







目录
char LICENSE[] SEC("license") = "Dual BSD/GPL"
__attribute__((section("kprobe/do_unlinkat"), used))
__attribute__((always_inline))
return ____do_unlinkat(ctx, (void *)((ctx)->di), (void *)((ctx)->si))
return ____do_unlinkat_exit(ctx, (void *)((ctx)->ax))
libbpf_set_print(libbpf_print_fn);
kprobes
引入
开发人员在内核或者模块的调试过程中,往往会需要要知道其中的一些函数有无被调用、何时被调用、执行是否正确以及函数的入参和返回值是什么等等
- 比较简单的做法是在内核代码对应的函数中添加日志打印信息,但这种方式往往需要重新编译内核或模块,重新启动设备之类的
- 操作较为复杂甚至可能会破坏原有的代码执行过程
- 但利用kprobes技术,用户可以定义自己的回调函数,然后在内核或者模块中几乎所有的函数中动态地插入探测点
- 当内核执行流程执行到指定的探测函数时,会调用该回调函数,用户即可收集所需的信息,同时内核最后还会回到原本的正常执行流程
介绍
Kprobes是Linux内核中的一个功能,它允许开发人员在内核空间中进行动态的代码跟踪和调试
- 可以在内核代码的任何位置插入调试代码,以便监视和调试内核中发生的事件或特定函数的执行情况
- 一般是在函数的入口/出口处插入钩子(也可以叫探测点),利用注册的回调函数,知道内核函数是否被调用,被调用上下文,入参以及返回值
三种探测手段
kprobes 技术包括的3种探测手段分别是 kprobe、jprobe 和 kretprobe
kprobe
kprobe 是最基本的探测方式,是实现后两种的基础
- 它可以在任意的位置放置探测点(就连函数内部的某条指令处也可以)
- 它提供了探测点的调用前、调用后和内存访问出错3种回调方式,分别是
pre_handler、post_handler和fault_handler其中
pre_handler函数将在被探测指令被执行前回调post_handler会在被探测指令执行完毕后回调(注意不是被探测函数)fault_handler会在内存访问出错时被调用示例代码
/* * NOTE: This example is works on x86 and powerpc. * Here's a sample kernel module showing the use of kprobes to dump a * stack trace and selected registers when do_fork() is called. * * For more information on theory of operation of kprobes, see * Documentation/kprobes.txt * * You will see the trace data in /var/log/messages and on the console * whenever do_fork() is invoked to create a new process. */ #include <linux/kernel.h> #include <linux/module.h> #include <linux/kprobes.h> /* For each probe you need to allocate a kprobe structure */ static struct kprobe kp = { .symbol_name = "do_fork", }; /* kprobe pre_handler: called just before the probed instruction is executed */ static int handler_pre(struct kprobe *p, struct pt_regs *regs) { #ifdef CONFIG_X86 printk(KERN_INFO "pre_handler: p->addr = 0x%p, ip = %lx," " flags = 0x%lx\n", p->addr, regs->ip, regs->flags); #endif #ifdef CONFIG_PPC printk(KERN_INFO "pre_handler: p->addr = 0x%p, nip = 0x%lx," " msr = 0x%lx\n", p->addr, regs->nip, regs->msr); #endif /* A dump_stack() here will give a stack backtrace */ return 0; } /* kprobe post_handler: called after the probed instruction is executed */ static void handler_post(struct kprobe *p, struct pt_regs *regs, unsigned long flags) { #ifdef CONFIG_X86 printk(KERN_INFO "post_handler: p->addr = 0x%p, flags = 0x%lx\n", p->addr, regs->flags); #endif #ifdef CONFIG_PPC printk(KERN_INFO "post_handler: p->addr = 0x%p, msr = 0x%lx\n", p->addr, regs->msr); #endif } /* * fault_handler: this is called if an exception is generated for any * instruction within the pre- or post-handler, or when Kprobes * single-steps the probed instruction. */ static int handler_fault(struct kprobe *p, struct pt_regs *regs, int trapnr) { printk(KERN_INFO "fault_handler: p->addr = 0x%p, trap #%dn", p->addr, trapnr); /* Return 0 because we don't handle the fault. */ return 0; } static int __init kprobe_init(void) { int ret; kp.pre_handler = handler_pre; kp.post_handler = handler_post; kp.fault_handler = handler_fault; ret = register_kprobe(&kp); if (ret < 0) { printk(KERN_INFO "register_kprobe failed, returned %d\n", ret); return ret; } printk(KERN_INFO "Planted kprobe at %p\n", kp.addr); return 0; } static void __exit kprobe_exit(void) { unregister_kprobe(&kp); printk(KERN_INFO "kprobe at %p unregistered\n", kp.addr); } module_init(kprobe_init) module_exit(kprobe_exit) MODULE_LICENSE("GPL");
jprobe
基于 kprobe 实现,它用于获取被探测函数的入参值
Kretprobe
是Kprobe的补充,它允许在函数返回时插入调试代码
查看支持的函数
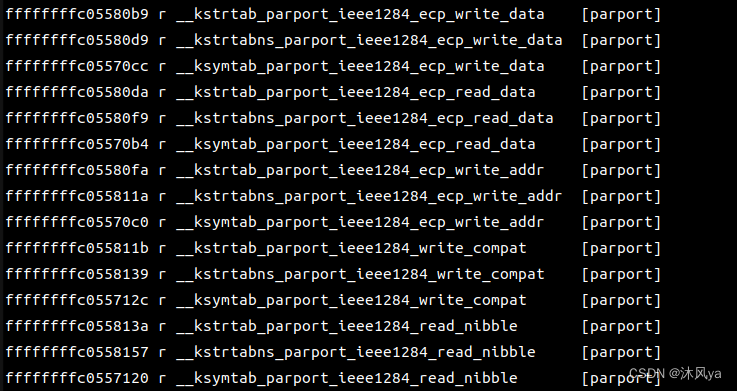
不是所有的函数都支持kprobe机制,可以通过cat查看当前系统支持的函数
cat /sys/kernel/debug/tracing/available_filter_functions
原理
内核函数会像用户态暴露自己的内存地址
- 查看暴露的内核函数地址:cat /proc/kallsyms
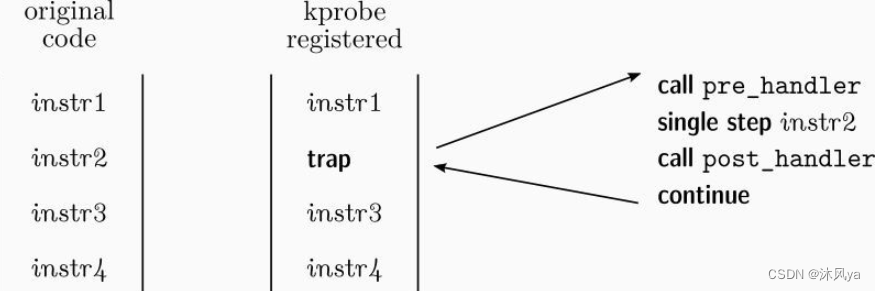
- Kprobes通过访问内核函数的内存地址,即可向可探测的内核函数的某个位置增加断点(一组回调函数)
- 当实际执行到放置探测点的内核函数的断点时,跳转指令会跳转到Kprobes句柄注册的探测函数(内存地址)上
- 而后执行结束,再利用句柄跳转回原来的上下文
- 像触发了中断机制一样
- 也可以理解成就是在函数开始/返回时调用了函数
ebpf的kprobe
引入
在 eBPF 中,Kprobe 也是一种类型的探测点,用于在指定的内核函数入口或出口插入探测点,并执行用户定义的 eBPF 程序
- eBPF Kprobe 提供了比传统 Kprobes 更丰富的功能和灵活性,可以编写更复杂的程序来处理探测点触发时的事件
- 使用ebpf,可以更方便的使用kprobe机制
以下是libbpf-bootstrap库中的kprobe示例代码:
运行情况
就是在执行文件删除时,会调用底层的do_unlinkat内核函数
- 如果我们将探测点设置在该函数的入/出口处,就会在内核日志中看到自定义的打印信息

代码解释
.bpf.c
源码
// SPDX-License-Identifier: GPL-2.0 OR BSD-3-Clause /* Copyright (c) 2021 Sartura */ #include "vmlinux.h" #include <bpf/bpf_helpers.h> #include <bpf/bpf_tracing.h> #include <bpf/bpf_core_read.h> char LICENSE[] SEC("license") = "Dual BSD/GPL"; SEC("kprobe/do_unlinkat") int BPF_KPROBE(do_unlinkat, int dfd, struct filename *name) { pid_t pid; const char *filename; pid = bpf_get_current_pid_tgid() >> 32; filename = BPF_CORE_READ(name, name); bpf_printk("KPROBE ENTRY pid = %d, filename = %s\n", pid, filename); return 0; } SEC("kretprobe/do_unlinkat") int BPF_KRETPROBE(do_unlinkat_exit, long ret) { pid_t pid; pid = bpf_get_current_pid_tgid() >> 32; bpf_printk("KPROBE EXIT: pid = %d, ret = %ld\n", pid, ret); return 0; }这就是在某个函数入口和出口处分别注册的两个函数的定义
语法 / 函数接口
char LICENSE[] SEC("license") = "Dual BSD/GPL"
将许可证信息与特定的eBPF程序相关联,确保对程序的合适授权和管理
- 定义了一个名为LICENSE的全局字符数组
- "license"是一个自定义的安全上下文名称,用于将字符数组与特定的上下文相关联(这里其实不太懂原理,可能就是把它存起来让内核识别了??)
- "Dual BSD/GPL" -- 指示eBPF程序的许可证类型
- 总之,记住在写代码时不要漏掉这个许可证即可
SEC
SEC(Security)用于定义eBPF程序的安全上下文
- 相当于是一种通行证,告诉内核ebpf程序接下来的行为,以确定被允许进入哪些区域,执行哪些操作
- 指定程序是否可以访问特定的系统资源(如内存、网络、文件系统)、是否可以执行特定的系统调用,以及程序在执行时是否需要特权等
- 他其实是一种宏定义,在下面查看预编译代码中会讲到
SEC("kprobe/do_unlinkat")
是eBPF程序中的一种语法 -- ("kprobe形式/要挂接的内核函数名")
- 它指定了一个eBPF程序应该连接到哪个内核函数
- 注意是内核函数,而不是系统调用
系统调用和内核函数的区别
- 内核函数是由操作系统内核提供的函数,用于执行特定的内核操作,这些函数可以直接在内核空间中被调用,一般是提供给其他内核模块或内核中的其他部分使用
- 系统调用是用户空间程序通过软中断或陷阱方式请求操作系统内核提供的服务的接口,它们允许用户空间程序访问内核空间的功能
动态kprobe的两种插入形式
- "kprobe"表示将该eBPF程序连接到内核中的"do_unlinkat"函数的入口处
- "kretprobe"表示将该eBPF程序连接到该函数的出口处(也就是即将返回时会调用该函数)
do_unlinkat
是一个内核函数,用于实现unlinkat系统调用的功能
int unlinkat(int dirfd, const char *pathname, int flags);
- dirfd 是一个文件描述符,它引用了一个目录
- pathname 是要删除的文件或者目录的路径
- flags 可以是 0,也可以是 AT_REMOVEDIR
- 如果是 AT_REMOVEDIR,那么 pathname 就会被当作目录处理
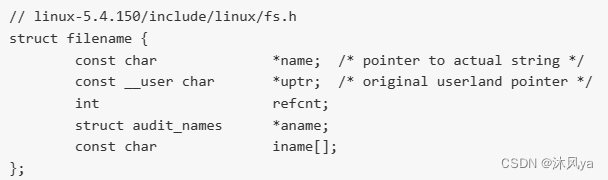
filename结构体
是内核中存放文件名的结构体
- name字段就是存放文件名的字符串
BPF_KPROBE
一个宏定义
- 使用BPF的Kprobe的声明语句,格式是 -- (探针函数名,该函数的参数列表)
- 这样在预编译后,编译器会自动为我们生成这样一个函数,作为探测函数
bpf_get_current_pid_tgid()
可以在eBPF程序中获取当前执行程序(也就是调用了do_unlinkat内核函数的进程)的PID和TGID,以便进行进程相关的操作或统计
- 比如:可以筛选特定进程,计算进程的资源使用情况等
BPF_CORE_READ ()
读取内核中的数据
- 是一个宏定义
- 原型类似于:
#define BPF_CORE_READ(struct_name, field_name) \ ({ \ typeof(struct_name.field_name) _val; \ bpf_probe_read(&_val, sizeof(_val), ((void *)bpf_core_field(struct_name, field_name))); \ _val; \ })意思是读取内核中某个核心数据结构的字段,将其作为返回值返回
filename = BPF_CORE_READ(name, name)就是指拿到文件名,而这个文件名被定义在name结构体(就是上面的filename结构体,它指针名字叫name)里的name字段

bpf_printk
用于在内核日志(trace_pipe(/sys/kernel/debug/tracing/trace_pipe))中打印消息
- 内核日志也可以叫做内核环形缓冲区
- 相当于就是c语言中printf -- 将数据拷贝到标准输出流中,它通常被重定向到终端设备,所以可以将它刷新到显示器上
- 可以输出实时的内核跟踪事件数据流
- 最多只能有三个参数
.bpf.i
编译语句
- 相当于就是在最后一句里加-E选项,目标文件名改为.bpf.i
源码 -- 入口处函数
__attribute__((section("kprobe/do_unlinkat"), used)) //函数声明 int do_unlinkat(struct pt_regs *ctx); static inline __attribute__((always_inline)) typeof(do_unlinkat(0)) ____do_unlinkat(struct pt_regs *ctx, int dfd, void *name); //函数体 typeof(do_unlinkat(0)) do_unlinkat(struct pt_regs *ctx) { return ____do_unlinkat(ctx, (void *)((ctx)->di), (void *)((ctx)->si)); } static inline typeof(do_unlinkat(0))____do_unlinkat(struct pt_regs *ctx, int dfd, struct filename *name) { pid_t pid; const char *filename; pid = bpf_get_current_pid_tgid() >> 32; filename = ({ typeof((name)->name) __r; ({ bpf_probe_read_kernel((void *)(&__r), sizeof(*(&__r)), (const void *)__builtin_preserve_access_index(&((typeof(((name))))(((name))))->name)); }); __r; }); ({ static const char ____fmt[] = "KPROBE ENTRY pid = %d, filename = %s\n"; bpf_trace_printk(____fmt, sizeof(____fmt), pid, filename); }); return 0; }相当于就是把自己定义的参数和函数体放在____do_unlinkat,自动生成一个do_unlinkat进行回调
- 但是注意,参数列表有变化:之前写的do_unlinkat字段变成了一个pt_regs结构体
语法
__attribute__((section("kprobe/do_unlinkat"), used))
这个就是SEC的宏展开
- 将变量或函数放置在指定的 ELF 节(section)
- used -- 确保它在链接过程中被使用
__attribute__((always_inline))
指示编译器始终内联此函数
typeof(do_unlinkat(0))
- 返回do_unlinkat函数的返回值类型
- 相当于是动态获取函数的返回值类型,而不是写死的
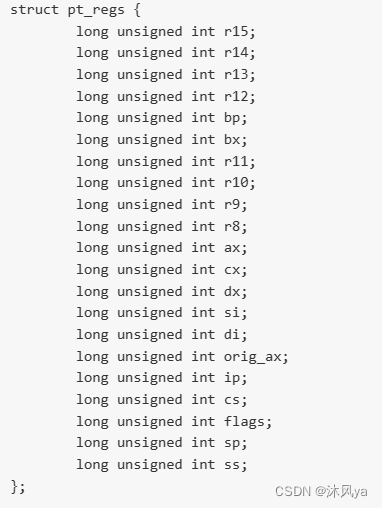
pt_regs
- 自动生成的do_unlinkat函数的参数类型(一个结构体指针)
- 通常用于保存处理系统调用或中断时的寄存器状态
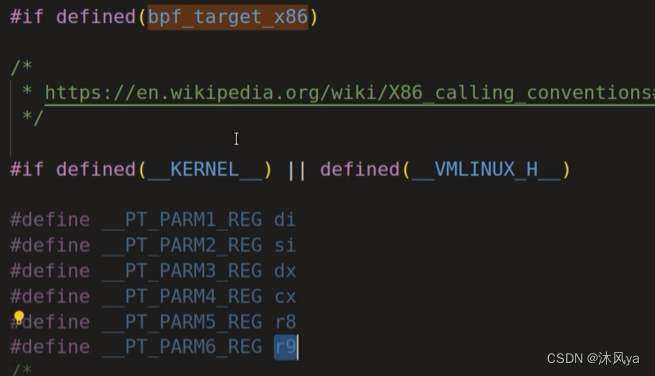
- 还可以看看这个定义:
- 可以把这六个字段看作是系统调用时的参数顺序
- (说实话不太懂,照猫画虎着写吧)
- 或者也可以使用宏提取参数 -- PT_REGS_PARM1(pt_regs结构体指针)

return ____do_unlinkat(ctx, (void *)((ctx)->di), (void *)((ctx)->si))
- 总之,我们可以发现,我们传入的参数,其实都是在编译时自动帮我们获取并传参了
- 核心就是 pt_regs 结构体
____fmt
占位符,用于表示消息的格式化字符串
- 定义消息的格式,以便在bpf_trace_printk中使用
bpf_trace_printk
eBPF 程序中的辅助函数
- 用于将消息打印到内核日志中
- 最多只能传三个参数

修改.bpf.c中入口处的函数定义
其实从预编译代码可以看出来,我们自定义的函数最重要的其实就是函数体,而参数都可以从pt_regs 结构体中获得
所以,我们可以考虑修改修改这个函数
SEC("kprobe/do_unlinkat") int test(struct pt_regs *ctx) { pid_t pid; const char *filename; struct filename *name = (struct filename *)(ctx->si); pid = bpf_get_current_pid_tgid() >> 32; filename = BPF_CORE_READ(name, name); bpf_printk("KPROBE ENTRY-test pid = %d, filename = %s\n", pid, filename); return 0; }
- 函数名可以随意起
- 参数其实只要有个pt_regs 结构体指针就行,而且不用加do_unlinkat(因为已经指定过要连接的是哪个内核函数)
- 需要的文件名信息可以手动提取出来
预编码代码
__attribute__((section("kprobe/do_unlinkat"), used)) int test(struct pt_regs *ctx) { pid_t pid; const char *filename = (const char *)(ctx->si); pid = bpf_get_current_pid_tgid() >> 32; ({ static const char ____fmt[] = "KPROBE ENTRYpid = %d, filename = %s\n"; bpf_trace_printk(____fmt, sizeof(____fmt), pid, filename); }); return 0; }可以看出来,我们写的代码其实就和处理后代码很相近了
源码 -- 出口处函数
__attribute__((section("kretprobe/do_unlinkat"), used)) typeof(do_unlinkat_exit(0)) do_unlinkat_exit(struct pt_regs *ctx) { return ____do_unlinkat_exit(ctx, (void *)((ctx)->ax)); } static inline attribute__((always_inline)) typeof(do_unlinkat_exit(0)) ____do_unlinkat_exit(struct pt_regs *ctx, long ret) { pid_t pid; pid = bpf_get_current_pid_tgid() >> 32; ({ static const char ____fmt[] = "KPROBE EXIT: pid = %d, ret = %ld\n"; bpf_trace_printk(____fmt, sizeof(____fmt), pid, ret); }); return 0; }
语法
基本和入口处那的差不多
return ____do_unlinkat_exit(ctx, (void *)((ctx)->ax))
总之就是,先记住这些寄存器的用法

.c
源码
// SPDX-License-Identifier: (LGPL-2.1 OR BSD-2-Clause) /* Copyright (c) 2021 Sartura * Based on minimal.c by Facebook */ #include <stdio.h> #include <unistd.h> #include <signal.h> #include <string.h> #include <errno.h> #include <sys/resource.h> #include <bpf/libbpf.h> #include "kprobe.skel.h" static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args) { return vfprintf(stderr, format, args); } static volatile sig_atomic_t stop; static void sig_int(int signo) { stop = 1; } int main(int argc, char **argv) { struct kprobe_bpf *skel; int err; /* Set up libbpf errors and debug info callback */ libbpf_set_print(libbpf_print_fn); /* Open load and verify BPF application */ skel = kprobe_bpf__open_and_load(); if (!skel) { fprintf(stderr, "Failed to open BPF skeleton\n"); return 1; } /* Attach tracepoint handler */ err = kprobe_bpf__attach(skel); if (err) { fprintf(stderr, "Failed to attach BPF skeleton\n"); goto cleanup; } if (signal(SIGINT, sig_int) == SIG_ERR) { //防止自定义信号处理方法失败 fprintf(stderr, "can't set signal handler: %s\n", strerror(errno)); goto cleanup; } printf("Successfully started! Please run `sudo cat /sys/kernel/debug/tracing/trace_pipe` " "to see output of the BPF programs.\n"); while (!stop) { //如果没有收到SIGINT信号,就会打印.以表示自己仍在运行中(ebpf程序依然还挂载在内核中) fprintf(stderr, "."); sleep(1); } cleanup: kprobe_bpf__destroy(skel); return -err; }
语法
libbpf_print_fn()

volatile
表示该变量可能会被异步修改,告诉编译器不要进行优化
sig_atomic_t
保证了对该变量的读取和写入是原子操作的,即不会被信号中断
kprobe_bpf
表示一个 kprobe(内核探测点)的 eBPF 程序
- 在使用 eBPF 进行 kprobe 事件跟踪时,通常会创建一个包含相应逻辑的结构体
- 相当于是用于管理eBPF程序的一个结构体,可以把它和进程的tcb进行类比
- 它是在.skel.中定义的,说明它会根据内核层代码自动生成,里面会存放用于管理和操作 bpf程序的字段
libbpf_set_print(libbpf_print_fn);
将自定义的打印函数传递给libbpf库,以便其在执行过程中使用
其中的level参数,是一个枚举类型:


















 1130
1130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









