






1. 概述
贝叶斯公式又被称为贝叶斯规则,是概率统计中的应用所观察到的现象对有关概率分布的主观判断(先验概率)进行修正的标准方法。用数学语言表达就是:支持某项属性的事件发生得愈多,则该属性成立的可能性就愈大。
1.1 公式
贝叶斯公式便是基于条件概率,通过P(B|A)来求P(A|B),如下:
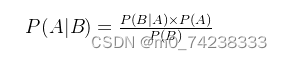
将A看成“规律”,B看成“现象”,那么贝叶斯公式看成:

1.2 先验概率和后验概率
先验概率:即基于统计的概率,是基于以往历史经验和分析得到的结果,不需要依赖当前发生的条件。
后验概率:则是从条件概率而来,由因推果,是基于当下发生了事件之后计算的概率,依赖于当前发生的条件。
1.3 拉普拉斯平滑
在计算条件概率时,由于某个特征在某个分类中可能没有出现,因此该特征在该分类中的条件概率可能为 0。此时,当我们尝试计算某个文档可能属于哪个分类时,我们会因为概率计算出错而得到错误的结果。
拉普拉斯平滑是一种解决这个问题的方法。基本思想是为某个分类和某个特征分配一个小的数量,这样可以避免条件概率为 0。
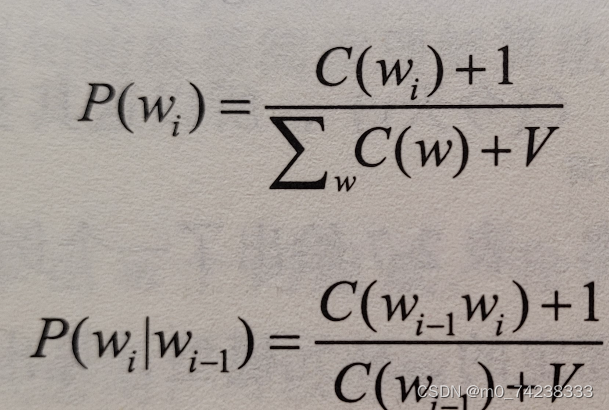
Wi:第i个单词P(Wi):第i个单词出现的概率C(Wi):第i个单词在文本中出现的次数C(Wi-1 Wi):Wi和Wi-1在文本中同时出现的次数V:特征值的个数∑wC(w):所有数据集的个数
2. 案例实现——垃圾邮件分类
2.1 数据集说明
准备非垃圾邮件ham和垃圾邮件spam各25封,测试邮件5封,其中把spam中的1、2和ham中的22、23、24拿出来当测试集
ham第11封:

spam第11封:
test文件:

2.2 代码实现
导包:
import os
import re
import string
import math
import numpy as np
数据预处理(转换小写、字符串,过滤符号和数字):
def get_filtered_str(category):
email_list = []
translator = re.compile('[%s]' % re.escape(string.punctuation))
for curDir, dirs, files in os.walk(f'./email/{category}'):
for file in files:
file_name = os.path.join(curDir, file)
with open(file_name, 'r', encoding='utf-8') as f:
txt_str = f.read()
txt_str = txt_str.lower()
txt_str = translator.sub(' ', txt_str)
txt_str = replace_num(txt_str)
txt_str_list = txt_str.splitlines()
txt_str = ''.join(txt_str_list)
# print(txt_str)
email_list.append(txt_str)
return email_list
数据处理阶段:
计算垃圾词出现的概率:
def get_dict_spam_dict_w(spam_email_list):
all_email_words = []
word_set = set()
for email_str in spam_email_list:
email_words = email_str.split(' ')
all_email_words.append(email_words)
for word in email_words:
if(word!=''):
word_set.add(word)
word_dict = {}
for word in word_set
word_dict[word] = 0
for email_words in all_email_words:
for email_word in email_words:
if(word==email_word):
word_dict[word] += 1
break
return word_dict
遍历邮件是否有垃圾词:
def get_dict_ham_dict_w(spam_email_list,ham_email_list):
all_ham_email_words = []
word_set = set()
for email_str in spam_email_list:
email_words = email_str.split(' ')
for word in email_words:
if (word != ''):
word_set.add(word)
for ham_email_str in ham_email_list:
ham_email_words = ham_email_str.split(' ')
all_ham_email_words.append(ham_email_words)
word_dict = {}
for word in word_set:
word_dict[word] = 0
for email_words in all_ham_email_words:
for email_word in email_words:
if(word==email_word):
word_dict[word] += 1
break
return word_dict
获取test邮件中出现的垃圾邮件特征:
def get_X_c1(spam_w_dict,file_name):
translator = re.compile('[%s]' % re.escape(string.punctuation))
with open(file_name, 'r', encoding='utf-8') as f:
txt_str = f.read()
txt_str = txt_str.lower()
txt_str = translator.sub(' ', txt_str)
txt_str = replace_num(txt_str)
txt_str_list = txt_str.splitlines()
txt_str = ''.join(txt_str_list)
email_words = txt_str.split(' ')
x_set = set()
for word in email_words:
if word!='':
x_set.add(word)
spam_len = len(os.listdir(f'./email/spam'))
spam_X_num = []
for xi in x_set:
for wi in spam_w_dict:
if xi == wi:
spam_X_num.append(spam_w_dict[wi])
w_appear_sum_num = 1
for num in spam_X_num:
w_appear_sum_num += num
w_c1_p = w_appear_sum_num / (spam_len + 2)
return w_c1_p获取test邮件中出现的非垃圾邮件特征:
def get_X_c2(ham_w_dict,file_name):
# 过滤文本
translator = re.compile('[%s]' % re.escape(string.punctuation))
with open(file_name, 'r', encoding='utf-8') as f:
txt_str = f.read()
txt_str = txt_str.lower()
txt_str = translator.sub(' ', txt_str)
txt_str = replace_num(txt_str)
txt_str_list = txt_str.splitlines()
txt_str = ''.join(txt_str_list)
email_words = txt_str.split(' ')
x_set = set()
for word in email_words:
if word!='':
x_set.add(word)
ham_X_num = []
for xi in x_set:
for wi in ham_w_dict:
if xi == wi:
ham_X_num.append(ham_w_dict[wi])
ham_len = len(os.listdir(f'./email/ham'))
w_appear_sum_num = 1
for num in ham_X_num:
w_appear_sum_num += num
w_c2_p = w_appear_sum_num / (ham_len+2)
return w_c2_p测试阶段:
def email_test(spam_w_dict,ham_w_dict):
for curDir, dirs, files in os.walk(f'./email/test'):
for file in files:
file_name = os.path.join(curDir, file)
print('---------------------------------------------------------------')
print(f'测试邮件: {file}')
# 获取条件概率 p(X|c1)
p_X_c1 = get_X_c1(spam_w_dict,file_name)
# 获取条件概率 p(X|c2)
p_X_c2 = get_X_c2(ham_w_dict,file_name)
# print(f'\nX_c1={p_X_c1}')
# print(f'\nX_c2={p_X_c2}')
# #注意:Log之后全部变为负数
A = np.log(p_X_c1) + np.log(1 / 2)
B = np.log(p_X_c2) + np.log(1 / 2)
# 除法会出现问题,-1 / 负分母 结果 < -2/同一个分母
print(f'p1={A},p2={B}')
# 因为分母一致,所以只比较 分子即可
if A > B:
print('p1>p2,所以是垃圾邮件.')
if A <= B:
print('p1<p2,所以是正常邮件.')
测试结果:
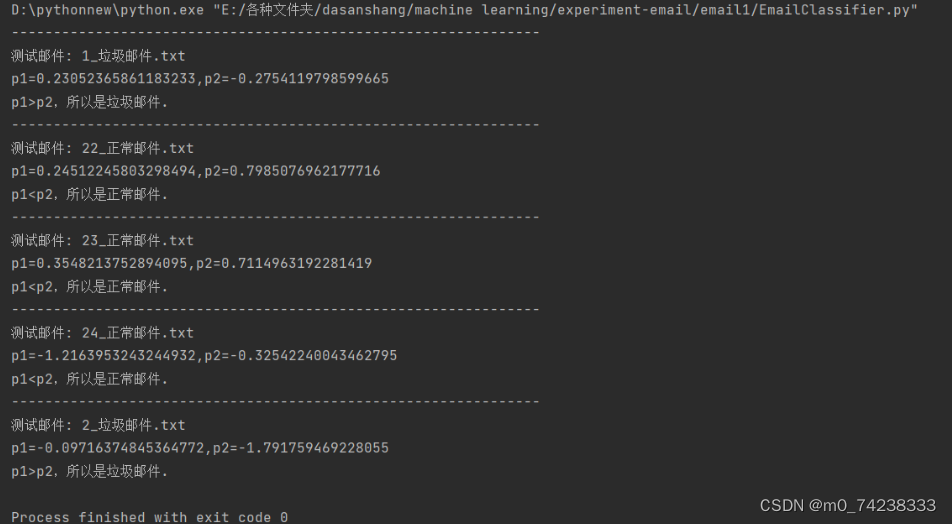
分析:分类器通过训练集学习了垃圾邮件和非垃圾邮件的特征,而后在测试集中提取其特征并计算其属于垃圾邮件和非垃圾邮件的后验概率,选择后验概率较大的类别作为分类结果。
3. 总结
朴素贝叶斯算法分析
优点:
(1)朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
(2)对小规模的数据表现很好,能个处理多分类任务,适合增量式训练,尤其是数据量超出内存时,我们可以一批批的去增量训练。
(3)对缺失数据不太敏感,算法也比较简单,常用于文本分类。
缺点:
(1)理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型给定输出类别的情况下,假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
(2)需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
(3)由于我们是通过先验和数据来决定后验的概率从而决定分类,所以分类决策存在一定的错误率。
(4)对输入数据的表达形式很敏感。















 4015
4015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









