好,拿这一组 w 跟 b,放到函数里面,预测会越精准。假设 w = −0.25, b = −500,这代表这个频道每天看的人越来越少,而且损失这么大,跟真实的情况不太合。如果 w = 0.75, b = 500,估测会比较精准。如果 w 代一个很接近 1 的值,b 带一个小小的值,比如说 100 多,这个时候估测是最精准的,这跟大家的预期可能是比较接近的,就是拿前一天的点击的总次数,去预测隔天的点击的总次数,可能前一天跟隔天的点击的总次数是差不多的,因此 w 设 1,b 设一个小一点的数值,也许估测就会蛮精准的。如下图所示的等高线图,就是试了不同的参数,计算它的损失,画出来的等高线图称为误差表面(error surface)。这是机器学习的第 2 步。
3.优化
解一个最优化的问题。找一个 w 跟 b,把未知的参数找一个数值出来,看代哪一个数值进去可以让损失 L 的值最小,就是要找的 w 跟 b。
梯度下降(gradient descent)是经常会使用优化的方法。
为了要简化起见,先假设只有一个未知的参数 w,b 是已知的。w 代不同的数值的时候,就会得到不同的损失,这一条曲线就是误差表面,只是刚才在前一个例子里面,误差表面是 2 维的,这边只有一个参数,所以这个误差表面是 1 维的。
怎么样找一个 w 让损失的值最小呢?
首先要随机选取一个初始的点 。接下来计算
,在 w 等于
的时候,参数 w 对损失的微分。计算在这一个点,在
这个位置的误差表面的切线斜率,也就是这一条蓝色的虚线,它的斜率,如果这一条虚线的斜率是负的,代表说左边比较高,右边比较低。在这个位置附近,左边比较高,右边比较低。如果左边比较高右边比较低的话,就把 w 的值变大,就可以让损失变小。如果算出来的斜率是正的,就代表左边比较低右边比较高。左边比较低右边比较高,如果左边比较低右边比较高的话,就代表把 w 变小了,w 往左边移,可以让损失的值变小。这个时候就应该把 w 的值变小。我们可以想像说有一个人站在这个地方,他左右环视一下,算微分就是左右环视,它会知道左边比较高还是右边比较高,看哪边比较低,它就往比较低的地方跨出一步。这一步的步伐的大小取决于两件事情:
• 第一件事情是这个地方的斜率,斜率大步伐就跨大一点,斜率小步伐就跨小一点。
• 另外,学习率(learning rate)η 也会影响步伐大小。学习率是自己设定的,如果 η 设大一点,每次参数更新就会量大,学习可能就比较快。如果 η 设小一点,参数更新就很慢,每次只会改变一点点参数的数值。这种在做机器学习,需要自己设定,不是机器自己找出来的,称为超参数(hyperparameter)。
把 w0 往右移一步,新的位置为 w1,这一步的步伐是 η 乘上微分的结果,即:
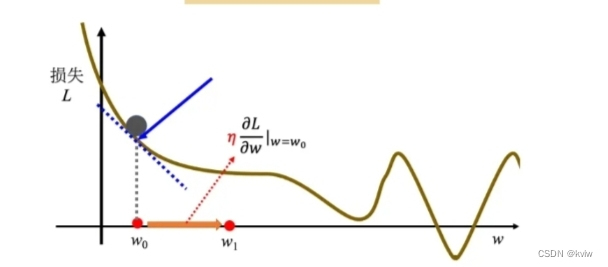 接下来反复进行刚才的操作,计算一下 w1 微分的结果,再决定现在要把 w1 移动多少,再移动到 w2,再继续反复做同样的操作,不断地移动 w 的位置,最后会停下来。往往有两种情况会停下来。
接下来反复进行刚才的操作,计算一下 w1 微分的结果,再决定现在要把 w1 移动多少,再移动到 w2,再继续反复做同样的操作,不断地移动 w 的位置,最后会停下来。往往有两种情况会停下来。
第一种情况是一开始会设定说,在调整参数的时候,在计算微分的时候,最多计算几次。上限可能会设为 100 万次,参数更新 100 万次后,就不再更新了,更新次数也是一个超参数。
• 还有另外一种理想上的,停下来的可能是,当不断调整参数,调整到一个地方,它的微分的值就是这一项,算出来正好是 0 的时候,如果这一项正好算出来是 0,0 乘上学习率 η 还是 0,所以参数就不会再移动位置。假设是这个理想的情况,把 w0 更新到 w1,再更新到 w2,最后更新到 wT 有点卡,wT 卡住了,也就是算出来这个微分的值是 0 了,参数的位置就不会再更新。
梯度下降有一个很大的问题,没有找到真正最好的解,没有找到可以让损失最小的 w。在图 1.4 所示的例子里面,把 w 设定在最右侧红点附近这个地方可以让损失最小。但如果在梯度下降中,w0 是随机初始的位置,也很有可能走到 wT 这里,训练就停住了,无法再移动 w 的位置。右侧红点这个位置是真的可以让损失最小的地方,称为全局最小值(global minima),而 wT 这个地方称为局部最小值(local minima),其左右两边都比这个地方的损失还要高一点,但是它不是整个误差表面上面的最低点。















 209
209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









