






1. logistic回归概述
1.1 算法概述
逻辑回归(Logistic Regression)是机器学习中的一种分类模型,逻辑回归是一种分类算法,该算法的目的是预测二元输出变量(比如0或1),逻辑回归算法广泛运用于预测股票市场,顾客购买行为,诊断疾病等等。虽然名字中带有回归,但却是一种分类算法。
1.2 算法原理
要想掌握逻辑回归,必须掌握两点:
- 逻辑回归中,其输入值是什么
- 如何判断逻辑回归的输出
输入: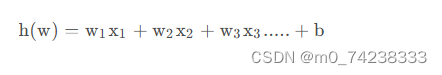
逻辑回归的输入就是一个线性回归的结果。
激活函数:sigmoid函数: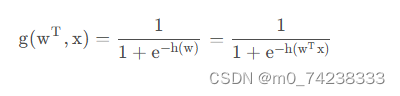
-
判断标准
- 回归的结果输入到sigmoid函数当中
- 输出结果:[0, 1]区间中的一个概率值,默认为0.5为阈值
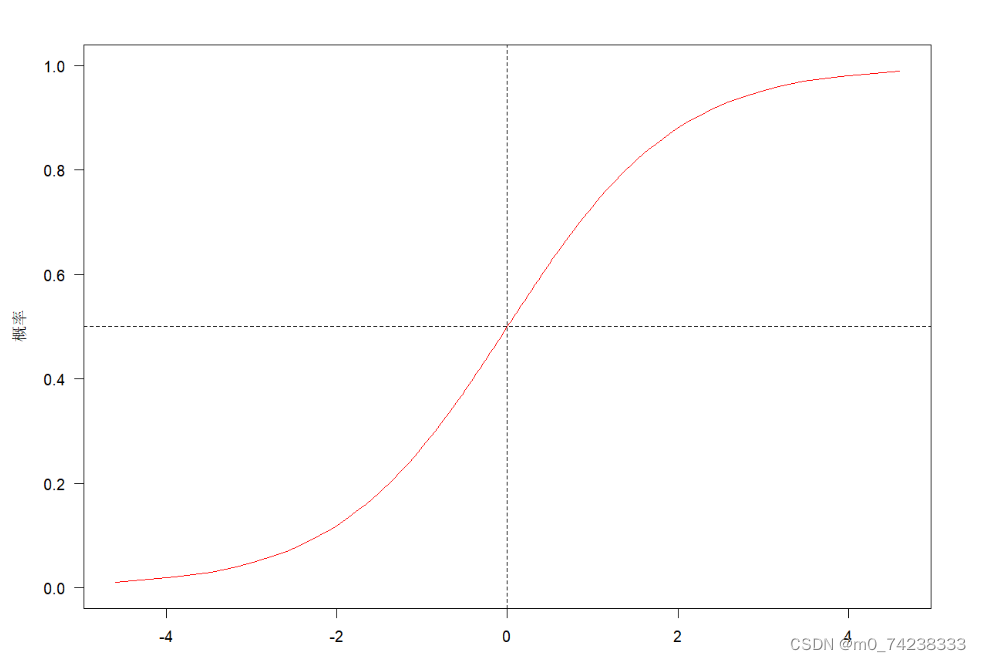
1.3 最小二乘
最小二乘法是一种用于估计未知参数的方法,它通过最小化数据点与拟合曲线之间的平方和来找到最佳的拟合模型。在多元线性回归中,我们试图找到一条直线,使得数据点与这条直线之间的平方和最小。
用于计算回归预测值与真实值的误差,公式表示为: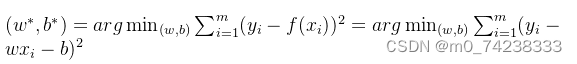
1.4 梯度上升
在机器学习中,梯度上升法常用于求解最大似然估计问题或对数似然函数的最大化问题。其基本思想是通过迭代的方式更新参数,使得目标函数值不断增大,直到达到最大值或收敛。
具体步骤如下:
- 初始化待优化的参数向量。
- 计算目标函数关于参数向量的梯度。
- 根据梯度的方向和步长大小,更新参数向量。通常采用梯度乘以一个学习率的方式进行更新。
- 重复步骤2和步骤3,直到满足终止条件(如达到最大迭代次数或梯度变化很小)
2. 代码实现
2.1 数据集
原始数据集下载网址:https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/
2.2 具体流程
读取数据
需要注意的是数据和列明分开了,因此在进行读取的时候,要一块读取。
import pandas as pd
import numpy as np
# 1.读取数据
path = "breast-cancer-wisconsin.data"
column_name = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']
data = pd.read_csv(path, names=column_name)
# print(data)缺失值处理
# 2、缺失值处理
# 1)替换-》np.nan
data = data.replace(to_replace="?", value=np.nan)
# 2)删除缺失样本
data.dropna(inplace=True)划分数据集
# 3、划分数据集
from sklearn.model_selection import train_test_split
# 筛选特征值和目标值
x = data.iloc[:, 1:-1]
y = data["Class"]
x_train, x_test, y_train, y_test = train_test_split(x, y)标准化
把原始数据转化到均值为0,标准差为1的范围内
# 4、标准化
from sklearn.preprocessing import StandardScaler
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)预估器流程
from sklearn.linear_model import LogisticRegression
# 5、预估器流程
estimator = LogisticRegression()
estimator.fit(x_train, y_train)
# 逻辑回归的模型参数:回归系数和偏置
# estimator.coef_
# estimator.intercept_模型评估
# 6、模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)2.3 结果展示
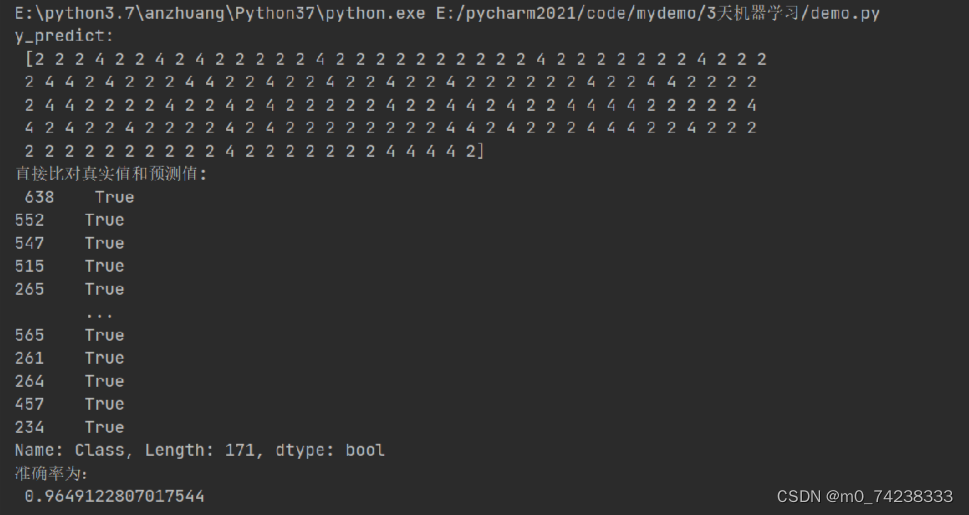
结果分析:错误率较低,因为数据集本身较大,且使用的是梯度上升算法。
3 总结
优点:
(1)训练速度较快,分类的时候,计算量仅仅只和特征的数目相关;
(2)简单易理解,模型的可解释性非常好,从特征的权重可以看到不同的特征对最后结果的影响;
(3)适合二分类问题,不需要缩放输入特征;
(4)内存资源占用小,因为只需要存储各个维度的特征值;
缺点:
(1)不能用Logistic回归去解决非线性问题,因为Logistic的决策面试线性的;
(2)对多重共线性数据较为敏感;
(3)很难处理数据不平衡的问题;
(4)准确率并不是很高,因为形式非常的简单(非常类似线性模型),很难去拟合数据的真实分布;
(5)逻辑回归本身无法筛选特征,有时会用gbdt来筛选特征,然后再上逻辑回归

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









