






 本文详细介绍了决策树中的ID3(信息增益)和CART(基尼指数)算法,包括如何构建决策树、特征选择过程以及在Python中的实现示例。ID3更倾向于信息增益,而CART使用基尼系数来评估纯度。
本文详细介绍了决策树中的ID3(信息增益)和CART(基尼指数)算法,包括如何构建决策树、特征选择过程以及在Python中的实现示例。ID3更倾向于信息增益,而CART使用基尼系数来评估纯度。
1.概述
决策树(Decision Tree)是一种基本的分类与回归方法,决策树模型呈树形结构,在分类问题中,表示基于特征对数据进行分类的过程。它可以认为是if-then规则的集合。每个内部节点表示在属性上的一个测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
2.如何构建决策树
决策树构建的基本步骤如下:
1. 开始,所有记录看作一个节点
2. 遍历每个特征的每一种分裂方式,找到最好的分裂特征(分裂点)
3. 分裂成两个或多个节点
4. 对分裂后的节点分别继续执行2-3步,直到每个节点足够“纯”为止
具体实践中,到底选择哪个特征作为当前分裂特征,常用的有下面三种算法:
信息增益(ID3)
假设训练数据集D和特征A,根据如下步骤计算信息增益:
第一步:计算数据集的经验熵:
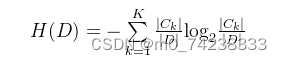
其中,为第
类样本的数目,
为数据集D的数目。
第二步:计算特征A对数据集D的经验条件熵H(D|A):
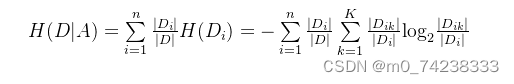
第三步:计算信息增益:
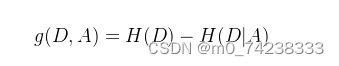
一般而言,信息增益越大,则意味着使用属性A来进行划分所获得的“纯度提升” 越大。因此,我们可使用信息增益来进行决策树的划分属性选择。ID3决策树学习算法就是以信息增益为准则来选择划分属性的。
信息增益率(C4.5)
特征A对于数据集D的信息增益比定义为:
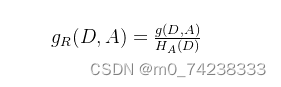
其中,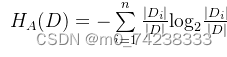 称为数据集D关于A的取值熵。增益率准则就可取值数目较少的属性有所偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
称为数据集D关于A的取值熵。增益率准则就可取值数目较少的属性有所偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
基尼指数(CART)
分类问题中,假设有个类,样本点属于
的概率
,则概率分布的基尼指数:
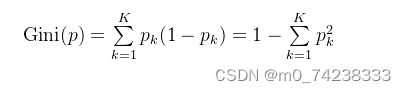
二分类问题: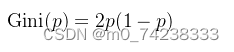
对给定的样本集合,基尼指数:
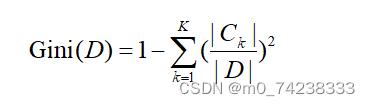
CART决策树使用“基尼指数”来选择划分属性。数据集的纯度可用基尼值来度量,
越小,则数据集的纯度越高。CART生成的是二叉树,计算量相对来说不是很大,可以处理连续和离散变量,能够对缺失值进行处理。
3.python实现
3.1 数据集
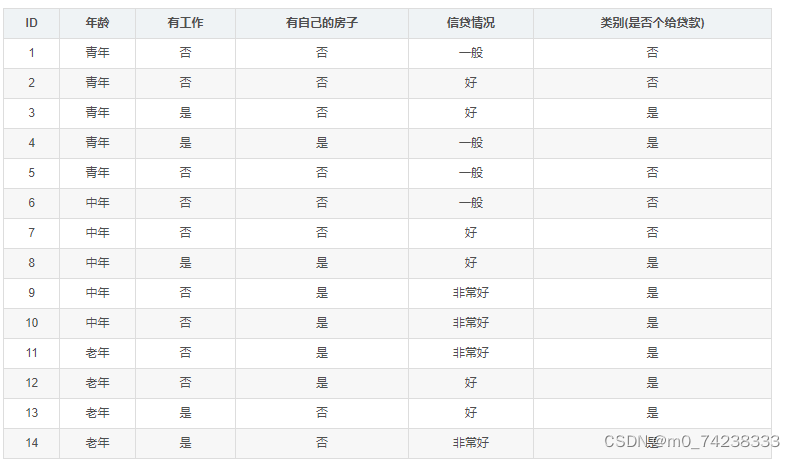
有四个特征:
年龄:青年0,中年1,老年2
工作:否0,是1
有自己的房子:否0,是1
信贷情况:一般0,好1,非常好2
# 创建测试数据集
def createDataSet():
dataSet = [[0, 0, 0, 0, 'no'], # 数据集
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
labels = ['年龄', '有工作', '有自己的房子', '信贷情况'] # 分类属性3.2 构建决策树
3.2.1 ID3算法
# 计算给定数据集的熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet) # 获得数据集的行数
labelCounts = {} # 用于保存每个标签出现次数的字典
for featVec in dataSet:
currentLabel = featVec[-1] # 提取标签信息
if currentLabel not in labelCounts.keys(): # 如果标签未放入统计次数的字典,则添加进去
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 # 标签计数
shannonEnt = 0.0 # 熵初始化
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries # 选择该标签的概率
shannonEnt -= prob * log(prob, 2) # 以2为底求对数
return shannonEnt # 返回经验熵
# 按照给定特征划分数据集
def splitDataSet(dataSet, axis, value): # dataSet:带划分数据集 axis:划分数据集的特征 value:需要返回的特征的值
retDataSet = [] # 创建新的list对象
for featVec in dataSet: # 遍历元素
if featVec[axis] == value: # 符合条件的,抽取出来
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis + 1:])
retDataSet.append(reducedFeatVec)
return retDataSet
# 选择最好的数据集划分方式 ID3算法——信息增益
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 # 特征数量
baseEntropy = calcShannonEnt(dataSet) # 计数数据集的香农熵
bestInfoGain = 0.0 # 信息增益
bestFeature = -1 # 最优特征的索引值
for i in range(numFeatures): # 遍历数据集的所有特征
featList = [example[i] for example in dataSet] # 获取dataSet的第i个所有特征
uniqueVals = set(featList) # 创建set集合{},元素不可重复
newEntropy = 0.0 # 信息熵
for value in uniqueVals: # 循环特征的值
subDataSet = splitDataSet(dataSet, i, value) # subDataSet划分后的子集
prob = len(subDataSet) / float(len(dataSet)) # 计算子集的概率
newEntropy += prob * calcShannonEnt((subDataSet))
infoGain = baseEntropy - newEntropy # 计算信息增益
print("第%d个特征的信息增益为%.3f" % (i, infoGain)) # 打印每个特征的信息增益
if (infoGain > bestInfoGain): # 计算信息增益
bestInfoGain = infoGain # 更新信息增益,找到最大的信息增益
bestFeature = i # 记录信息增益最大的特征的索引值
return bestFeature # 返回信息增益最大特征的索引值
# 统计出现次数最多的元素(类标签)
def majorityCnt(classList):
classCount = {} # 统计classList中每个类标签出现的次数
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True) # 根据字典的值降序排列
return sortedClassCount[0][0] # 返回出现次数最多的类标签
# 创建决策树
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet] # 取分类标签
if classList.count(classList[0]) == len(classList): # 如果类别完全相同,则停止继续划分
return classList[0]
if len(dataSet[0]) == 1: # 遍历完所有特征时返回出现次数最多的类标签
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet) # 选择最优特征
bestFeatLabel = labels[bestFeat] # 最优特征的标签
myTree = {bestFeatLabel: {}} # 根据最优特征的标签生成树
del (labels[bestFeat]) # 删除已经使用的特征标签
featValues = [example[bestFeat] for example in dataSet] # 得到训练集中所有最优特征的属性值
uniqueVals = set(featValues) # 去掉重复的属性值
for value in uniqueVals: # 遍历特征,创建决策树
subLabels = labels[:] # 复制所有标签,这样树就不会弄乱现有标签
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
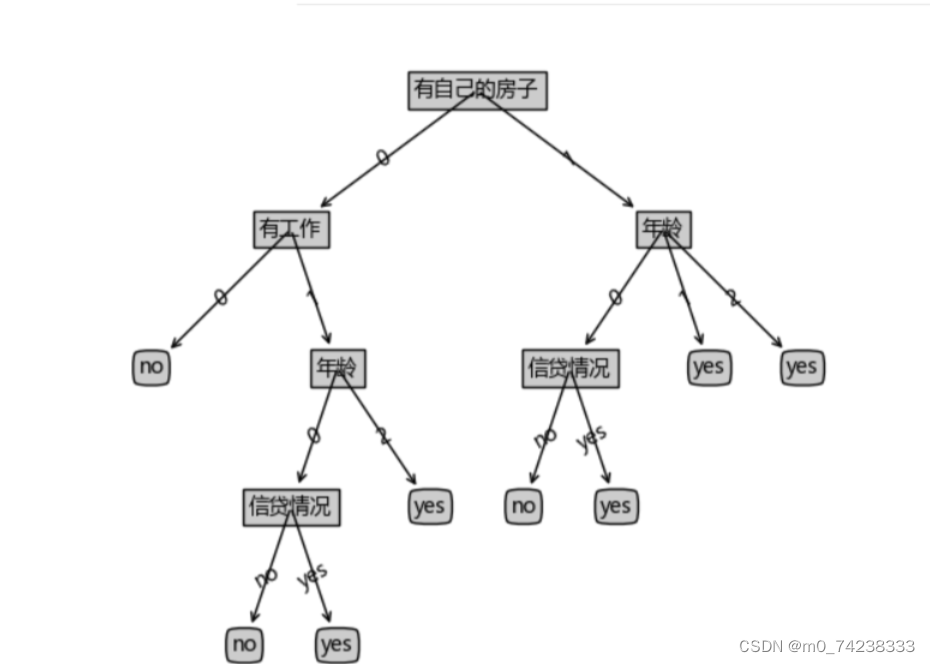
return myTree结果测试:
{'有自己的房子': {0: {'有工作': {0: 'no', 1: {'年龄': {0: {'信贷情况': {'no': 'no', 'yes': 'yes'}}, 2: 'yes'}}}}, 1: {'年龄': {0: {'信贷情况': {'no': 'no', 'yes': 'yes'}}, 1: 'yes', 2: 'yes'}}}}
3.2.2 CART算法
# 计算概率
def calcProbabilityEnt(dataSet):
numEntries = len(dataSet) # 数据集大小
feaCounts = 0 # 特征数量
feature = dataSet[0][len(dataSet[0]) - 1]
for feaVec in dataSet:
if feaVec[-1] == feature:
feaCounts += 1
probabilityEnt = float(feaCounts) / numEntries #概率= 特征数量/数据集大小
return probabilityEnt
# 选择最好的数据集划分方式 CAR算法——基尼指数
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #特征数量
if numFeatures == 1:
return 0
bestGini = 1 #最佳基尼指数
bestFeature = -1 #最优的划分特征,初始化为-1
for i in range(numFeatures): # 遍历所有的特征
featList = [example[i] for example in dataSet]
feaGini = 0 # 定义特征的值的基尼系数
uniqueVals = set(featList) #获取该特征下的所有不同的值
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value) #划分数据集
prob = len(subDataSet) / float(len(dataSet))
probabilityEnt = calcProbabilityEnt(subDataSet)
feaGini += prob * (2 * probabilityEnt * (1 - probabilityEnt))
if (feaGini < bestGini):
bestGini = feaGini #基尼指数
bestFeature = i #记录基尼指数最小的索引值
return bestFeature
结果测试:
{'有自己的房子': {0: {'有工作': {0: 'no', 1: {'年龄': {0: {'信贷情况': {1: 'yes'}}, 2: 'yes'}}}}, 1: {'年龄': {0: {'有工作': {1: {'信贷情况': {0: 'yes'}}}}, 1: 'yes', 2: 'yes'}}}} 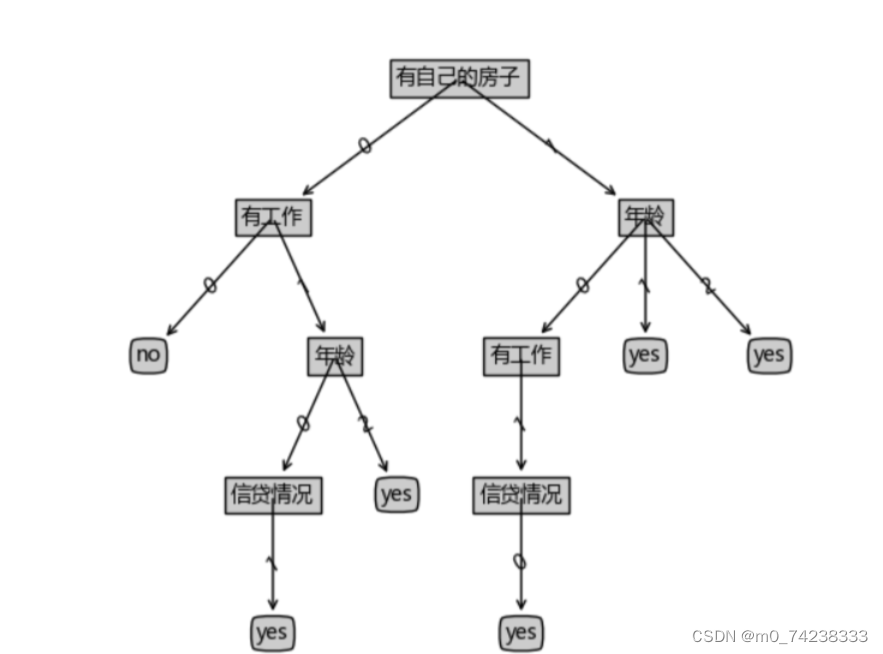
4.总结
ID3算法:ID3算法核心就是“最大信息熵增益” 原则选择划分当前数据集的最好特征。而且对于连续型特征,比如长度,密度都是连续值,无法在ID3运用,利用信息熵划分属性,会对倾向于可取值数目较多的属性。没有考虑过拟合的问题。
CART算法:CART算法使用基尼系数来代替信息增益比,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。这和信息增益及信息增益率是相反的。















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









